weibo-crawler
 weibo-crawler copied to clipboard
weibo-crawler copied to clipboard
Published
20 hours ago •
 dataabc
dataabc
部分微博文字内容会抓到乱码 已找到原因
trafficstars
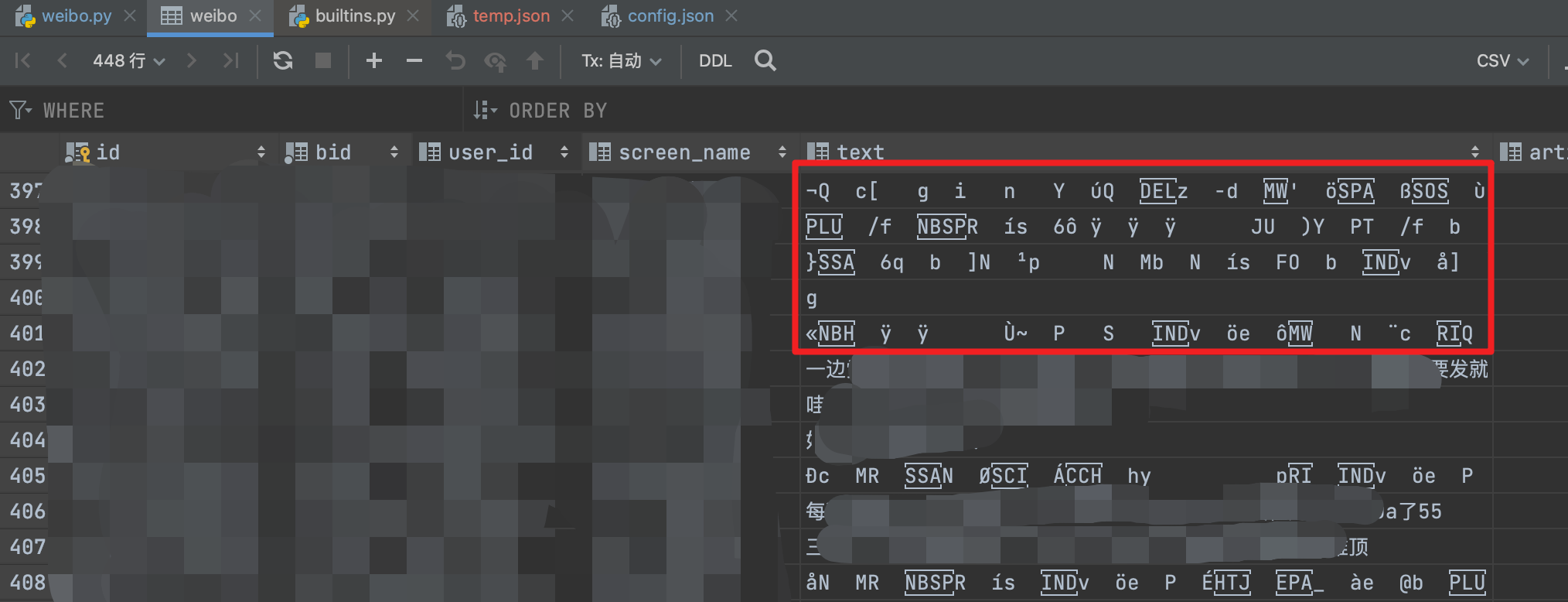
有部分微博文字内容会抓到乱码,找了一下原因。
只要微博内带表情,返回的表情格式是表情的图片icon,会导致html解析出错。


具体定位是weibo.py代码第641行
解决办法:
1.作者在配置里已经提供了是否要移除html标签,只要把config.json里的第六行 remove_html_tag 设置为 0。 微博内容至少不会乱码,不过会包含标签的表情。
2.重新写一下weibo.py代码第643行的selector.xpath('string(.)'),可以解析出中的alt属性以文字代替图片。因为哪怕有span标签对我也没影响,所以我没写。
感谢反馈。
您的意思是遇到表情符,可以替换成对应的alt文字吗?如果方便,能否以pull request的方式提交修改呢,如果没问题,您会成为Contributor,感谢。
感谢反馈。
您的意思是遇到表情符,可以替换成对应的alt文字吗?如果方便,能否以pull request的方式提交修改呢,如果没问题,您会成为Contributor,感谢。
是的,现在的微博数据接口遇到表情符是返回〈span〉〈img〉〈/span〉的形式。但是用etree.HTML()似乎不能正确解析成HTML结构,导致后续xpath也无法提取。所以我直接在config关闭了removeHtml功能
具体原因我还在排查,不知道其他人会不会也遇到这样的问题。后续我试试把表情符里的alt提取出来,这样会方便阅读很多。