weibo-crawler
 weibo-crawler copied to clipboard
weibo-crawler copied to clipboard
新浪微博爬虫,用python爬取新浪微博数据,并下载微博图片和微博视频

读取user_id_list 文本中日期问题 如果只间隔一天的话,有的能读取微博更新,有的不能(但全部读是没问题的),不知道什么原因 user_id_list 文本中日期为2022-04-17 ,今天是2022-04-18,而且微博有更新,有的读得出,有的读不出
抓取的uid 5044429589(填了cookie) ,抓的excel里头条文章url都是空的,不知道什么问题? 
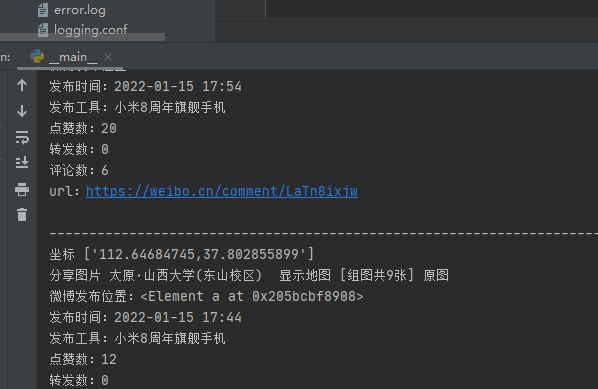
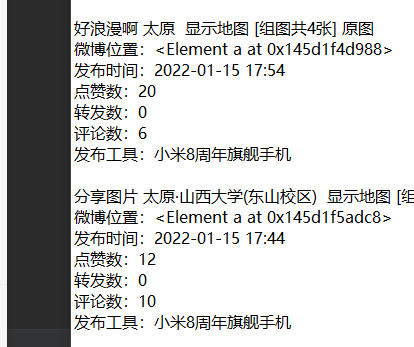
 bao'cbaocuo1内容如上图 内容写入user表中正确,但微博内容写入weibo表中错误,当前mysql数据库中weibo表为空  请问这种情况该如何解决?
2022-04-06 16:38:54,226 - ERROR - weibo.py[:1621] - list index out of range Traceback (most recent call last): File "weibo.py", line 1585, in get_pages if(self.get_user_info() != 0): File "weibo.py", line 334,...
大佬你好!我想请教你一个问题,爬新浪微博数据时,像下边的错误是什么原因呢? 
您好~我的程序在运行了两天没有问题后,突然程序报错,获取不到所有用户页下的微博内容。 应该不是封号,使用了ip池并且换了多次小号仍然报错。 【最初报错】 ------------------------------已获取寰亚SYHP(5393135816)的第1页微博------------------------------ Traceback (most recent call last): File "E:/code/微博爬虫/weibo评论用户信息爬取/weibo.py", line 747, in get_one_weibo is_long = True if weibo_info.get('pic_num') > 9 else weibo_info.get('isLongText') TypeError: '>' not supported between instances...