weibo-crawler
 weibo-crawler copied to clipboard
weibo-crawler copied to clipboard
新浪微博爬虫,用python爬取新浪微博数据,并下载微博图片和微博视频
这个程序sqlite保存的功能是最完善的,但我尝试了几款市面上的sqlite查看工具,查看微博效果并不理想。 想问一下大家平时都如何查看sqlite保存的微博?有没有好的工具? 如果没有工具,我可以用flask做个简单的后端,但前端vue vite什么的已经不熟悉了,有人愿意练手做一个吗? 或者有什么更简单的技术实现方案吗?
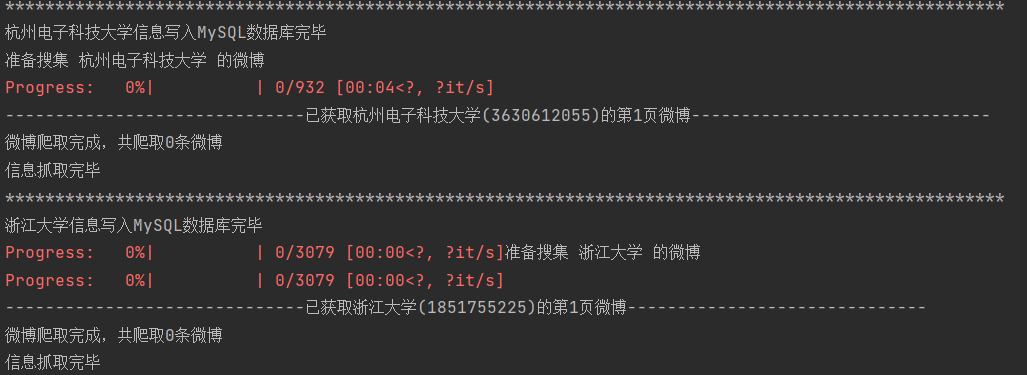 
报错,但能执行。

Extra data: line 128 column 2 (char 4697) Traceback (most recent call last): File "weibo.py", line 766, in get_one_weibo weibo = self.get_long_weibo(weibo_id) File "weibo.py", line 351, in get_long_weibo js =...
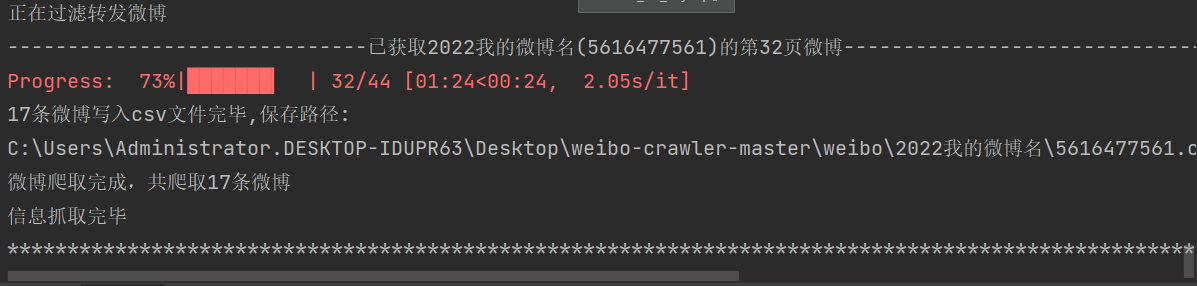
大侠,爬起的微博是记录在原来记录后面的(csv文件),可不可以插在原记录的上面,这样看起来就方便了,免得要翻到最后才能看到新爬的记录
query_list设置为""时可以爬取相应用户微博,但是根据用户微博关键词重新设置query_list爬取后却无法抓到相应微博,请问是遇到了什么问题
 增加缺少字段full_created_at后(只修改过这一处),删除原weibo表,重新运行程序,出现以下报错 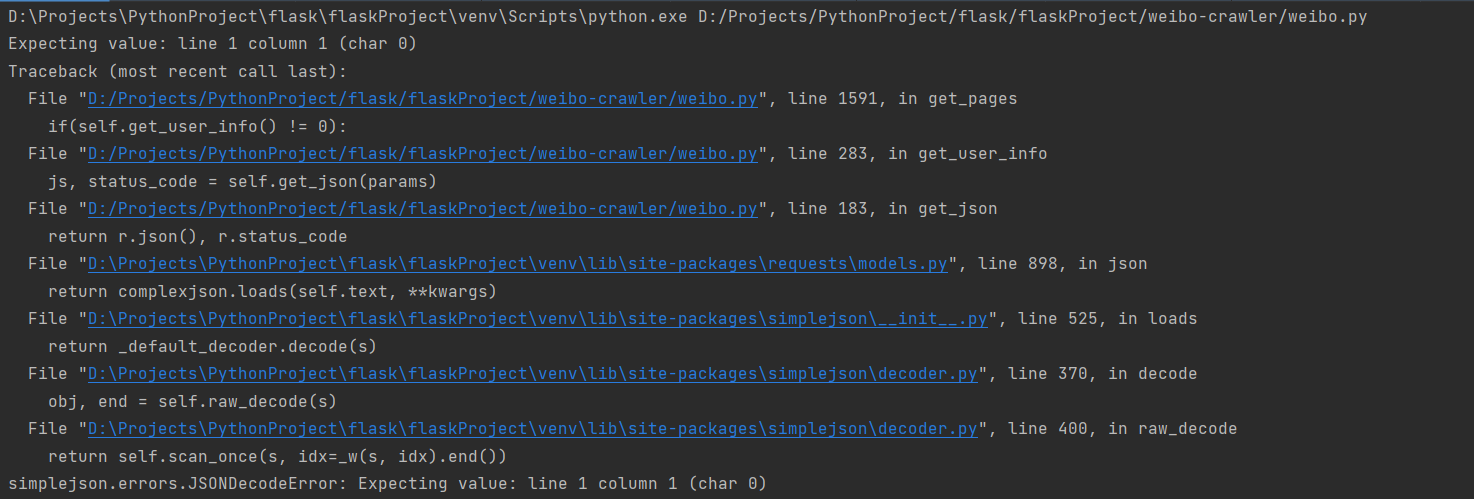 但可喜的是,可以正常爬取数据存入到数据库中了