hiroi-sora
![]()
hiroi-sora
(Update:此问题已在 v1.2.6 解决。) v1.2.5 的原回复: 您例图的上下边缘太窄,这会阻碍OCR文本检测算法的解析。这是本项目采用的识别库PaddleOCR中 文本检测(det)目前的一个缺陷,它需要一定的额外空间来确定文字范围框。 只要加大图片的高度,就能让识别准确率恢复正常: 👇原图识别结果:`由于没有选择(CWS)方式`  👇增加高度之后:`由于没有选择俯仰或倾斜方式,飞行方式指示器显示A/P处于驾驶盘操纵(CWS)方式。`  因此,这个问题的临时解决方法: 1. 截取上下边缘更多的素材图片用于识别。据我测试,只要上下边缘 >= **一个字符的高度**,就不会影响识别准确度。 可能的程序优化方式:(我暂时没计划实现这些优化) 1. 针对性地训练文本检测det模型用于该场景。 2. 在OCR前预处理,为高度过窄的图片自动添加空白边缘。 关于其他家API: - 我测试了腾讯OCR在线接口,似乎没有这个问题。你有大量需求的话,也许可以寻找使用 **腾讯在线api(收费)** 的同类项目。
新版本 `v1.2.6` 已经彻底解决这个问题了。随着识别引擎的更新,窄边图片不会降低准确度 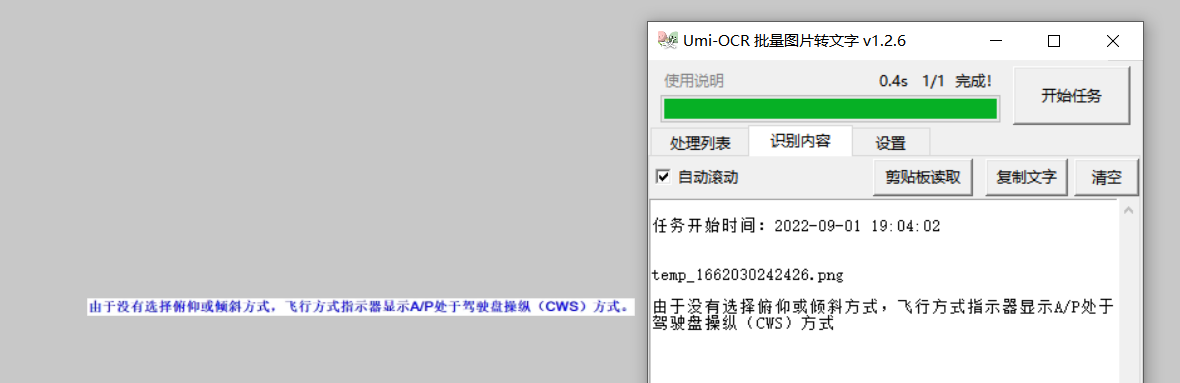
抱歉哦,没有这个计划。 本项目中python的ui界面模块应该能很容易的移到macOS。难点是c++的PaddleOCR-json opencv模块要重新编译,它与py的进程间通信也要重新规划。 我没有mac设备,暂时没有适配macOS的打算~🤣
哈哈,感谢你发现了这个神奇的Bug~ 我调查了一下,发现事情是这样的:剪贴板里的数据有各种格式定义嘛,比如`位图CF_BITMAP、文件句柄CF_HDROP、字符串CF_UNICODETEXT`等。一条数据可以同时具有多种格式。我之前的代码只检测剪贴板是否为位图CF_BITMAP,是则调用OCR。 而微信复制的时候,它先把图片写入临时文件夹`C:\Users\xxxx\AppData\Local\Temp\WeChat Files`,再把图片字节和文件句柄同时写入剪贴板,即同时具有`CF_BITMAP`和`CF_HDROP`双重属性,因此干扰了我程序的判断。 实际上,我[昨天的更新](https://github.com/hiroi-sora/Umi-OCR/commit/c190f02d3d5173ec48f528a2f6d8b8ea3f216ce7)已经间接解决了这个问题,能以**读入临时文件的文件句柄**的形式识别微信复制到剪贴板的图片了。不过还不够完美,我之后试试改成优先以**位图**的形式读入~
`v1.3.0` 已更新并修复该Bug。
嗯,软件内置截图模块正在开发中,下个版本就有了
`v1.3.0` 已更新该功能。
试下测试版 alpha 5 https://wwn.lanzoul.com/b037embad 密码:1111 (下载`Umi-OCR.v1.2.7 Alpha 5.7z`)
你好,可以提供一下CPU具体型号和Win10具体版本号吗? 0xc0000142可能是由于CPU不支持某些指令集、或Win10某些运行库版本不兼容导致,我排除一下问题。 查CPU型号:任务管理器 ⇒ 性能。 查Win10版本:Win+R ⇒ 输入`winver`。
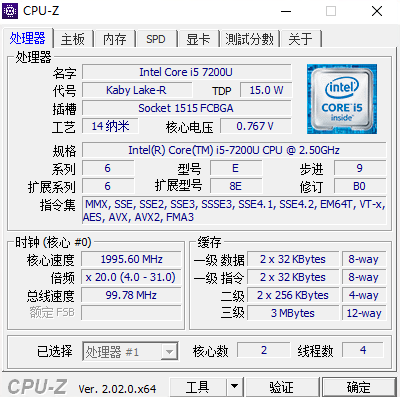
很好!大概知道问题所在了。 烦请再帮我一个忙,用 [CPU-Z](https://www.cpuid.com/downloads/cpu-z/cpu-z_2.02-cn.zip) 查看一下处理器参数,将首页截图给我,如下图