PaddleX
 PaddleX copied to clipboard
PaddleX copied to clipboard
paddlex推理速度很慢,显卡利用率为0
Checklist:
- 查找历史相关issue寻求解答
- 翻阅FAQ常见问题汇总和答疑
- 确认bug是否在新版本里还未修复
- 翻阅PaddleX 部署文档说明
描述问题
复现
- 您使用的模型和数据集是? 自己创建的数据据
- 请提供您出现的报错信息及相关log
我采用paddlex训练模型然后推理,推理时速度很慢,显卡利用率为0
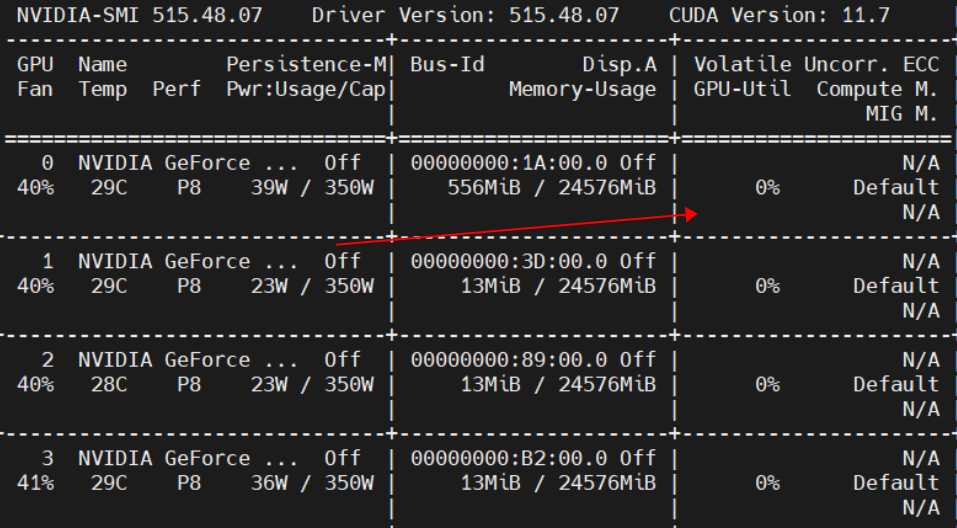 然后我部署到paddhub上面也出现同样的问题
然后我部署到paddhub上面也出现同样的问题
环境
- 如果您使用的是python部署方式,请提供您使用的PaddlePaddle、PaddleX版本号、Python版本号 欢迎您反馈PaddleHub使用问题,非常感谢您对PaddleHub的贡献! 在留下您的问题时,辛苦您同步提供如下信息:
版本、环境信息 1)PaddleHub和PaddlePaddle版本: paddle-bfloat 0.1.7 paddle2onnx 1.0.5 paddlefsl 1.1.0 paddlehub 2.3.1 paddlenlp 2.5.0 paddlepaddle-gpu 2.3.2.post116 paddleslim 2.2.1 paddlex 2.1.0 x2paddle 1.4.0
- 请提供您使用的操作系统信息,如Linux/Windows/MacOS linux
- 请问您使用的CUDA/cuDNN的版本号是? cuda11.6
请发下部署和推理代码,确认use_gpu开关打开 感谢回复,我是hub serving部署,部署命令: hub serving start --config config.json config.json为:
同时为了排除hub的问题我也用inference_model进行推理测试
发现也是同样的问题 3090 显卡 batch_size=50时候的推理速度
一个图片大概耗时1s
看看paddlepaddle安装的版本,还有使用pdx.deploy.Predictor接口中要指定use_gpu=true,默认是false的,接口可参考:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/deploy.md
看看paddlepaddle安装的版本,还有使用pdx.deploy.Predictor接口中要指定use_gpu=true,默认是false的,接口可参考:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/deploy.md
万分感谢,如你所说我进行修改,inference model推理速度速度又很大提生,但是hub serving config.json推理速度还是很慢
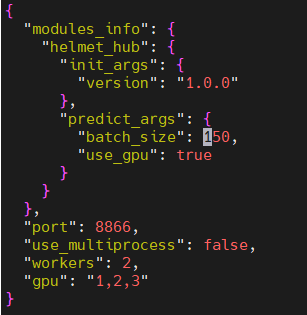
从配置文件看没有问题,hub serving start --config config.json命令试试,还有这种方式指定GPU试试
$ hub serving start --modules Module1==Version1
--port XXXX
--use_gpu
--use_multiprocess
--workers
--gpu \
从配置文件看没有问题,hub serving start --config config.json命令试试,还有这种方式指定GPU试试 $ hub serving start --modules Module1==Version1 --port XXXX --use_gpu --use_multiprocess --workers --gpu \
这个不能指定batchsize
确认配置文件生效了,另外确认hub serving 使用的paddlepaddle版本是GPU版本的。按理来说就可以使用GPU了
我用hub开源的模型能够使用gpu,但是自己的模型用hub启动显卡利用率为0. 这是我的模型,您方便的话帮我看下是否是模型的问题 链接:https://pan.baidu.com/s/1-0S_UK78a01nptQdS0h1KA 提取码:6666
从配置文件看没有问题,hub serving start --config config.json命令试试,还有这种方式指定GPU试试 $ hub serving start --modules Module1==Version1 --port XXXX --use_gpu --use_multiprocess --workers --gpu \
您好,您那边测试效果咋样