gemeinl
gemeinl
Code of fisher information https://github.com/forrestbao/pyeeg/blob/master/pyeeg/fisher_info.py#L32-L37 and svd entropy https://github.com/forrestbao/pyeeg/blob/master/pyeeg/entropy.py#L269-L274 is identical.

-improved selection of recordings to be loaded -added verbose argument to suppress mne logging
`test_cropped_decoding.py`, `test_eeg_classifier.py`, and `test_trialwise_decoding.py` fail due to latest PyTorch update (1.8.0 -> 1.9.0) and need an update.
As mentioned in https://github.com/braindecode/braindecode/pull/312#discussion_r677358235, there are duplicates in the classes `EEGClassifier` and `EEGRegressor`. To solve this, it would be possible to introduce a new class `EEGNeuralNet`.
In the TUH example, recordings are first re-referenced to CAR and afterwards channels are picked. Like this, artifacts in channels not part of the selection will be added to all...
I would like to propose adding tests that ensure our code runs within an expected time frame. I am thinking about our dataset classes, the windowers as well as runtime...
If I remember correctly, one of the reasons to use skorch was the similarity to the scikit-learn API. However, in the rest of braindecode we lack support. Should we add...
Reduced runtime of `TUHAbonormal` from 2 min on master to 44s. Reduced runtime of `TUH` from 58 min on master to 10 min. master: 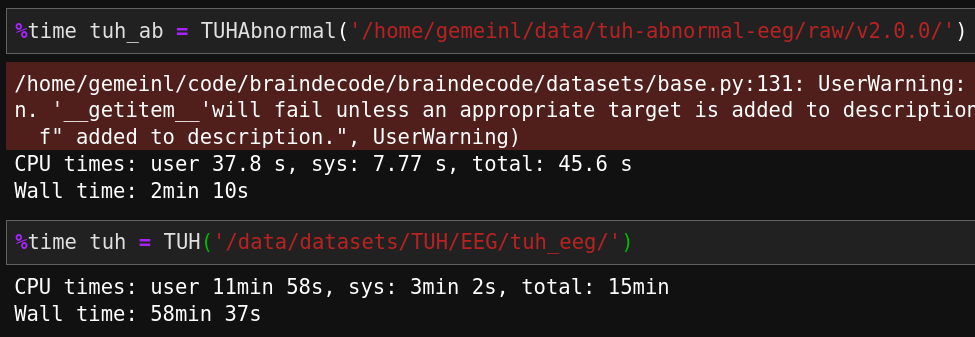 this PR: 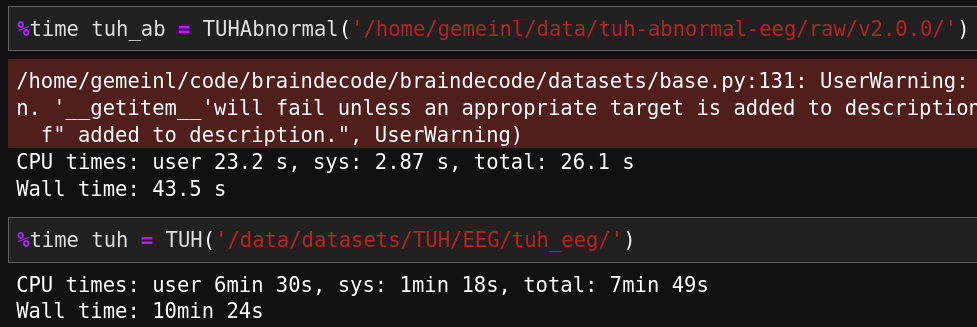
Splitting of datasets (https://github.com/braindecode/braindecode/blob/master/braindecode/datasets/base.py#L160-L162) should probably return an OrderedDict. For example, if data is split for subjects or enumerated runs, then iterating through the returned dictionary should contain data of...