第一片心意
第一片心意

We don't mast write insert statement in flink sql job. Each Flink SQL statement is executed immediately and individually, with corresponding effects.
### Search before asking - [X] I had searched in the [issues](https://github.com/DataLinkDC/dlink/issues?q=is%3Aissue) and found no similar feature requirement. ### Description 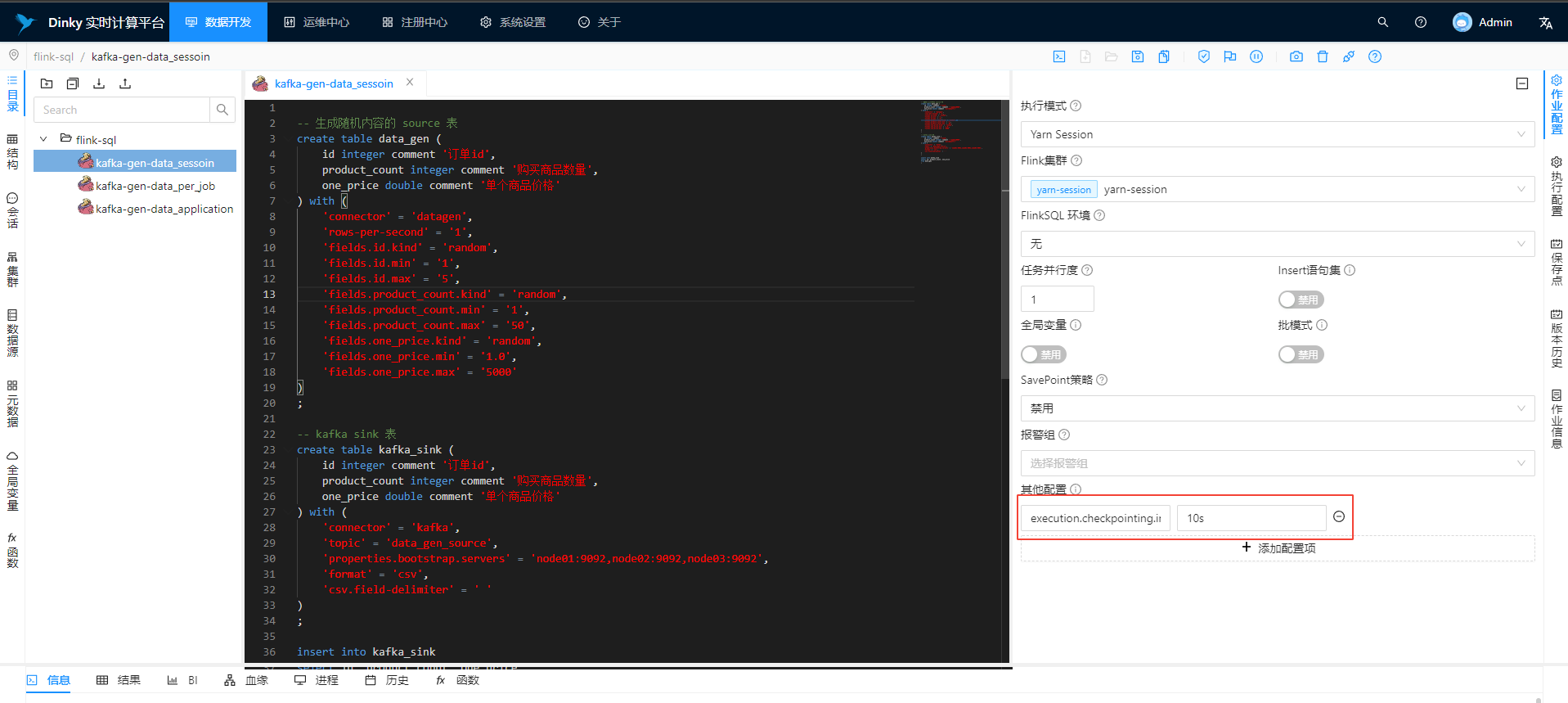 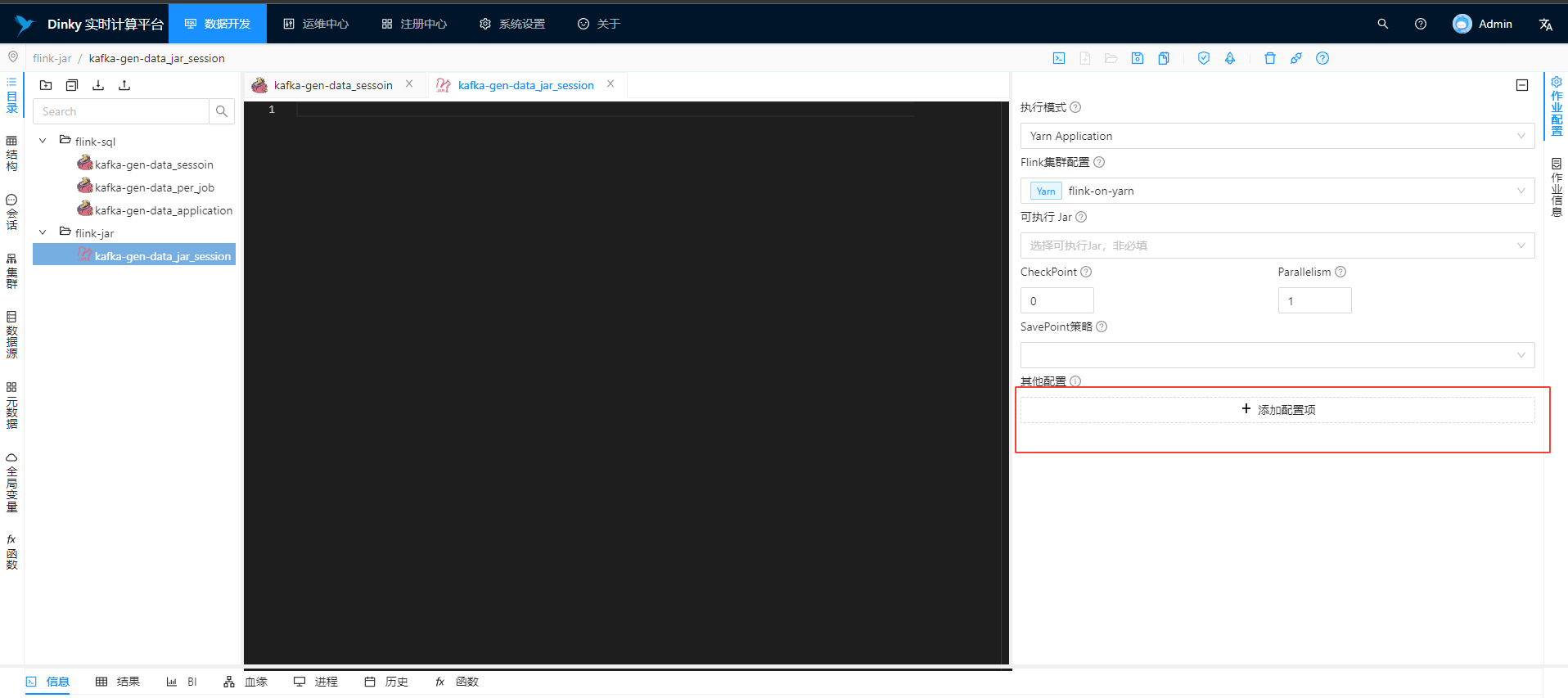 如上图所示,在 flink sql 和 flink jar 任务的开发界面增加有关 checkpoint...
### Search before asking - [X] I had searched in the [feature](https://github.com/apache/streampark/issues?q=is%3Aissue+label%3A%22Feature%22) and found no similar feature requirement. ### Description Create hive catalog sql statement, need core、hdfs、mapred、yarn's xml files. If...
# 描述 现在在创建工单时,默认显示数据源,是数据源名称和数据源 host 拼接起来的,会显示一长串,看起来不太舒服。 # 建议 希望只显示创建数据源时填写的数据源名称。如果有多个数据源,让用户自己通过数据源名称自己去区分即可。 # 为啥 当前显示格式看起来不太舒服。 # 相关截图  
# 版本信息 UI: `release-3.2310.x 47cd220` DMS: `release-3.2310.x e9fac5174e` SQLE: `release-3.2310.x 2ab6c3fa2e` # bug 描述 简述:钉钉流程接入后,审批操作和消息与钉钉同步有问题 具体现象: 1. 创建工单之后,下级审批人钉钉可以收到消息,但是审批人通过钉钉内消息的**同意**或**拒绝**按钮操作,信息无法同步到 SQLE 平台。或许单纯是因为延迟,需要排查。 2. 每级审批人通过 SQLE 平台通过或拒绝工单后,工单创建人钉钉可能收不到工单审批结果,收到消息的情况下,有延迟(2 分钟),但也有过了半小时收不到工单审批状态的消息情况。不过一级审批人通过后,二级审批人的钉钉是可以收到工单需审批消息的。 ## 截图如下 工单在平台中的审批流程和时间如下,一共两级审批,均在平台中操作通过:  工单创建人对应的钉钉收到的消息情况如下,只收到这一条工单状态变化消息:...