Yunlin Mao
Yunlin Mao
This issue seems related to the quantization of fp16: ```python # in train_sft.py model = LlamaLM(pretrained=args.pretrain, lora_rank=args.lora_rank, checkpoint=True).to(torch.float16).to(torch.cuda.current_device()) ``` I removed the `to(torch.float16)`, and try to load in 8-bit (remember...
> Here is my solution: In sft.py changed my code like the pic blow: 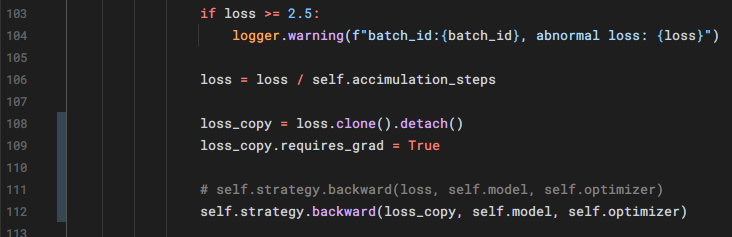 Then my loss got normal The code may be buggy, `loss_copy` is detached from the...
1. 微调后的模型可以使用 ms-swift 集成的eval能力进行评测,指定 `--ckpt_dir` 参数 参考: https://evalscope.readthedocs.io/zh-cn/latest/best_practice/swift_integration.html#id3 2. 自定义评测数据集教程参考:https://evalscope.readthedocs.io/zh-cn/latest/advanced_guides/custom_dataset.html
请参考[基础使用指南](https://evalscope.readthedocs.io/zh-cn/latest/get_started/basic_usage.html) 由于长时间未收到活动,我们将关闭此问题。如果您有任何疑问,请随时重新打开它。如果EvalScope对您有所帮助,欢迎给我们点个STAR以示支持,谢谢!
使用本地模型,请参考:https://evalscope.readthedocs.io/zh-cn/latest/advanced_guides/custom_model.html
麻烦提供下运行的命令和log
请问,尝试更换judge model后还会卡着吗
> Thank you for your feedback! We will close this issue now. If you have any further questions, please feel free to reopen it. If EvalScope has been helpful to...
aAcc是Accuracy per Question,也即 average acc fAcc是Accuracy per Figure qAcc是Accuracy per Question Pair 参考: - 官方文档:https://github.com/tianyi-lab/HallusionBench#metric - 代码实现:https://github.com/open-compass/VLMEvalKit/blob/0697b148c91da9297ed4c06e664f4fb85a63bb94/vlmeval/dataset/utils/yorn.py#L50
现在已经支持embedding/reranker模型评估,也支持RAG端到端的评估,请参考:https://evalscope.readthedocs.io/zh-cn/latest/user_guides/backend/rageval_backend/index.html#