embedding
embedding
可能是文件编码的问题 比如推理UTF-8 with BOM编码的文件会导致上面的问题,即使第一行有text_a
感谢您的提问 (1)您的操作没有问题。span masking不一定在中文上效果更好,可以试试wwm masking (2)由于预训练使用的是mlm,因此没有nsp相关权重,在转换的时候,target需要选择mlm (3&4)训练出来的模型,在embedding和encoder层和原生BERT一样,在下游任务上可以一样使用。target部分只有MLM权重,没有NSP权重。NSP并不是特别重要,因此target选择bert或mlm都可以。如果要复现BERT模型,需要使用 *--target bert* ,如果复现RoBERTa模型,需要使用 *--target mlm*
可以提供一下命令么? 应该是加载的模型和使用的词典不匹配
一行一段文本 语料格式参照这里 https://github.com/dbiir/UER-py/wiki/Pretraining-model-examples#gpt-2
您的语料是BERT格式的么? 直接邮件联系吧 [email protected]
Thanks for the suggestion. We are going to use Unix line endings uniformly.
*scripts/convert_bert_from_huggingface_to_uer.py* More details can be found [here](https://github.com/dbiir/UER-py/wiki/Scripts).
您好,可以把命令以及语料的格式发出来一下?
使用的是mlm目标任务,不应该使用bert的语料格式 https://github.com/dbiir/UER-py/wiki/Quickstart 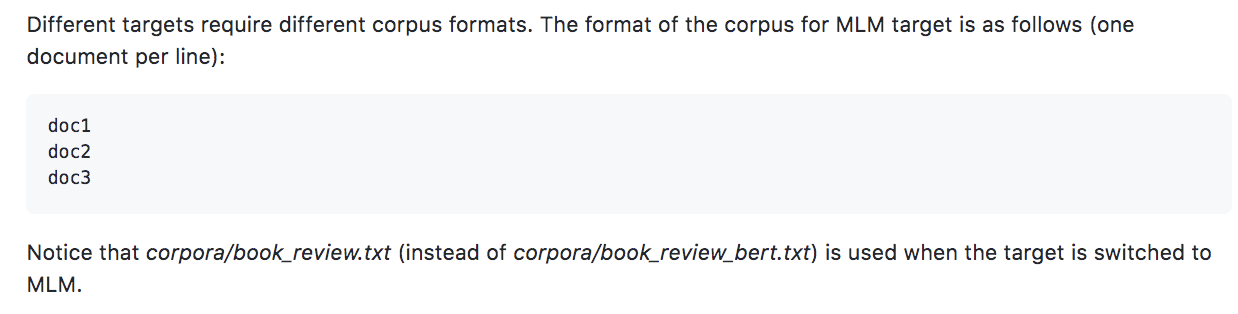 `corpora/part-2021012611.txt`是已经用空格分开的语料么?如果是的,应该使用`--tokenizer space` 如果预处理preprocess使用了`--dynamic_masking`,应该在预训练pretrain阶段指定`--span_masking`
您好 因为模型可能没有学习到任何东西,全部预测为类别0 您可以再检查一下数据集是否合理,似乎您的验证集只有十几条正样本 此外您的tokenizer选择的是space,应该选择bert,这样和这个词典是对应上的 models/google_uncased_en_vocab.txt 更多细节需要讨论可以直接邮箱联系哈 [email protected]