关于复现论文中的结果
大佬您好,非常感谢您的工作~ 我在复现论文结果的过程中遇到了一些问题
我采用了v1.yml来进行训练,由于显卡原因(我的电脑一张3070显卡,8G显存)我的batch调小到了8,其他基本都是默认,以下是我的yml文件 v1.yml.txt
我训练了5个epoch之后,发现Loss虽然在下降,但是下降的很慢,下面是我的log
我之前有尝试过将3DPW的数据集加入到训练之中,发现很快就达到了不错的结果,下面是加入了3DPW之后的log v1_hrnet-0704-001.log
我想确认下我的训练是否有问题,因为看起来虽然下降的比较慢,但是还是在下降的 1、想请大佬帮忙看下日志,能否确认我的训练是有问题的状态? 2、大佬能否发下您的训练日志(使用了pretrian/pretrain_hrnet.pkl),然后我自己对比一下
PS:我没有使用最新的代码,因为看起来和代码并没有关系
您好, 这种单阶段的网络训起来确实是比较慢,它的检测能力和人体姿态恢复能力是交替提升的。 我看了下你的训练log,看起来没什么问题。 如果可以的话,还是建议用最新的训练代码,做了一些必要的优化,并且之前训练存在的问题也解决了一些。可能validation时有些bug,但是训练效果会更好些。 我没有刻意的留存这些log文件,抱歉。之前有些issue里好像有其他人训练的记录。
谢谢您的回复~
我又继续训练了两天,发现总体Loss看起来是在下降的(150-140-130),但是下降速度很慢,还有以下几个现象,麻烦帮忙看下
1、Loss一直有反复,150-140-130-140-150这样反复,比如
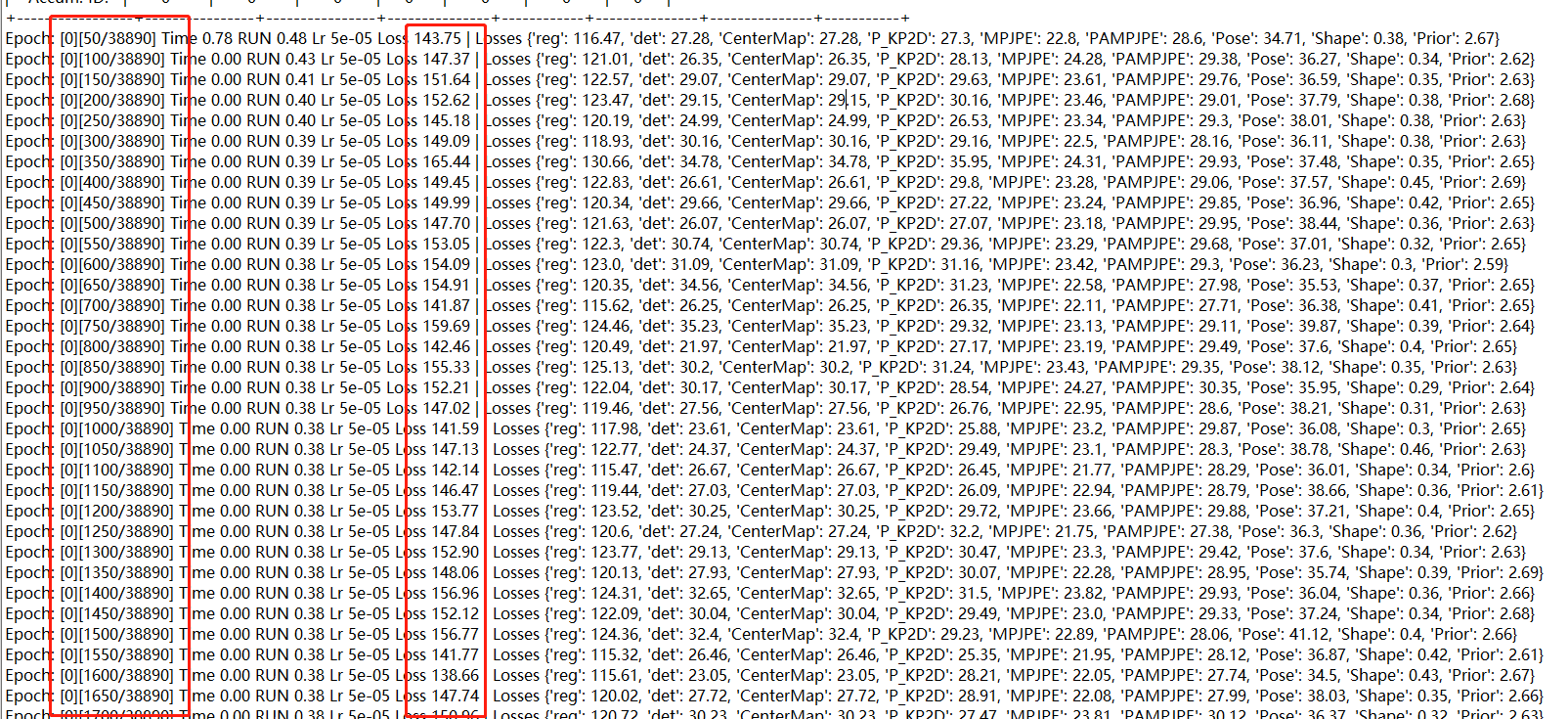

2、有以下日志,我没明白是什么意思
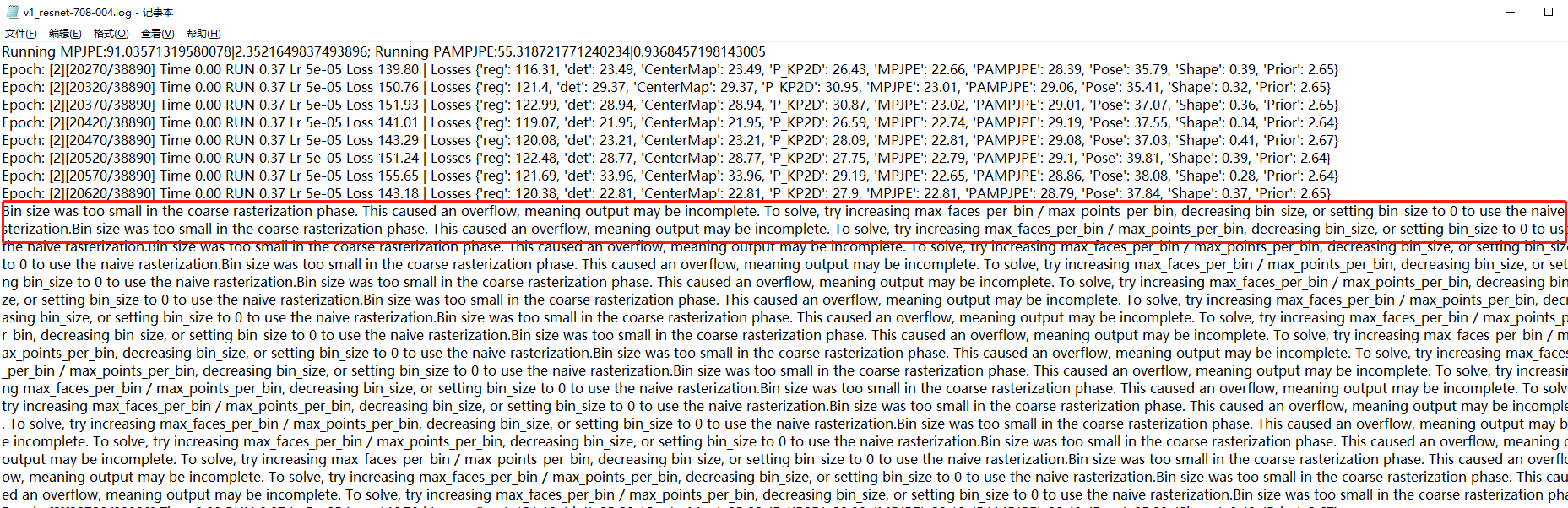
以下是我的日志
我还是不太确定这是不是batchsize的问题,现在的线索是 1、加入3DPW训练集后,效果很快达到论文水平 2、不加入3DPW训练集,在batchsize为8的情况下降速度很慢,而且有反复,上面是训练5天左右的结果 3、如果确实是因为batch的问题,我想我只能用更多显卡来训练了
1.训练loss的反复跳动是正常现象。 2.那个bug是有关于pytorch3D渲染的,和训练无关。
I recommand that you can go with the protocols using 3DPW training set during training, and evaluate on 3DPW test set. Protocols training without 3DPW is counting on long-time training to find the way to fit that domain I think. In this case, I think better MPJPE doesn't mean better generalzation, it may only reflect that the model finally find the way to fit the specific domain. Because the domain gap is really obvious, due to the different defination of 3D skeleton in the protocol without training on 3DPW.
感谢您的回复~
1、我将pw3d加到了v1.yml中,现在v1.yml数据集内容如下:
dataset: 'h36m,mpiinf,coco,mpii,lsp,muco,crowdpose,pw3d'
master_batch_size: -1
val_batch_size: 16
batch_size: 8
nw: 2
nw_eval: 2
lr: 0.00005
sample_prob:
h36m: 0.16
mpiinf: 0.14
coco: 0.14
lsp: 0.06
mpii: 0.1
muco: 0.12
crowdpose: 0.12
pw3d: 0.16
您看这样设置ok吗?
2、加入了pw3d数据集后,只是起到了加速训练的作用,理论上就算不加只需要更长的时间还是可以达到同样效果,对吧?
我比较担心的是加入了pw3d会影响最终模型的正确性,虽然理论上训练用的是train数据集合,评估用的是test数据集合,下面是数据加载的日志
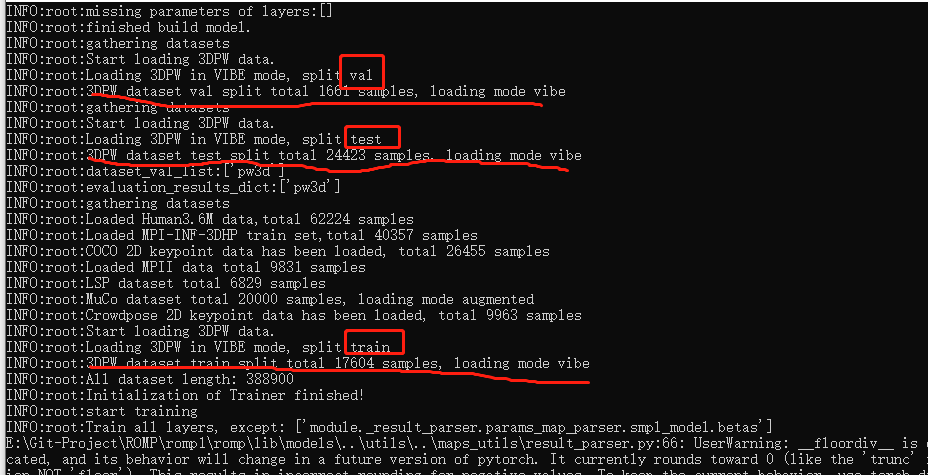
3DPW的测试集和验证集是在这里加载: https://github.com/Arthur151/ROMP/blob/91dac0172c4dc0685b97f96eda9a3a53c626da47/romp/base.py#L170 在这里使用: https://github.com/Arthur151/ROMP/blob/91dac0172c4dc0685b97f96eda9a3a53c626da47/romp/train.py#L117 https://github.com/Arthur151/ROMP/blob/91dac0172c4dc0685b97f96eda9a3a53c626da47/romp/train.py#L142 不会用于训练。
训练集是通过这里加载: https://github.com/Arthur151/ROMP/blob/91dac0172c4dc0685b97f96eda9a3a53c626da47/romp/base.py#L126
也就是说只是用了3DPW的训练集训练。用验证集验证,然后选在验证集上表现最好的checkpoint来测试集评测。
使用3DPW的训练集训练可以帮助模型跨过数据集之间的domain gap(关节点定义不同,相机拍摄条件不同等等),所以会表现更好。
感谢您的回复~
我看到您的代码中使用hrnet作为backbone的训练配置有两种,v1.yml和v1_hrnet_3dpw_ft.yml,这两个的主要差别就是训练数据集的不同,看起来是否加入pw3d就是主要区分是否fine_tune的标识
我的问题是为什么要区分这两种训练模型呢, 既然加入pw3d会表现更好的话就一直加入就可以,为什么v1.yml中不加入并且要训练更久呢
我的猜测这样做是为了更好地评估,但实际上这两种模型是没有本质区别的,如果我要在您的工作基础上继续做论文的话,那么加入pw3d之后训练出来的模型也可以直接和您的结果比较的,对吧