Alex "mcmonkey" Goodwin
Alex "mcmonkey" Goodwin
`Tried to load multiple loras and won't. Even on latest hijacked PEFT.` I mean the main thing on that is just getting the patched hacks pushed upstream so that we're...
`target_modules` is mostly just identifying where the LoRA connects to because it's unique based on model type. I don't _think_ there's any reason to muck with that (unless there's room...
Full model reload wasn't needed for 8-bit, but might be for 4-bit, or at least with the patches? If your version works better, should PR improvements.
@USBhost `For warm up steps that should only apply to constant with warm up scheduler. Iirc.` 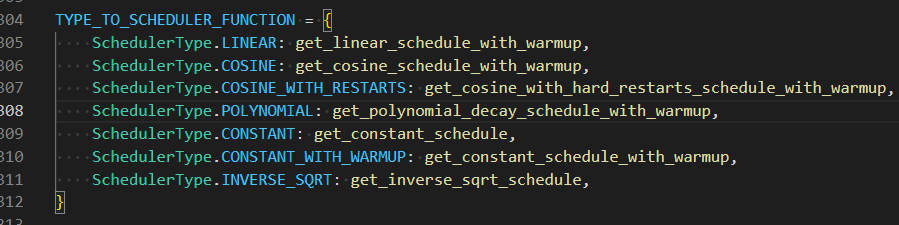 All schedulers other than `constant` support a warmup. (inverse_sqrt does too even though...
All above requests (unless I missed one) are now done, and updated in the OP. Open questions I had previously are addressed and handled now. Saving will happen in the...
Added an option to select the optimizer, `adamw_bnb_8bit` doesn't seem to actually reduce VRAM over the default `adamw_hf`. Might be valuable to do some research/testing to see if maybe one...
Oh, that's a great idea!
Could you rebase/merge against the new main? There's been changes to the same sections of code which prevent it from merging. Also, perhaps add a comment in the docs somewhere...
LLaMA-Precise preset is near-deterministic (different seeds rarely yield different outcomes), make sure to test with a different preset if you think this change is breaking seeding behavior.
You can use either JSON or simple text files. There's a training tab in the webui and all the inputs are explained. If you use JSON datasets, you need to...