Mikhail Scherbina
Mikhail Scherbina
This somewhat coincides with the following line of code from the official codebase: https://github.com/open-mmlab/mmdeploy/blob/master/csrc/mmdeploy/codebase/mmpose/keypoints_from_heatmap.cpp#L179
testing it with the master branch
@cudawarped Should I be the one to do it? I.E. replace with the contexted version
I did a compile time static dispatch for either _Ctx or non-_Ctx methods. Tested, it performs not as good as opencv's because it uses cv::cuda::Mat::setTo to fill image with border...
You may not like me using concatenation macros, it can be avoided
Trying same experiment with CUDA_LAUNCH_BLOCKING=1 yields the same result: npp is slow
Here is the sort of performance I get with this simple kernel: ``` __global__ void flip_kernel(const cv::cuda::PtrStepSz input, cv::cuda::PtrStepSz output) { const int x = blockIdx.x * blockDim.x + threadIdx.x;...
Looking at Nvidia Nsight Compute, npp version is quiet gappy and takes 0.9ms  whereas without npp its much more saturated and takes 0.15ms 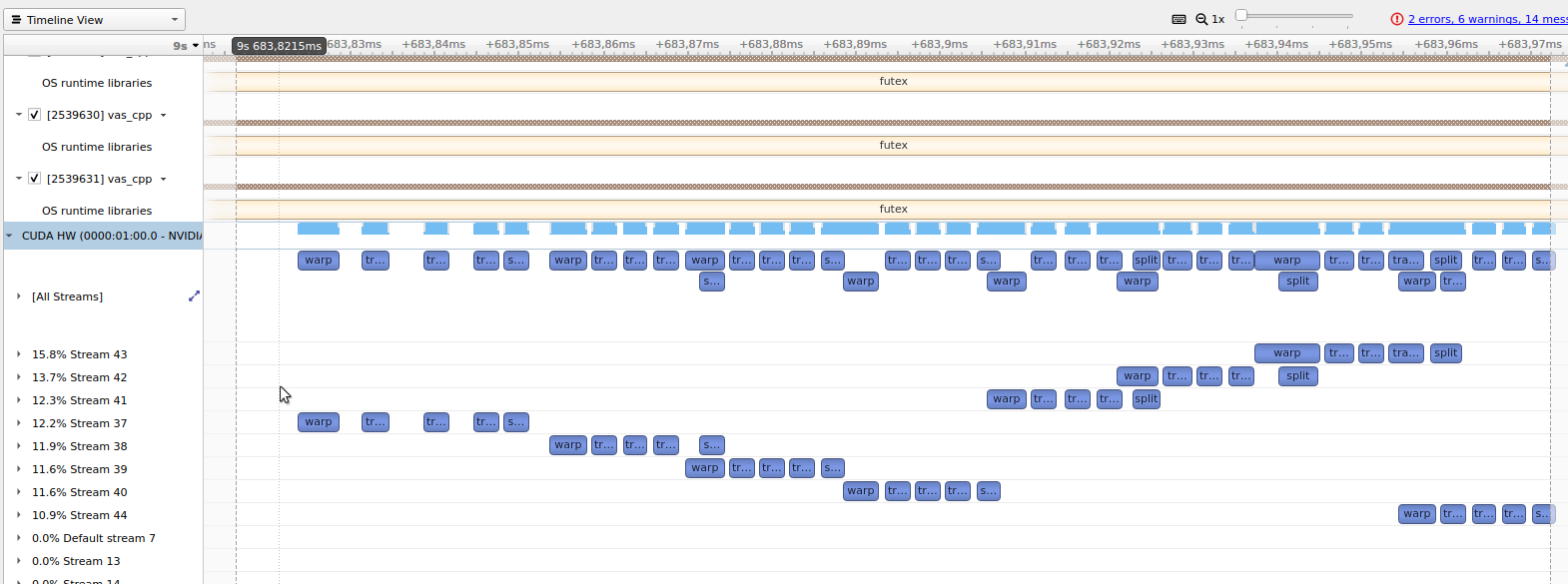 Looking deeper into the issue...
That's [an issue from 2016](https://stackoverflow.com/a/39204905), but I think, theoretically NPP should support multiple streams, as stated in the docs, but the reality is weird... Maybe there should be an option...
> Note: Also new to NPP 10.1 is support for application managed stream contexts. Application managed stream contexts make NPP truely stateless internally allowing for rapid, no overhead, stream context...