float123
![]()
float123
Thank you very much for your reply,I am currently researching yolov3 to TensorRT,your project has helped me a lot. There is still a question I would like to ask,why do...
量化后的模型 [model.quantized.zip](https://github.com/Tencent/TNN/files/7466043/model.quantized.zip)
> @ float123大佬用的是什么可视化工具啊?感谢! tensorboard and Netron
隔了这么久,我现在来回答一下我之前的问题。 1. 在我的电脑上,旧的master版本在从推理结果获取text_recs的步骤上速度大概是0.15s,新版本要接近1s。具体什么原因没去分析,我直接替换了。 2. 如果采用tensorflow自带插件转tensorrt,1.13版本无法转化bilstm结构,只能转化卷积,但是会增加trt和tf之间切换带了的损耗,速度上和原来基本没区别,甚至可能更慢。1.15和2.0没试过,应该也差不多。 3. 目前我已经在tensorrt 实现了ctpn模型,没设置批量,如果只看推理速度,trt 在fp16下的速度是tf 的4~5倍,整体上速度翻一倍。
May refer to this question: https://github.com/eragonruan/text-detection-ctpn/issues/328#issuecomment-597995967
> @wachout 有用pb文件测试,结果是和ckpt文件一样的吗?我生成的pb文件,加载进去做推断,结果不对。能否请教一下,你是怎么生成的 你好,我也正在尝试在banjin-dev分支下生产pb文件,代码如下: `pb_file = "./data/ctpn.pb" ckpt_file = "./checkpoints_mlt/ctpn_50000.ckpt" output_node_names = ["bbox_pred/Reshape_1", "cls_pred/Reshape_1", "cls_prob"] os.environ["CUDA_VISIBLE_DEVICES"] = "0" with tf.name_scope('input'): input_data = tf.placeholder(dtype=tf.float32, shape=(None, None, None, 3), name='input_data') model =...
> 下午我去看看,做这个有段时间了 发自我的iPhone > […](#) > ------------------ 原始邮件 ------------------ 发件人: float123 发送时间: 2019年8月20日 11:37 收件人: eragonruan/text-detection-ctpn 抄送: wachout , Mention 主题: 回复:[eragonruan/text-detection-ctpn] 生成pb文件 (#328) @wachout 有用pb文件测试,结果是和ckpt文件一样的吗?我生成的pb文件,加载进去做推断,结果不对。能否请教一下,你是怎么生成的 你好,我也正在尝试在banjin-dev分支下生产pb文件,代码如下: `pb_file = "./data/ctpn.pb"...
好久没关注这个问题了,给一个ckpt转pb的方法。首先在找到sess.run里面的输出点,然后print看看是什么,在把ckpt节点都打印出来,找到对应的,就是输出节点。具体方法如下 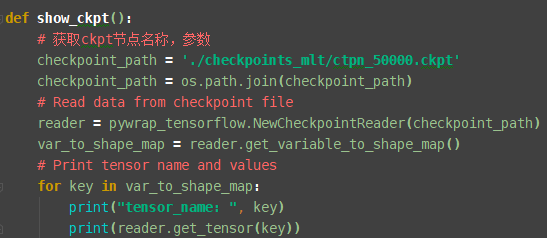 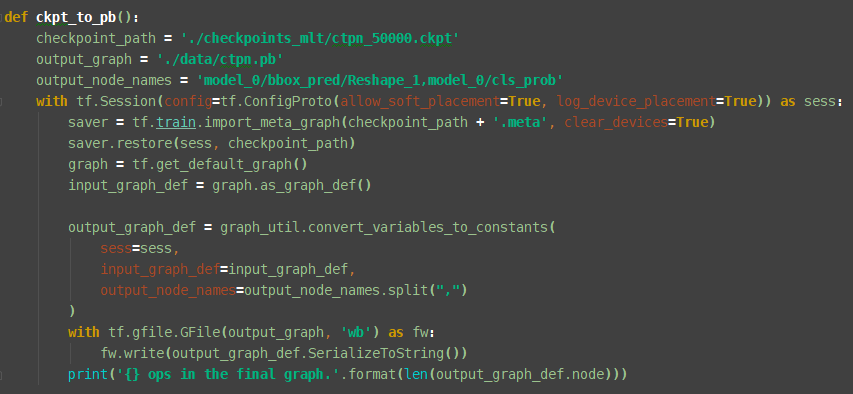 ``` def show_ckpt(): # 获取ckpt节点名称,参数 checkpoint_path = './checkpoints_mlt/ctpn_50000.ckpt' checkpoint_path = os.path.join(checkpoint_path) # Read data from checkpoint file reader = pywrap_tensorflow.NewCheckpointReader(checkpoint_path) var_to_shape_map = reader.get_variable_to_shape_map() # Print tensor name...
我没调用过这个pb文件,转pb主要是为了方便导出参数。我可以大致的写一下,调用pb模型,首先是加载模型,然后是设置输入输出节点,之后是执行推理。把原始模型对应的步骤替换就可以,其他步骤,比如图片处理都是一样的。 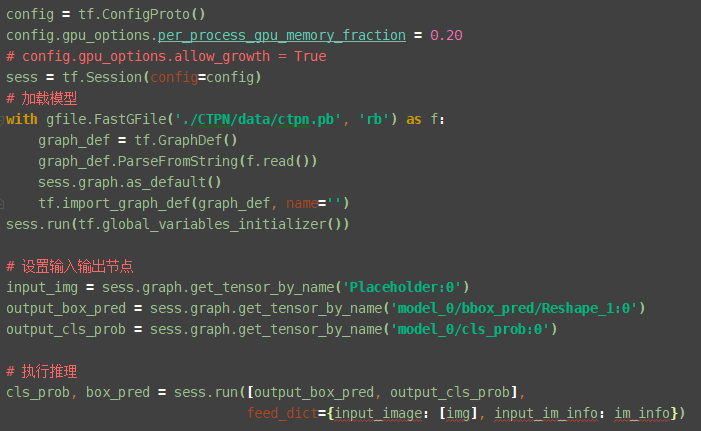 ``` from tensorflow.python.platform import gfile config = tf.ConfigProto() config.gpu_options.per_process_gpu_memory_fraction = 0.20 # config.gpu_options.allow_growth = True sess = tf.Session(config=config) # 加载模型 with gfile.FastGFile('./CTPN/data/ctpn.pb', 'rb') as f: graph_def = tf.GraphDef()...
> @float123 > 感谢你的ckpt 转pb的方法,我之前也是打印的节点,但是没想到要在前面加model_0\,这是什么原因可以解释下吗,打印出来是bbox_pred/Reshape_1 可能是slim自带的命名空间