hiroi-sora
![]()
hiroi-sora

### Expected behavior 预期的功能 win截屏(Win+PrtSc或Win+Shift+S)默认不会截到屏幕上的光标。而开启Magpie后,截屏始终能截到光标。 能否添加功能:系统截屏时隐藏光标。或者软件内自带截图功能:保存不含光标的当前全屏截图到指定路径。 您的项目非常好用。感谢!! 另:我尝试用AHK脚本来在截屏时隐藏光标。这段代码在别的场景中运行良好,可惜还是不能用在Magpie中;隐藏光标的`ChangeCursor()`不生效。 (若启用放大前光标是正常状态,则开启放大后,无法用`ChangeCursor()`将其设为隐藏。反之,放大前是隐藏状态,则放大后无法恢复光标显示。) AHK代码: ```AutoHotkey ChangeCursor(OnOff=1) ; 隐藏 = 0 | 显示 = 1 | 切换 = -1 { static AndMask, XorMask, $, h_cursor...
GUI 症状:点击任意“选择文件”后,必须在弹出的浏览窗口中选择一个文件。若不选择文件 直接关闭,则会自动重新打开选择窗口。此时也无法通过正常手段关闭程序,只能任务管理器里结束,或者先随便选择一个文件。 如果这是设定特性的话还是有点不便的,允许用户不选择文件而直接关闭浏览窗口 更符合一般的使用习惯~ 另:建议Releases里放一个打包好所有exe及运行库的压缩包,方便下载
### 预览截图:  ### 预览输出: gradients in at least two (significantly) different orientations are the easiest to localiz, as shown schematically in Figure 7.4a. These intuitions can be formalized by...
# 预览截图: 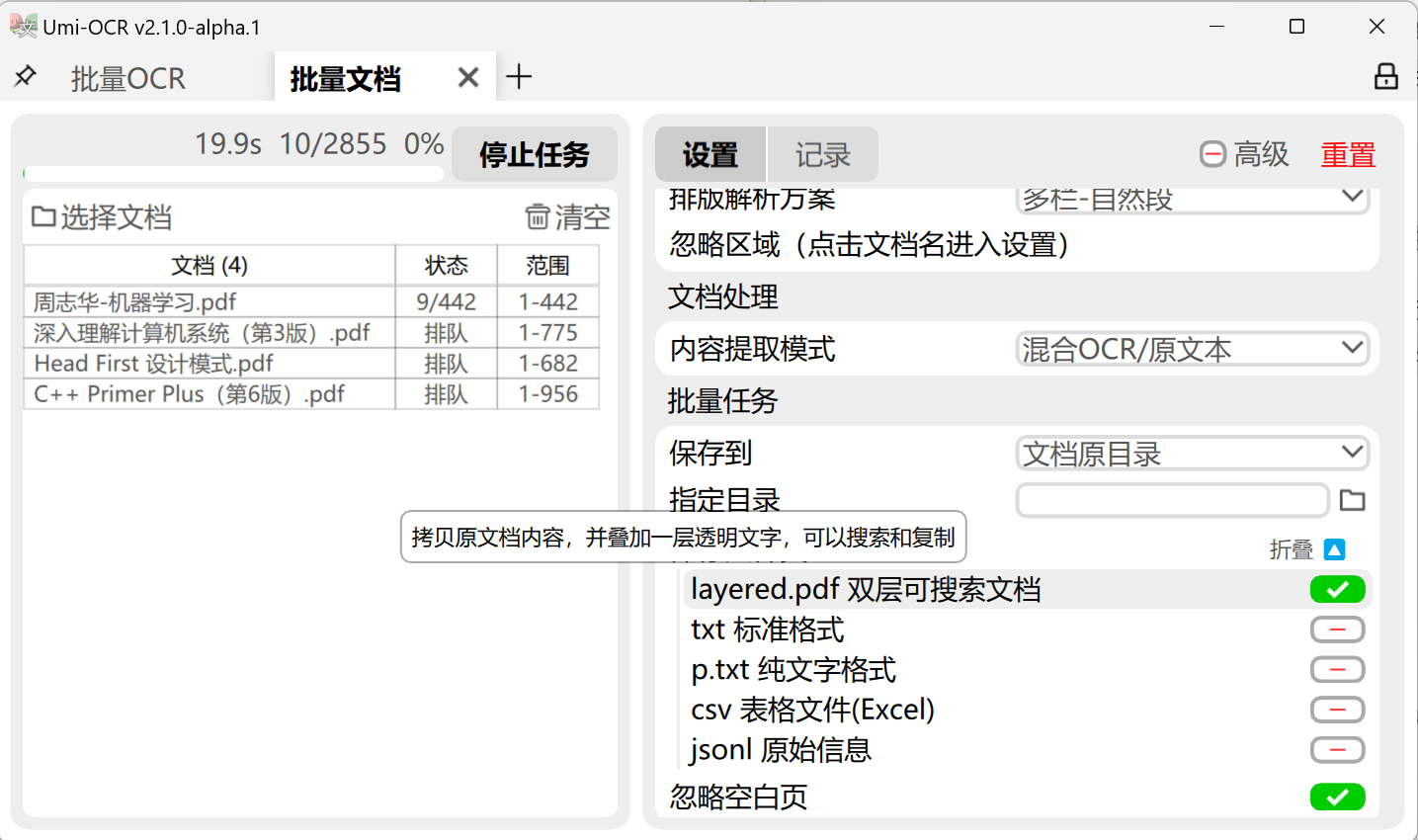 ## 扫描件转为双层可搜索PDF 示例:  ## 测试下载: https://github.com/hiroi-sora/Umi-OCR/releases/tag/alpha%2F2.1.0 有任何与测试版文档识别有关的问题,可以在本issue下回复。如果有需要,请上传你的PDF文件,以供问题定位。
开发者 @elliottzheng 及各位CopyTranslator用户大家好!我是离线OCR软件 [Umi-OCR](https://github.com/hiroi-sora/Umi-OCR) 及引擎组件 [PaddleOCR-json](https://github.com/hiroi-sora/PaddleOCR-json) 的开发者。 以前,CopyTranslator支持调用PaddleOCR-json引擎,提供轻度OCR功能。现在,Umi-OCR v1.3.5 支持与 CopyTranslator 联动,提供更完善的OCR服务。 以下是简要步骤: 1. 下载 [Umi-OCR](https://github.com/hiroi-sora/Umi-OCR) ` v1.3.5` 及以上版本 。**勾选设置页底部的`高级选项`,重启软件。** 2. 如果不介意CopyTranslator监听剪贴板(每次剪贴板变动都尝试翻译),那么勾选Umi-OCR的`自动复制结果` 和CopyTranslator的`监听剪贴板`即可。 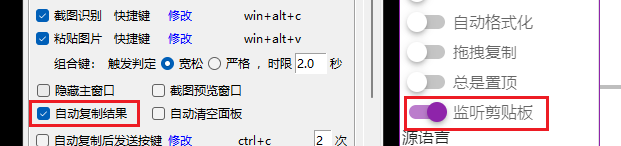 3. 如果不一定始终开启监听剪贴板,又希望Umi-OCR在任何情况下能唤起CopyTranslator,可以这样处理:CopyTranslator在设置里勾选`双Ctrl+C翻译`;Umi-OCR的`自动复制后发送按键`录制为`ctrl+c`,`2`次。(需要先勾选设置页底部的`高级选项`) 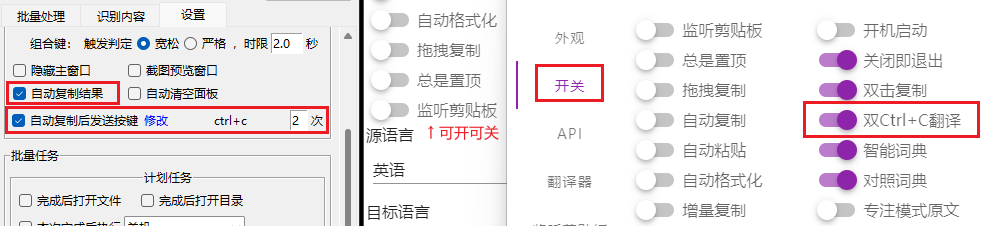 4. 这样,Umi-OCR完成OCR后,会联动唤起CopyTranslator进行翻译。你可以设置Umi-OCR为静默模式,使得每次任务只会弹出CopyTranslator一个窗口。
当前,python的stdout、stderr会被重定向到pystand进程的控制台(如果存在)。 假如希望将pystand的输出重定向到文件,如: ``` pystand.exe > test.txt ``` 是无法实现的, test.txt 依然为空。 或者用另一个程序调用 pystand.exe ,也无法在管道获取输出内容。 请问,如何实现让pystand输出到正确的地方? 即:如果pystand进程的stdout存在,那么将python的stdout也重定向到相同的地方。
首先感谢韦神,带来了这个非常优秀的工具。 我使用了PyStand一段时间,参考过本项目issues及韦神等大佬的文章,积累了一点点相关的经验。比如如何自定义启动脚本的路径,一键编译,如何从0开始搭建和管理Python环境, 如何用VS Code调试代码(支持断点和第三方库的语法补全),及pyqt、qml的中文路径问题等。也根据自己的需求修改过原项目代码。 本项目README和WiKi相对没那么丰富,所以我整理了一下自己的经验,写在 [我的fork的README](https://github.com/hiroi-sora/PyStand-Sora) 里。也许可以给小白或者有需要的人提供一些参考,让不熟悉C++的人也可以一定程度上编译项目和自定义Python环境,及通过VS Code调试的方案。希望能为PyStand生态提供一点资料。 **使用PyStand的项目示例: [Umi-OCR](https://github.com/hiroi-sora/Umi-OCR)**
例图:  测试系统:win7 x64 旗舰 sp1 7601 纯净版 python版本:3.8.10 32位 如果运行PyStand,或者直接运行python解释器时,出现了这些错误: > 无法启动此程序,因为计算机中丢失api-ms-win-crt-conio-l1-1-0.dll 。尝试重新安装该程序以解决此问题。 > 应用程序无法正常启动(0xc000007b)。请单击确定”关闭应用程序。 > Cannot find Py_Main() in: ……/python3.dll ## 大概率是缺乏VC运行库导致。 下载安装VC运行库即可解决。 https://aka.ms/vs/17/release/vc_redist.x64.exe
各位开发者好,我是 [Umi-OCR](https://github.com/hiroi-sora/Umi-OCR) 的作者。 Umi-OCR 是一个开源的OCR软件,目前正在开发PDF扫描件识别的功能。其中的一个难点在于,OCR得到的文本块的顺序,往往与实际阅读顺序不符合,特别是在多栏布局的文档中。我需要根据文档的排版,正确区分出不同列,按实际阅读顺序为文本块进行排序。 pdf2docx 中也涉及一些基于规则的排版解析功能。我浅读了部分代码,这给了我一些启发。 最终,我设计出一个新算法: [GapTree_Sort 间隙树排序法](https://github.com/hiroi-sora/GapTree_Sort_Algorithm) 。它通过寻找文本块之间的间隙,将页面切割为不同的纵向区块,构建出布局树。最后,前序遍历布局树,即可得到符合人类阅读习惯的文本排序。 当然,除了排序文本块,也能通过布局树分析更多排版信息。(不过它不是针对PDF设计的,没有考虑块对象本身附带的标签等信息。) pdf2docx 当前的规则匹配,只支持最多2栏、且列宽不能相差太大。 而 GapTree_Sort 支持更复杂的排版情况。如:任意多栏布局(>2),列宽不一致,跨多列区块等。 另,该算法对于常见布局的时间复杂度仅为 O(n) ,n为文本块数量。仓库中有证明。 GapTree_Sort 是个刚开发的算法,可能有很多不完善的地方;各位可以来测试或提供一些建议。仓库内有示例代码和更详细的算法流程介绍。 https://github.com/hiroi-sora/GapTree_Sort_Algorithm
### [Translate to English](https://github-com.translate.goog/hiroi-sora/Umi-OCR/issues/447?_x_tr_sl=zh-CN&_x_tr_tl=en&_x_tr_hl=en&_x_tr_pto=wapp) ## Umi-OCR 常见问题 这个Issue列举一些本项目常见的问题及解答。 提出新Issue之前,请确保在您已经读过此篇内容或搜索过其他Issue,确保问题没有重复。 目录: - [应用程序无法正常启动(0xc0000142)](https://github.com/hiroi-sora/Umi-OCR/issues/447#issuecomment-2025223230) - [[Error] OCR init fail.](https://github.com/hiroi-sora/Umi-OCR/issues/447#issuecomment-2025223230) - [某种语言识别准确率低](https://github.com/hiroi-sora/Umi-OCR/issues/447#issuecomment-2025245747) - [表格识别 / 图片翻译](https://github.com/hiroi-sora/Umi-OCR/issues/447#issuecomment-2027145314) - [Linux 与 MacOS 支持](https://github.com/hiroi-sora/Umi-OCR/issues/447#issuecomment-2029782601) - [GPU加速](https://github.com/hiroi-sora/Umi-OCR/issues/447#issuecomment-2044070512)...