Orient朱
![]()
Orient朱
So please look at my code. What's wrong ``` r_mat = mat([ [ 0.39479831968522779, 0.1725597716491206, -0.9024175374969858 ], [ -0.09837140530279795, 0.9844971550094552, 0.14521851946994 ], [ 0.9134863728553773, 0.03144005385956004, 0.40565276976847405 ] ]) center =...
Is that so? In fact, the result looks wrong ``` r_mat = mat([ [ 0.39479831968522779, 0.1725597716491206, -0.9024175374969858 ], [ -0.09837140530279795, 0.9844971550094552, 0.14521851946994 ], [ 0.9134863728553773, 0.03144005385956004, 0.40565276976847405 ] ]) center...
Thank you for your answer. In fact, I'm not sure whether these point clouds come from the same SFM scene. I only know that these point clouds are obtained from...
I put the rebuilt SFM_ data. Convert bin to SFM_ data. JSON, and then get the external parameters R and C of each frame,for example ``` "key": 84, "value": {...
谢谢您的回复~ 我又继续训练了两天,发现总体Loss看起来是在下降的(150-140-130),但是下降速度很慢,还有以下几个现象,麻烦帮忙看下 1、Loss一直有反复,150-140-130-140-150这样反复,比如 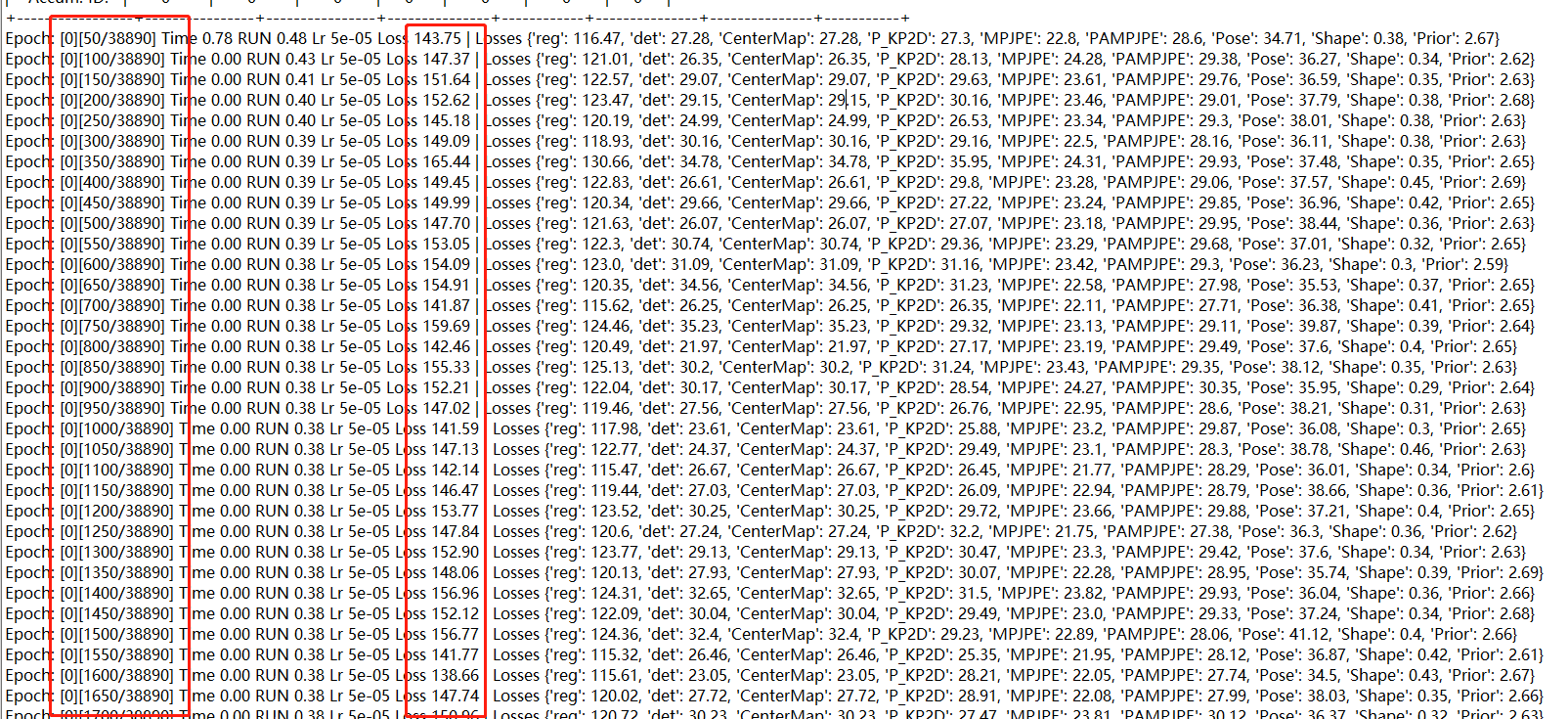  2、有以下日志,我没明白是什么意思 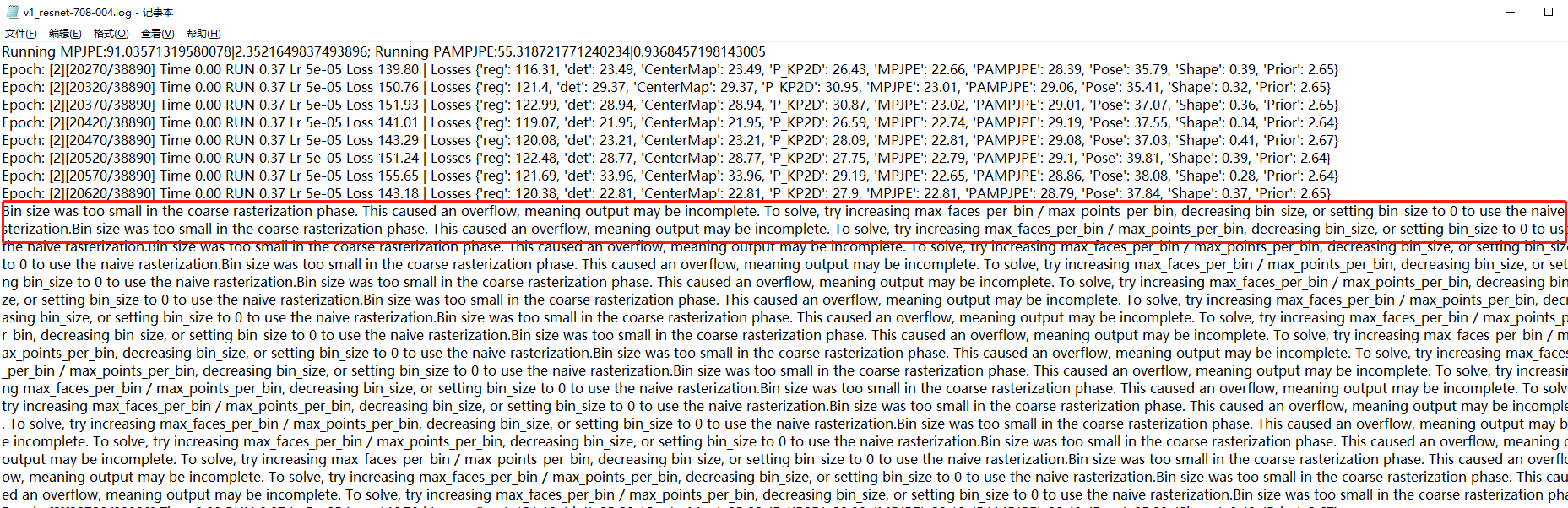 以下是我的日志 [v1_hrnet-708-004.log](https://github.com/Arthur151/ROMP/files/9075755/v1_hrnet-708-004.log) 我还是不太确定这是不是batchsize的问题,现在的线索是 1、加入3DPW训练集后,效果很快达到论文水平 2、不加入3DPW训练集,在batchsize为8的情况下降速度很慢,而且有反复,上面是训练5天左右的结果 3、如果确实是因为batch的问题,我想我只能用更多显卡来训练了
感谢您的回复~ 1、我将pw3d加到了v1.yml中,现在v1.yml数据集内容如下: ``` dataset: 'h36m,mpiinf,coco,mpii,lsp,muco,crowdpose,pw3d' master_batch_size: -1 val_batch_size: 16 batch_size: 8 nw: 2 nw_eval: 2 lr: 0.00005 sample_prob: h36m: 0.16 mpiinf: 0.14 coco: 0.14 lsp: 0.06 mpii: 0.1 muco: 0.12...
感谢您的回复~ 我看到您的代码中使用hrnet作为backbone的训练配置有两种,v1.yml和v1_hrnet_3dpw_ft.yml,这两个的主要差别就是训练数据集的不同,看起来是否加入pw3d就是主要区分是否fine_tune的标识 我的问题是为什么要区分这两种训练模型呢, 既然加入pw3d会表现更好的话就一直加入就可以,为什么v1.yml中不加入并且要训练更久呢 我的猜测这样做是为了更好地评估,但实际上这两种模型是没有本质区别的,如果我要在您的工作基础上继续做论文的话,那么加入pw3d之后训练出来的模型也可以直接和您的结果比较的,对吧