UER-py
 UER-py copied to clipboard
UER-py copied to clipboard
Published
20 hours ago •
 dbiir
dbiir
应用于英文除0报错
您好!非常棒的工作,我想把他应用于英文文本分类工作
我更改了预训练模型路径,词表,还有tokenizer的配置
!CUDA_VISIBLE_DEVICES=0 python3 run_classifier.py --pretrained_model_path models/google_model_en_uncased_base.bin
--vocab_path models/google_uncased_en_vocab.txt
--train_path datasets/train_en.tsv --dev_path datasets/dev_en.tsv
--test_path datasets/test_en.tsv
*--tokenizer space *
--epochs_num 3 --batch_size 32 --encoder bert
在英文二分类的实验上报了如下错误:
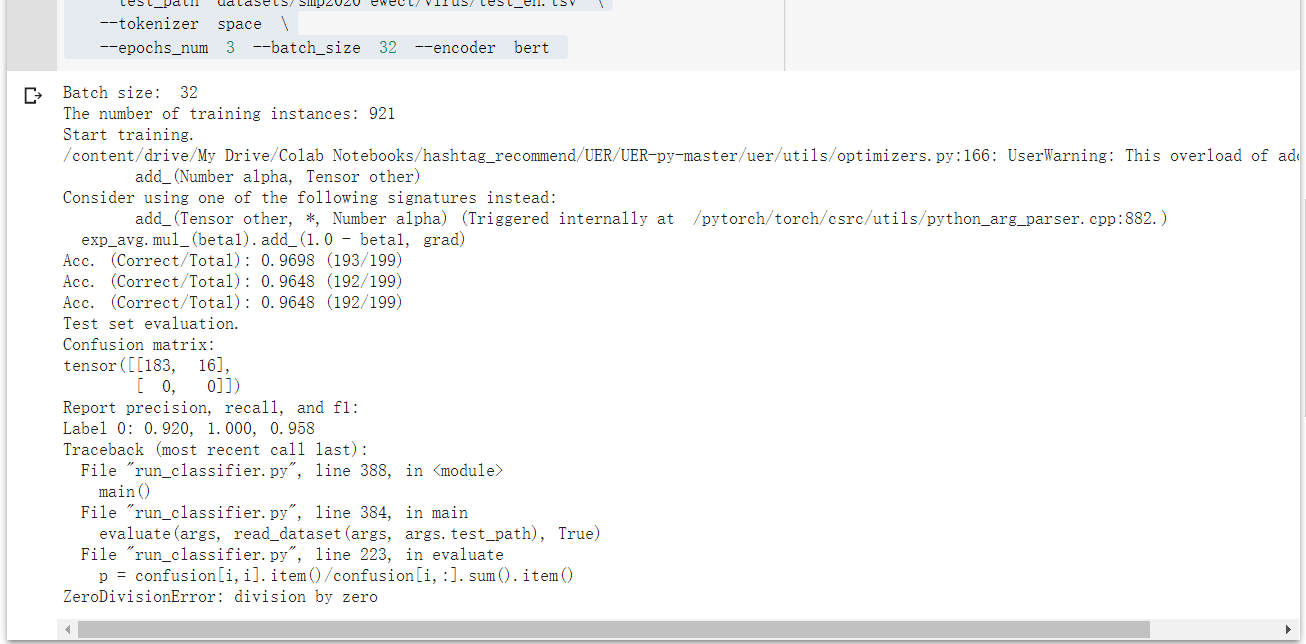
这是我的数据集样例:

此外,我输出了pred和gold向量,发现gold正常但是pred全部为零 感谢您的帮助!
您好 因为模型可能没有学习到任何东西,全部预测为类别0 您可以再检查一下数据集是否合理,似乎您的验证集只有十几条正样本 此外您的tokenizer选择的是space,应该选择bert,这样和这个词典是对应上的 models/google_uncased_en_vocab.txt 更多细节需要讨论可以直接邮箱联系哈 [email protected]