Yiqun Liu
![]()
Yiqun Liu
收到。`README.cn.md`的示例代码里面用的中文标点符号,感谢指出,已提PR修复:#788 。
原OP Benchmark里面的2个lerp配置不够典型,故https://github.com/PaddlePaddle/benchmark/pull/1530 将第2个double类型的配置改成了一个实际模型中用到且性能很差的配置。另外PR中还贴了模型中几个其他的配置的性能,可供参考。 OP Benchmark CI性能如下: - 配置一:前向+反向总GPU时间加速比为1.77x,反向GPU时间加速比为2.26x。   - 配置一:pr优化后nvprof结果:  - 配置二:前向+反向总GPU时间加速比为686x,反向GPU时间加速比为1597x。  - 配置二:pr优化后nvprof结果:  优化效果汇总如下表,符合黑客松的验收要求: ---- 若您还有兴趣做进一步性能优化,可以考虑以下几个方面: 1. 目前没有w.shape不是[1]的配置的性能,L123 - L146 BroadcastTensorsKernel + LerpGradKernelImpl可以考虑使用一个BroadcastKernel调用来替换。 2....
@Rayman96 这个DtoD拷贝不是benchmark产生的,你看https://github.com/PaddlePaddle/benchmark/pull/1530 ,我跑的develop的nvprof,并没有这个DtoD拷贝。
 deformable_conv前向性能提升34%,符合黑客松算子优化验收标准。 因OP Benchmark系统中默认只有1个测试配置,建议可以用https://github.com/PaddlePaddle/benchmark/blob/master/api/tests_v2/model_configs/deformable_conv.json 中更多配置验证下性能提升效果。
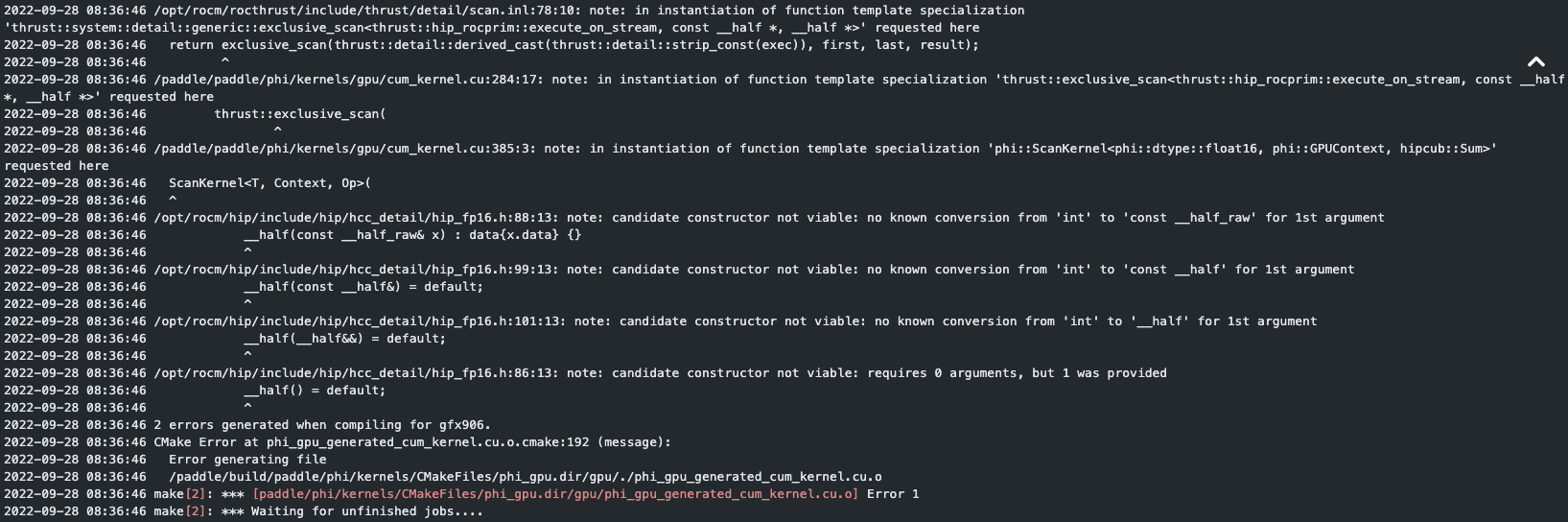 rocm上编译出错,可使用`PADDLE_WITH_HIP`只为CUDA注册float16。  覆盖率CI显示CPU代码覆盖率不过,实际上我们不要求为CPU注册float16,因为CPU float16没有硬件支持,无法加速。
> 还有一种改法是: masked_lm_loss = masked_lm_loss[masked_lm_loss > 0] if (masked_lm_loss.shape[0] == 0): loss = paddle.zeros([], dtype=masked_lm_loss.dtype) loss.stop_gradient = False else: loss = paddle.mean(masked_lm_loss) 这两种改法是等效的吗?能否通过加一些日子把问题数据找出来?
> 1.参数文件(.tar.gz)是经过PC训练生成的吧? 是的。 > 2.模型配置文件mobilenet.py,是个啥东东? 抱歉,目录重新组织过了,所以链接失效了。示例配置程序:https://github.com/PaddlePaddle/Mobile/blob/develop/models/standard_network/mobilenet.py 更多的模型配置,可以在https://github.com/PaddlePaddle/models 找到。 > 3.在PC上使用模型预测时,不需要这个“模型配置文件”吧? 已经生成了merged model后,可直接使用merge model来预测。 > 4.Android APP我在Windows环境下用过Android Studio开发过,请问将paddle库、merge生成的 *.paddle文件分别放到对应的文件夹下,之后就可以在Android Studio 调api了,最后打包成apk,是这样吗? 是的,直接用Android Studio就可以了。Android Studio支持cmake,都已经在build.gradle里面配置好了,Android Studio会自动调用cmake来编译jni代码。并且直接安装apk,运行app即可。
 @Wong4j 这个倒是`reentrant=False`时的已知问题
@imluoxu 多谢您的建议。我们由于着急出结果,暂时缺乏详细描述每个模型的测试方法。我们会在下一个版本里面加强对这个方面的建设。
> 另外这个BERT的测试没有用batch size 78是为啥?用78的话,应该性能可以跑的更高啊? 我们这个测试,不是为了跑出最高的性能,而是测试实际训练的性能。实际使用`batch_size=32`训练,所以我们就只测了`batch_size=32`的情况。