Xu Ding
![]()
Xu Ding
CenterNet-HG Hourglass-104,mAP 42.1 / 45.1,mAP50 61.1 / 63.9 (斜杠前后分别代表single-scale和multi-scale testing) 结果和你的有点差别,是否和训练epoch等调参有关?
谢谢大佬回复,针对您的回复,我再问细点: 1. “需要使用那个数据训练一下,在测试呀。”———我现在是在GPT2预训练模型的基础上做微博摘要数据的finetune,您这句话的意思就是这个吧?还是说先用微博摘要数据做预训练,再用微博摘要数据做finetune? 2. “unilm那个为了保证效果,采用的beamsearch解码。这个项目是为了展示结果的多样性,采用的topk和topp解码”————是不是这里解码改成beam search,最后rouge的效果会好点? 3. “本项目的gpt2模型,我是随机初始化,并且训练轮数仅有5轮”————我看了下你GPT2训练是用的更大的微博数据,unilm那个微博数据是简化版本,我测试得到rouge20%这个结论用的数据是和unilm一致,为了对比 4. 能不能给一些GPT2提高rouge的建议? 感谢大佬!
hi, can you provide a BaiDu link, I cannot open the Google link
> ```python > import paddle > paddle.utils.run_check() > ``` > > 你看看是否能跑通,并麻烦截图发到issue 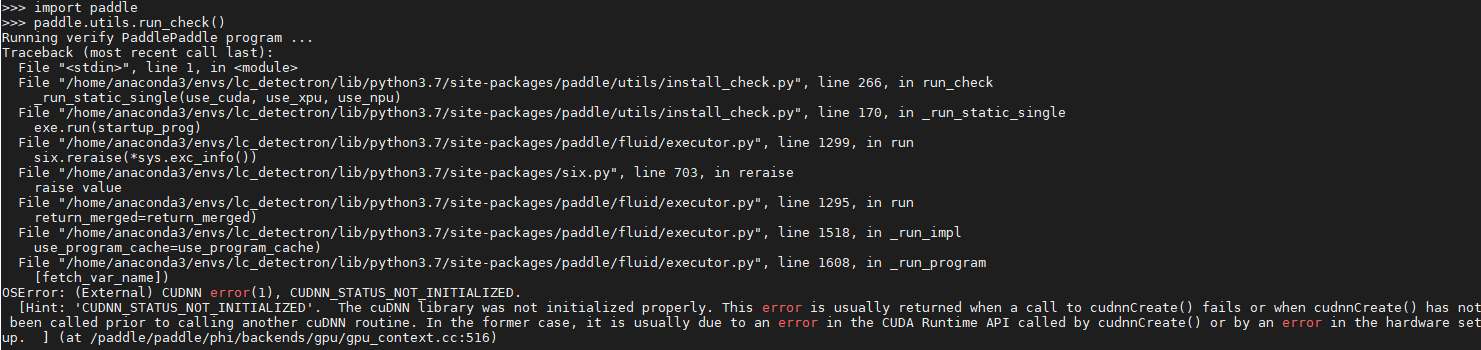
你好,上面的截图是paddlepaddle-gpu==2.3.0的结果 我现在更新到2.3.2版本,执行上面的命令,出现如下截图 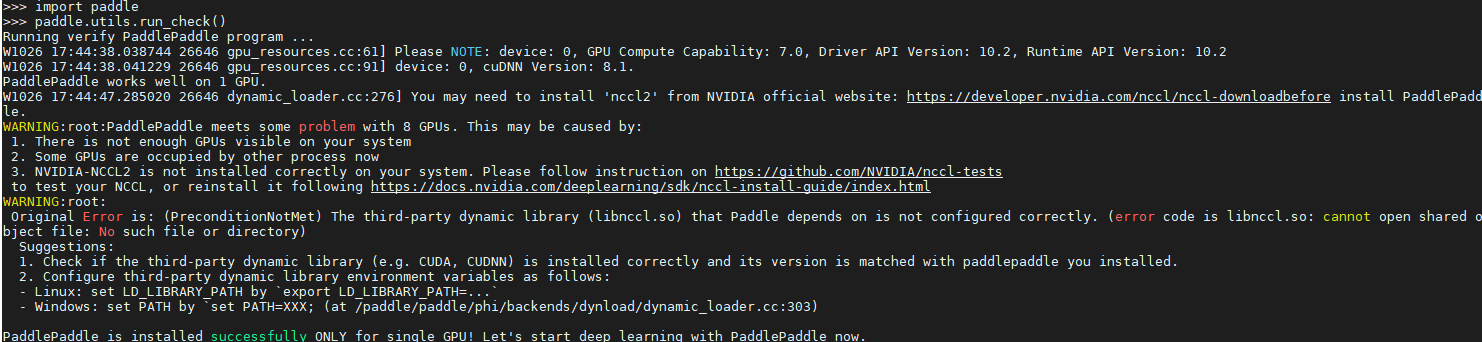
> 还是不行,出现如下错误: Traceback (most recent call last): File "ocr_process.py", line 287, in ocr_results = ocr_preprocess(img_dir) File "ocr_process.py", line 275, in ocr_preprocess parsing_res = ocr.ocr(img_path, cls=True) File "/home/anaconda3/envs/lc_detectron/lib/python3.7/site-packages/paddleocr/paddleocr.py", line 534, in...
> 看了下cuda版本为10.2.89,应该对应paddlepaddle-gpu==2.3.2版本吧,不知道为啥安装之后还是有上面的问题
这个是不是代表已经安装成功了? 
跑了下PaddleNLP/applications/document_intelligence/doc_vqa/下面的三个模块,发现OCR处理模块可以跑通输出结果。 但是Rerank模块的训练部分无法运行,请帮忙确认一下代码是否可正确运行?我这边一直跑不通 File "./src/train_ce.py", line 392, in main(args) File "./src/train_ce.py", line 146, in main ernie_config=ernie_config) File "/users_2/d00477216/docvqa/Rerank/src/cross_encoder.py", line 112, in create_model graph_vars = _model(is_noise=True) File "/users_2/d00477216/docvqa/Rerank/src/cross_encoder.py", line 65, in _model...
@wawltor @JunnYu 请帮忙看一下,好像安装成功了,ocr也可以跑通,但是Rerank训练还是有上述问题