weibo-crawler
 weibo-crawler copied to clipboard
weibo-crawler copied to clipboard
新浪微博爬虫,用python爬取新浪微博数据,并下载微博图片和微博视频

如题。已经尝试过抓取不同类型的账号:政府或非政府背景的媒体(新华网,凤凰网、天涯社区等等)、普通微博大V(下厨房,原图妈),最后均停在200页左右然后便自动结束爬取,并显示“信息抓取完毕”。没有任何报错。(ps: 迪丽热巴目前一共只有一百三十多页的微博,所以能全部抓完。)
因不太熟悉python,不好直接改代码。所以提个建议。 发现一个优化点,当配置只爬取原创,过滤转发微博时,在获取微博内容时,可以直接忽略转发的微博,而不是在获取微博信息后根据是否过滤再忽略,毕竟主要花时间的地方是在获取信息上,特别是微博是长微博时效率更明显。
小白求助. 数据库MySQL部署好了, 用SQlite抓取评论,显示已下载,能看到user和weibo,但是没找到评论在哪里2333 求解答, 不胜感谢~
虽然terminal (MacOS Mojave) 中能实时看到爬取的微博,all.log也会相应更新,但自动生成的weibo文件夹中只有user.csv一个文件,并没有自动生成以用户名/id命名的文件夹,也没有保存微博内容的csv文件(试过json也不行)。 config.json设置如下,几乎没作什么改变: { "user_id_list": ["1669879400"], "filter": 0, "remove_html_tag": 1, "since_date": "2018-01-01", "start_page": 1, "write_mode": ["csv"], "original_pic_download": 1, "retweet_pic_download": 0, "original_video_download": 0, "retweet_video_download": 0, "download_comment":1, "comment_max_download_count":100, "result_dir_name": 0...
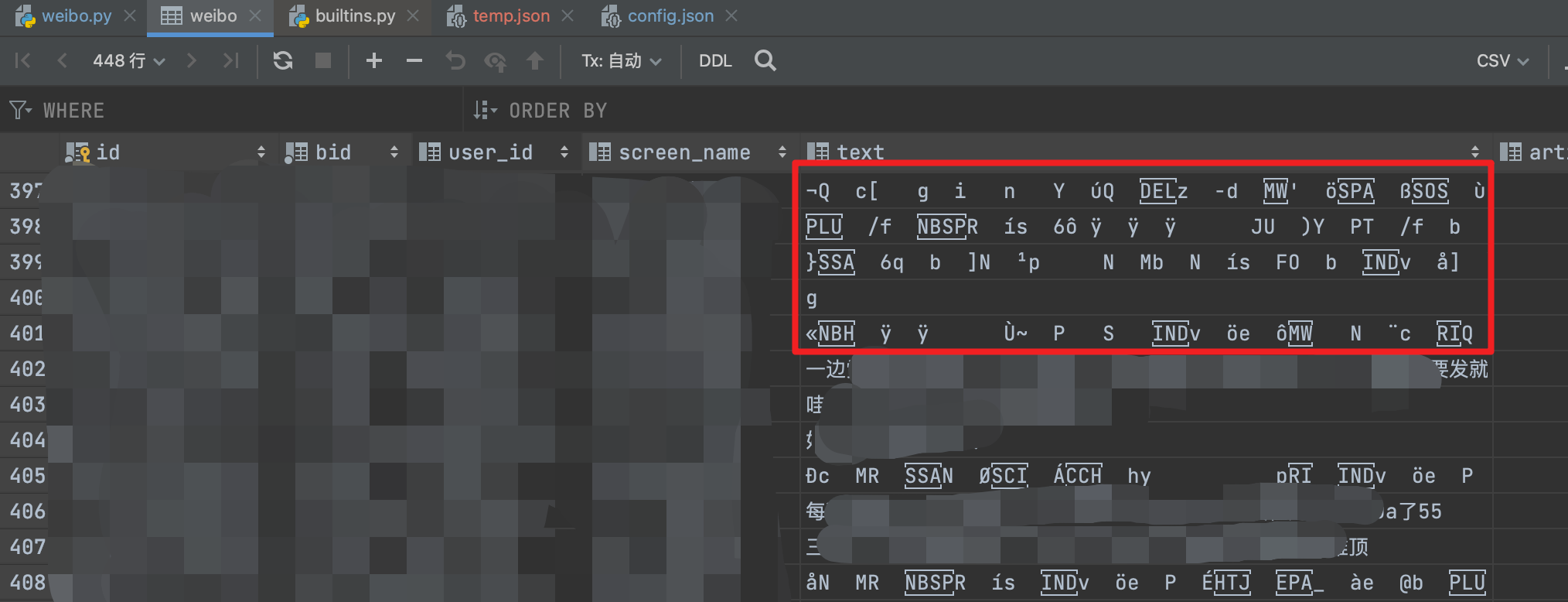 有部分微博文字内容会抓到乱码,找了一下原因。 只要微博内带表情,返回的表情格式是表情的图片icon,会导致html解析出错。   具体定位是**weibo.py代码第641行** 解决办法: 1.作者在配置里已经提供了是否要移除html标签,只要把config.json里的第六行 remove_html_tag 设置为 0。 微博内容至少不会乱码,不过会包含标签的表情。 2.重新写一下**weibo.py代码第643行**的selector.xpath('string(.)'),可以解析出中的alt属性以文字代替图片。因为哪怕有span标签对我也没影响,所以我没写。
我将爬取列表的配置文件命名为user_id_list.txt,放在脚本的同级目录下,在配置文件中使用C:\\Users\\PC\\Downloads\\weibo-crawler-master和C:/Users/PC/Downloads/weibo-crawler-master以及user_id_list.txt均未能成功爬取,报错为提示被ban。以下是配置文件列表,我参照的是文档中7.定期自动爬取微博(可选)说明 { "user_id_list": ["C:\Users\PC\Downloads\weibo-crawler-master"], "filter": 1, "remove_html_tag": 1, "since_date": "2010-01-01", "start_page": 1, "write_mode": ["csv"], "original_pic_download": 1, "retweet_pic_download": 0, "original_video_download": 1, "retweet_video_download": 0, "download_comment":1, "comment_max_download_count":100, "result_dir_name": 0, "cookie": "", "mysql_config": {...
我一共需要爬取14条微博的评论,然后只有少数几条不报“未能抓取评论”。具体情况是首先该条会显示“正在下载评论”,然后就会显示同一条“未能抓取评论”。我已经设置cookie了,想问下作者大大可能的解决方案?
现在的id好像都是按int类型进行存储的,但是微博的id位数很长(我自己爬的过程中,有些微博的id是16位),如果直接存到csv/excel中去,由于这俩对整数位最高只支持15位,会导致id的最后一位直接变成0。建议爬下来之后转为str类型,或者考虑其他解决办法。 我当前如果要得到id正确的csv文件,需要先存到db,然后导出成txt,在从txt将数据导入excel/csv,并将对应的数据列选定为文本。