Hüseyin Tuğrul BÜYÜKIŞIK
![]()
![]()
![]()
Hüseyin Tuğrul BÜYÜKIŞIK

I'm adding some multi-gpu stuff into it to use all GPUs for single drive. It works but it is slow because of multiple lock-guards and small paging size in the...
For example, I have an OpenCL-based VRAM virtual-array class that improves performance even for random-accesses even when the accesses are not in too big chunks: https://github.com/tugrul512bit/VirtualMultiArray/wiki/Cache-Hit-Ratio-Benchmark 64-threads access: 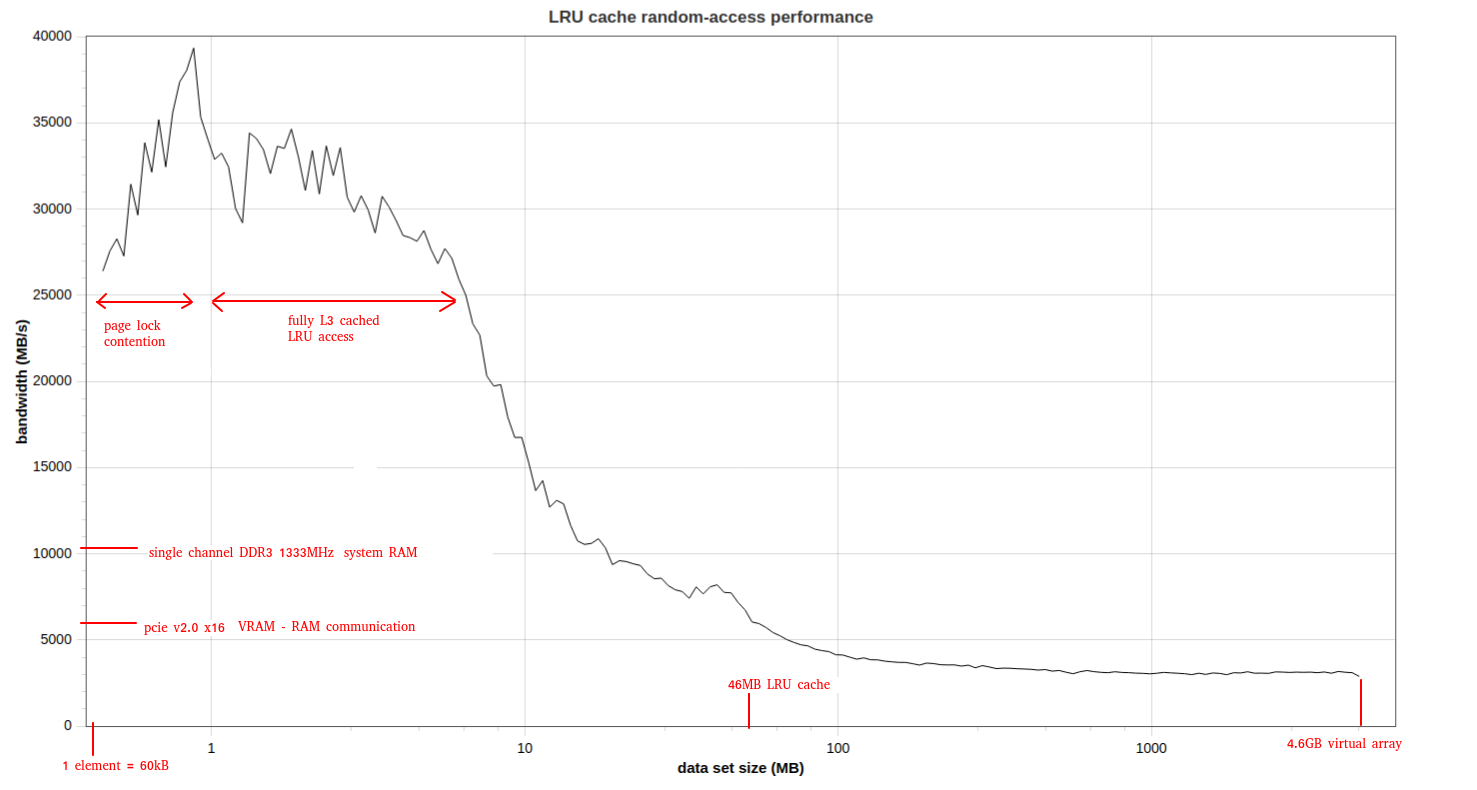 Single-thread...
Cuda version: https://i.snipboard.io/kUT6v8.jpg I tried all 3 options from dropdown menu and all used the GT1030. Is there a way to specify devices explicitly before running or just by using...
Sometimes a kernel needs to be repeated such as a "fluid solver" with same global+local range values.
such as a 3 stage pipeline result: pipeline 1: 3ms, %25 overlapped pipeline 2: 1ms, totally hidden pipeline 3: 20ms, %8 overlapped total overlapping regions: %15 time saved: 2ms (will...
this way, binding only necessary arrays to a kernel will be possible, instead of all arrays
Then developers can have any order they want instead of just: __kernel void test(input1,input2,hidden1,hidden2,hidden3,output1,output2){} instead of using inputs+hiddens+outputs differently in the parameter building part, add all into a single array...
Moving kernel names from one stage to another to altering total latencies of stages to minimize total latency of pipeline / to increase throughput. Example: - checks all stages' timings....
uses compressor-decompressor methods
so implementing an image-resizer will be faster