gitmhg
gitmhg
yes i get same answer,did you have good idea
> 可能会存在微小的diff,但是一般不影响精度,你用的是哪个模型? 谢谢回复,我用的ppyoloe训练模型,训练模型 和推理模型效果很好,但是训练模型转为 部署serving模型启动serving服务后,相同图片推理模型能够检测到,serving模型检测不到,或者只能检测到一个。 我模型转换命令为: python tools/export_model.py -c configs/ppyoloe/*.yml -o weights=*.pdparams --export_serving_model=True 比如: python deploy/python/infer.py --model_dir=./output_inference/ppyoloe_plus_crn_m_80e_coco_reflect_cloth --image_file=./output_inference/ppyoloe_plus_crn_m_80e_coco_reflect_cloth/test.jpg --device=GPU  而我serving推理: {'err_no': 0, 'err_msg': '', 'key': ['image_0'], 'value': ["['0 0.874075710773468...
> 片能否也发我 在云盘里 
> 你这张测试图片能否也发我一下? 你好请问这个问题有好的解决方案吗
> 请发下部署和推理代码,确认use_gpu开关打开 感谢回复,我是hub serving部署,部署命令: hub serving start --config config.json config.json为:  同时为了排除hub的问题我也用inference_model进行推理测试  发现也是同样的问题 3090 显卡 batch_size=50时候的推理速度  一个图片大概耗时1s
> 看看paddlepaddle安装的版本,还有使用pdx.deploy.Predictor接口中要指定use_gpu=true,默认是false的,接口可参考:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/deploy.md 万分感谢,如你所说我进行修改,inference model推理速度速度又很大提生,但是hub serving config.json推理速度还是很慢 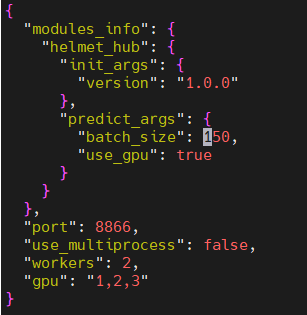
> 从配置文件看没有问题,hub serving start --config config.json命令试试,还有这种方式指定GPU试试 $ hub serving start --modules Module1==Version1 --port XXXX --use_gpu --use_multiprocess --workers --gpu \ 这个不能指定batchsize
> 确认配置文件生效了,另外确认hub serving 使用的paddlepaddle版本是GPU版本的。按理来说就可以使用GPU了 我用hub开源的模型能够使用gpu,但是自己的模型用hub启动显卡利用率为0. 这是我的模型,您方便的话帮我看下是否是模型的问题 链接:https://pan.baidu.com/s/1-0S_UK78a01nptQdS0h1KA 提取码:6666
> 好的,不过是否使用GPU与模型没有关系,除非所有算子都不支持只能回落CPU 谢谢还有一个问题,我参考[模型量化教程](https://github.com/PaddlePaddle/PaddleX/tree/release/2.1/tutorials/slim/quantize)对我训练的模型进行量化,但是量化后模型所占内存没有变小反而变大了1M
> 从配置文件看没有问题,hub serving start --config config.json命令试试,还有这种方式指定GPU试试 $ hub serving start --modules Module1==Version1 --port XXXX --use_gpu --use_multiprocess --workers --gpu \ 您好,您那边测试效果咋样