Xuan Wu
> 针对不同的语言,需要重写对应的解析器,不是简单替换关键词就能做到的。 的确,还有额外的相关辅助功能如IDE的中文补全提示(Intellij系有 [此插件辅助标识符补全](https://github.com/tuchg/ChinesePinyin-CodeCompletionHelper))。在编程母语化的趋势下(如 [“抚子”日语编程语言已进入中学教学](https://www.zhihu.com/question/510639541/answer/2304467718)),个人看来不失为前瞻性的~~技术~~设计探索。 另外,关于编译器会反馈哪些报错信息,不知有文档介绍吗?
供参考:[开发中文 API 的一些策略](https://zhuanlan.zhihu.com/p/93495675)
请问有没有一些日常/重复进行的操作, 有进行自动化的价值/可行性? 或者, 基于[现有框架](https://zhuanlan.zhihu.com/p/53641620), 从常用设备&操作开始实现?
嗯,不知有没有可能提取出一部分比较稳定、易于测试又有普遍适用意义的功能...
个人仅在维护 [木兰重现项目](https://gitee.com/MulanRevive/mulan-rework),与原作者团队无联系。渊源请见首页前言部分。
在rider 2022.1.1 试用版测试,未装插件的补全效果: 安装后的效果 :
@liuyike233 关于排序,在 1.6 下测,似乎与命名有关,”按钮“有同样问题:  但改为”按键“就好了: 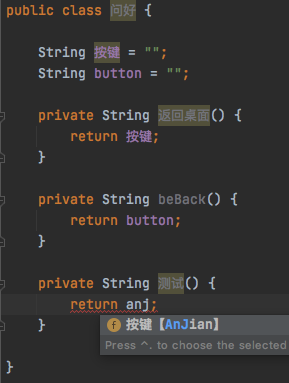
@KindRoach 支持,同功能的 [vsc 插件](https://gitee.com/Program-in-Chinese/vscode_Chinese_Input_Assistant)已用了中文命名。之前尝试过[中文化 vue 源码](https://zhuanlan.zhihu.com/p/50726829),一些个人建议: - 中文化过程中确保自动测试通过(看到[这里](https://github.com/tuchg/ChinesePinyin-CodeCompletionHelper/tree/master/src/test/kotlin)一个测试用例文件) - 可以按类、API、枚举、局部变量等”自大向小“的顺序逐步中文化,也方便理解整体逻辑 - 可分为多个 commit,如发现问题方便定位 - 一些带中文注释的标识符可以参考注释进行命名,如“笛卡尔积缓存”: https://github.com/tuchg/ChinesePinyin-CodeCompletionHelper/blob/cc47d7876499f45142817c79ca3c4ae541cfe89e/src/main/kotlin/com/github/tuchg/nonasciicodecompletionhelper/utils/PinyinEx.kt#L18
从源码本地运行,在PhpStorm下问题可复现: Java没问题: 好像改回上一版本的 ChinesePrefixMatcher.kt 也有相同问题。也许与 #37 有相同原因?
有幸遇到一位例程使用中文标识符的热门python教程作者([孙兴华《中文讲Python从入门到办公自动化》](https://www.bilibili.com/video/BV1gt4y1D7W8?p=1&share_medium=android&share_plat=android&share_source=COPY&share_tag=s_i×tamp=1623799509&unique_k=eMxjUR)),交流时也有此需求: 