opencv_contrib
 opencv_contrib copied to clipboard
opencv_contrib copied to clipboard
NPP performance bottleneck with multiple streams
System information (version)
- OpenCV => 4.6
- Operating System / Platform => Linux x64 with Nvidia Cuda 11.6
- Compiler => gcc
Detailed description
Hello! I am working on a pipeline with multiple stream executing steps. It looks something like that and flips every second image in the pipeline. Everything works fine, however I have noticed a huge performance bottleneck when dealing with nvidia's npp. For example in warpAffine, it takes ~20 times longer than your own implementation with WarpDispatcher::call.
Here is my pipeline
cv::Mat trans_mat = get_affine_transform(cs, m_pixel_std, m_input_size);
cv::cuda::warpAffine(
*input.image,
m_warped_resized_image,
trans_mat,
m_input_size,
cv::INTER_LINEAR,
cv::BORDER_CONSTANT,
cv::Scalar(),
m_stream
);
if (m_flip_images && m_index % 2 == 1)
{
cv::cuda::flip(m_warped_resized_image, m_flipped_image, 1, m_stream);
m_flipped_image.convertTo(m_float_resized_image, CV_32FC3, 1.f, m_stream);
}
else
m_warped_resized_image.convertTo(m_float_resized_image, CV_32FC3, 1.f, m_stream);
cv::cuda::subtract(m_float_resized_image, cv::Scalar(127.5f, 127.5f, 127.5f),
m_float_resized_image, cv::noArray(), -1, m_stream);
cv::cuda::divide(m_float_resized_image, cv::Scalar(128.0f, 128.0f, 128.0f),
m_float_resized_image, 1, -1, m_stream);
cv::cuda::split(m_float_resized_image, m_chw, m_stream);
When I do NO changes to your library, perf output looks something like that:

as you can see, cudaWarpAffine is really performance hungry because of npp.
When i disable the npp, simply by setting this if statement to false, I see drastic performance improvement, like that, you cant even see the call to warpAffine:

But cv::cuda::flip still uses npp and takes way longer that it should, it calls to npp::SetStream and cudaStreamSynchronize, which is dumb, why would anyone need this to flip an image.
Here is profiler, second call is to cudaStreamSynchronize.

Steps to reproduce
Compare speed of execution of cv::cuda::warpAffine with and without npp on multiple streams. Same goes to cv::cuda::flip
Possible solution
Do not use npp, and write a custom kernel, like that in warpAffine_gpu
Issue submission checklist
- [*] I report the issue, it's not a question
- [*] I checked the problem with documentation, FAQ, open issues, forum.opencv.org, Stack Overflow, etc and have not found any solution
- [*] I updated to the latest OpenCV version and the issue is still there
- [*] There is reproducer code and related data files: videos, images, onnx, etc
Trying same experiment with CUDA_LAUNCH_BLOCKING=1 yields the same result: npp is slow
Here is the sort of performance I get with this simple kernel:
__global__ void flip_kernel(const cv::cuda::PtrStepSz<uchar3> input,
cv::cuda::PtrStepSz<uchar3> output)
{
const int x = blockIdx.x * blockDim.x + threadIdx.x;
const int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x >= input.cols || y >= input.rows)
return;
output(y, x) = input(y, input.cols - 1 - x);
}
void horizontal_flip(const cv::cuda::GpuMat& input, cv::cuda::GpuMat& output, cv::cuda::Stream &stream)
{
if (input.size() != output.size() )
output.create(input.size(), input.type());
CV_Assert(input.channels() == output.channels());
const dim3 block(16,16);
const dim3 grid(cv::cuda::device::divUp(input.cols, block.x), cv::cuda::device::divUp(input.rows, block.y));
auto stream_cuda = cv::cuda::StreamAccessor::getStream(stream);
flip_kernel<<<grid, block, 0, stream_cuda>>>(input, output);
}
Thats like, a lot faster

Looking at Nvidia Nsight Compute, npp version is quiet gappy and takes 0.9ms
 whereas without npp its much more saturated and takes 0.15ms
whereas without npp its much more saturated and takes 0.15ms
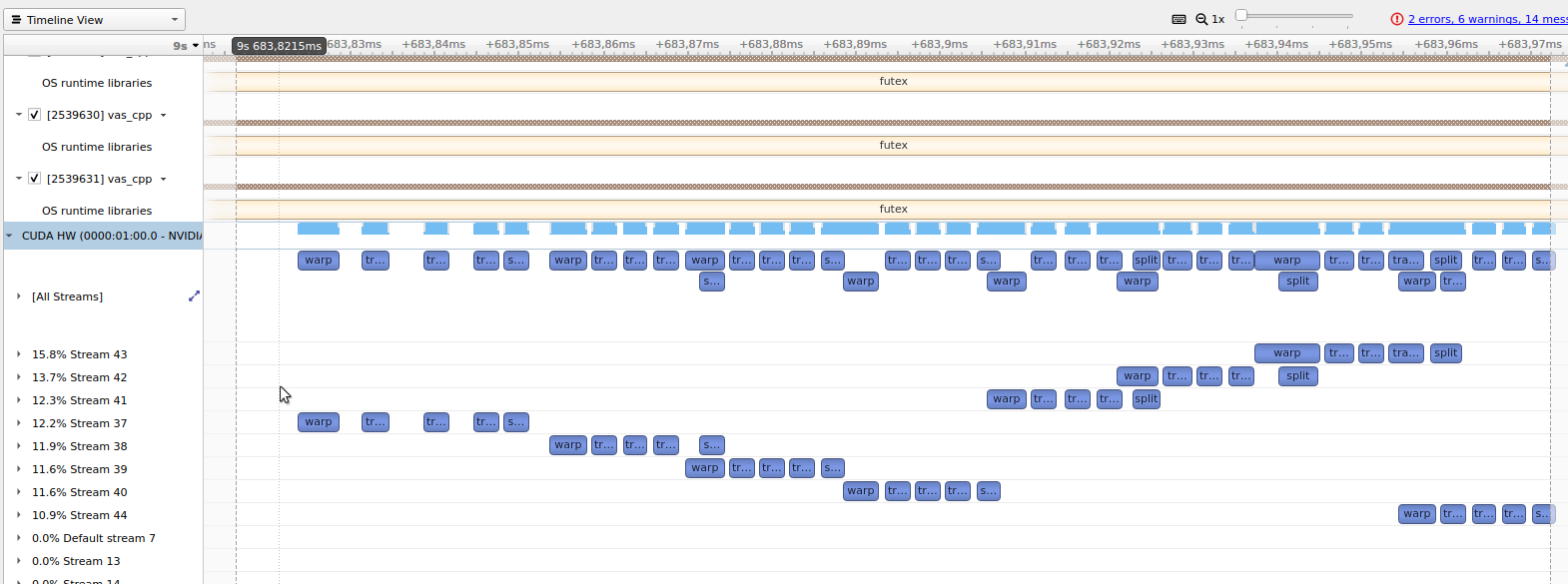
Looking deeper into the issue I see a bunch of ioctl calls when npp is used, originating in warpAffine npp kernel caller doing SetStream. Are they setting stream on the GPU? That's just weird......

They even state in their docs that flushing the current stream can significantly affect performance.
That's an issue from 2016, but I think, theoretically NPP should support multiple streams, as stated in the docs, but the reality is weird... Maybe there should be an option to disable NPP out of the box when doing CMake by defines?
NPP in their docs say that concurrency with streams is supported, but its quiet hard to understand how, theoretically, only async dispatch from one processor thread is supported, assuming global stream context is used.
In the meantime, look at your profiler and if any of the timings look odd, and if there is NPP in there, you know what to fix
Note: Also new to NPP 10.1 is support for application managed stream contexts. Application managed stream contexts make NPP truely stateless internally allowing for rapid, no overhead, stream context switching.
Well, tested that with NPP 11.6 if that matters