weibo-crawler
 weibo-crawler copied to clipboard
weibo-crawler copied to clipboard
新浪微博爬虫,用python爬取新浪微博数据,并下载微博图片和微博视频
 这个接口是怎么来的呢,我用谷歌进https://m.weibo.cn/u/USERID用F12调试没找到,想请教一下
在浏览器里打卡大于200的page,显示也是空的,已经登录了 
出现json报错

 出现如图所示报错,查找说是json数据格式应为双引号,由于对爬取内容格式不太清除,应该如何更改呢?
无法安装依赖
我是MacOS High Sierra 10.13.6,但无法安装依赖,显示: chbdeMBP:weibo-crawler-master Mark$ pip install -r requirements.txt Traceback (most recent call last): File "/usr/local/bin/pip", line 9, in load_entry_point('pip==21.0.1', 'console_scripts', 'pip')() File "/System/Library/Frameworks/Python.framework/Versions/2.7/Extras/lib/python/pkg_resources/__init__.py", line 565, in load_entry_point return...
错误
weibo.py", line 21, in import requests ModuleNotFoundError: No module named 'requests' 这个错误怎么解决
list index out of range Traceback (most recent call last): File "D:\weibo-crawler\weibo.py", line 1606, in get_pages if (self.get_user_info() != 0): File "D:\weibo-crawler\weibo.py", line 335, in get_user_info self.user_to_database() File "D:\weibo-crawler\weibo.py", line...
2022-05-11 20:32:13,262 - ERROR - weibo.py[:752] - Extra data: line 112 column 2 (char 5454) Traceback (most recent call last): File "weibo.py", line 743, in get_one_weibo weibo = self.get_long_weibo(weibo_id) File...
 已写入cookie chu'ci除此之外,还出现另外一个错误 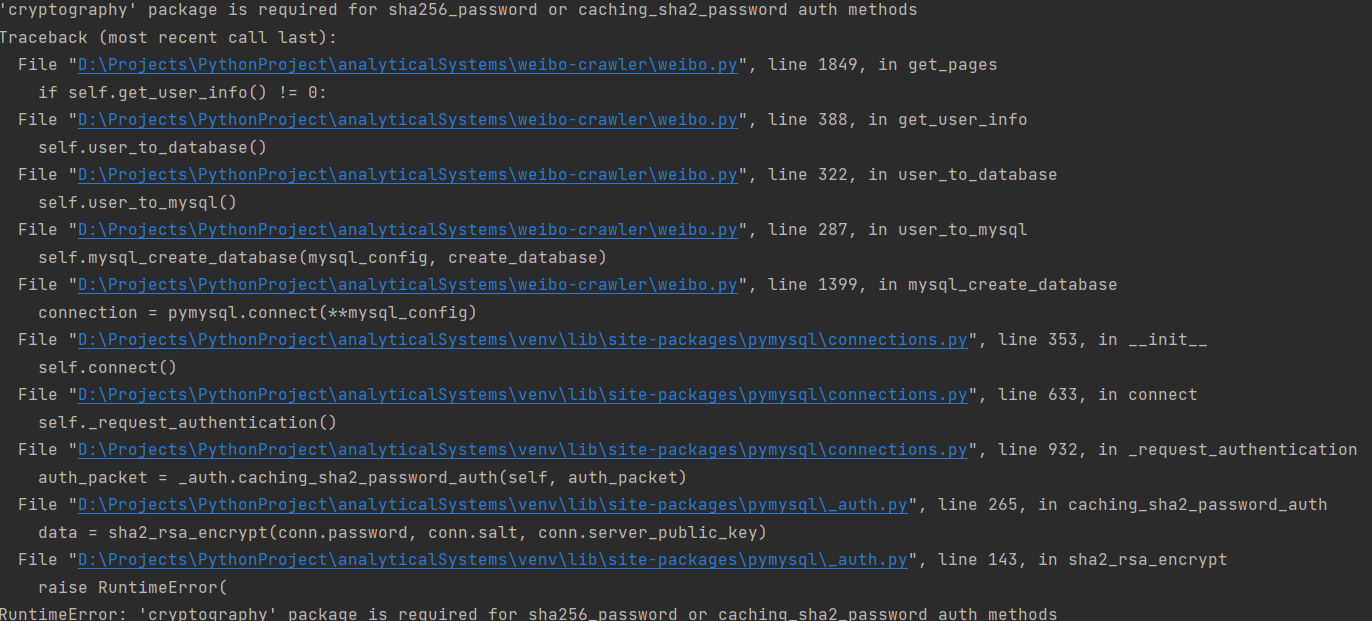 请问这个如何解决呢