ColossalAI
 ColossalAI copied to clipboard
ColossalAI copied to clipboard
[BUG]: Is it normal to have loss nan after the Stage 1 - Supervised Finetuning?
🐛 Describe the bug
wandb: Synced 6 W&B file(s), 0 media file(s), 0 artifact file(s) and 0 other file(s)
wandb: Waiting for W&B process to finish... (success).
wandb: - 0.010 MB of 0.010 MB uploaded (0.000 MB deduped)
wandb: Run history:
wandb: batch_id ▁▁▂▂▃▃▄▄▅▅▆▆▇▇██
wandb: epoch ▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁
wandb: loss ▁
wandb: lr ███▇▇▆▆▅▄▃▃▂▂▁▁▁
wandb:
wandb: Run summary:
wandb: batch_id 127
wandb: epoch 0
wandb: loss nan
wandb: lr 0.0
wandb:
wandb: Synced 6 W&B file(s), 0 media file(s), 0 artifact file(s) and 0 other file(s)
Is it normal to have nan loss?
Environment
No response
Here are some values of variables in sft.py. When going once gradient optimizing,
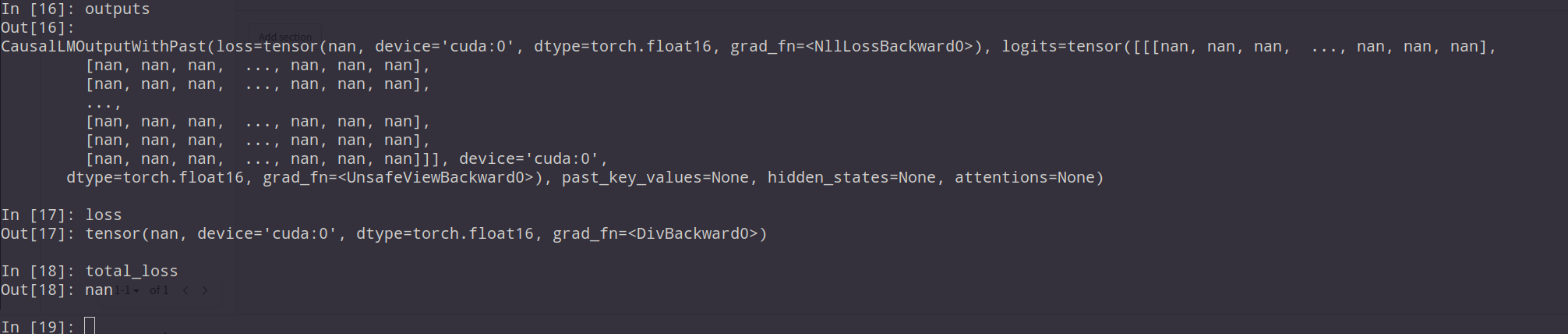 batch_size: 1
strategy: ddp
accimulation_steps: 8
lr: 2e-5
batch_size: 1
strategy: ddp
accimulation_steps: 8
lr: 2e-5
And if DO NOT pass gradient updating (through gradient accumulation), the loss or total_loss would be normal. by the way the strategy change to colossalai_gemini or colossalai_zero2, it would not work.
Bot detected the issue body's language is not English, translate it automatically. 👯👭🏻🧑🤝🧑👫🧑🏿🤝🧑🏻👩🏾🤝👨🏿👬🏿
same logs are seen here
Do you mean when disabling grad_accumulation it will work correctly? How about when set to colossalai_gemini?
This seems to have nothing to do with the accumulation of gradients. In the first few steps, the loss is normal, and then it starts to become nan
is this warning shown in your log?
``use_cache=Trueis incompatible with gradient checkpointing. Settinguse_cache=False`...
/opt/conda/lib/python3.9/site-packages/torch/utils/checkpoint.py:25: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn("None of the inputs have requires_grad=True. Gradients will be None")`
it might be the cause of this issue, while still not solved
This issue seems related to the quantization of fp16:
# in train_sft.py
model = LlamaLM(pretrained=args.pretrain,
lora_rank=args.lora_rank,
checkpoint=True).to(torch.float16).to(torch.cuda.current_device())
I removed the to(torch.float16), and try to load in 8-bit (remember to install the official transformes library), the loss is normal now.
# in llama_lm.py
# try to load in 8-bit
model = LlamaForCausalLM.from_pretrained(pretrained,
load_in_8bit=True,
device_map='auto')
In this way, the model is quantized into 8-bit, but still don't know why the quantization of fp16 results in NaN loss.
@Yunnglin It looks like the optimizer won't work as long as the LoRA parameter is fp16. I hacked into the code and kept the model parameters to fp16 but changed LoRA parameters fp32, then it started to work.
@JThh Looking forward for a fix regarding this! I suspect something is wrong during the lora parameter optimization.
Here is my solution:
In sft.py changed my code like the pic blow:
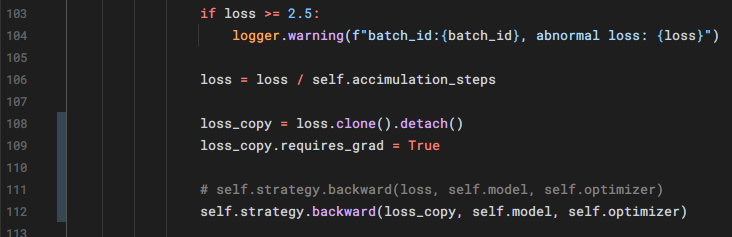 Then my loss got normal
Then my loss got normal
Here is my solution: In sft.py changed my code like the pic blow:
The code may be buggy, loss_copy is detached from the computation graph, so LoRA parameters won't update.
+1 Encounters the same issue when I running the following:
train_sft.py \
--pretrain "llama-7b-hf/" \
--model 'llama' \
--strategy naive \
--log_interval 10 \
--save_path "coati-7B" \
--dataset "instinwild_ch.json" \
--batch_size 1 \
--accimulation_steps 8 \
--lr 2e-5 \
--max_datasets_size 512 \
--max_epochs 1 \
--lora_rank 16
loss became NaN after one step. https://api.wandb.ai/links/yangshawnlong/52wvbbnw
This issue seems related to the quantization of fp16:
# in train_sft.py model = LlamaLM(pretrained=args.pretrain, lora_rank=args.lora_rank, checkpoint=True).to(torch.float16).to(torch.cuda.current_device())I removed the
to(torch.float16), and try to load in 8-bit (remember to install the officialtransformeslibrary), the loss is normal now.# in llama_lm.py # try to load in 8-bit model = LlamaForCausalLM.from_pretrained(pretrained, load_in_8bit=True, device_map='auto')In this way, the model is quantized into 8-bit, but still don't know why the quantization of fp16 results in NaN loss.
Follow the comment and change the loss rate to 8-bit, now I have loss but it never decrease. https://api.wandb.ai/links/yangshawnlong/07idgc0i
This issue seems related to the quantization of fp16:
# in train_sft.py model = LlamaLM(pretrained=args.pretrain, lora_rank=args.lora_rank, checkpoint=True).to(torch.float16).to(torch.cuda.current_device())I removed the
to(torch.float16), and try to load in 8-bit (remember to install the officialtransformeslibrary), the loss is normal now.# in llama_lm.py # try to load in 8-bit model = LlamaForCausalLM.from_pretrained(pretrained, load_in_8bit=True, device_map='auto')In this way, the model is quantized into 8-bit, but still don't know why the quantization of fp16 results in NaN loss.
I remove to.(torch.float16) and set load_in_8bit=True as you do, but I run into this new issue: RuntimeError: Only Tensors of floating point and complex dtype can require gradients
My experience: model.half() adam(eps=1e-8) loss:nan model.half() sgd loss:normal, however, non convergence model.half() adam(eps=1-4) loss:normal, however, non convergence model.half() fp16 loss:normal, however, non convergence model adam(eps=1e-8) loss:normal, convergence Remove .half() can work. I hope this information is useful.
Encounters the nan loss in stage1. my command is :
torchrun --standalone --nproc_per_node=1 train_sft.py
--pretrain "/home/qing/Yahui_Cai/remote_folder/pretrain/llama-7b"
--model 'llama'
--strategy naive
--log_interval 10
--save_path /home/qing/Yahui_Cai/remote_folder/pretrain/Coati-7B
--dataset /home/qing/Yahui_Cai/remote_folder/data/alpaca_merged.json
--batch_size 1
--accimulation_steps 8
--lr 2e-5
--max_datasets_size 512
--lora_rank 16
--max_epochs 1
--grad_checkpoint
~
My experience: model.half() adam(eps=1e-8) loss:nan model.half() sgd loss:normal, however, non convergence model.half() adam(eps=1-4) loss:normal, however, non convergence model.half() fp16 loss:normal, however, non convergence model adam(eps=1e-8) loss:normal, convergence Remove .half() can work. I hope this information is useful.
I try this , but is OOM, my GPU MEM is 24G*1 。
My experience: model.half() adam(eps=1e-8) loss:nan model.half() sgd loss:normal, however, non convergence model.half() adam(eps=1-4) loss:normal, however, non convergence model.half() fp16 loss:normal, however, non convergence model adam(eps=1e-8) loss:normal, convergence Remove .half() can work. I hope this information is useful.
I try this , but is OOM, my GPU MEM is 24G*1 。
V100 32G*4 can work for 7B when batch is 1 and open the activate checkpoint. suggest lora.