XT-1997
XT-1997
hello, I am hearing from you
你好,谢谢你的回答,我在这里用中文来表达我的一些疑问! 第一点,在论文里面的消融实验,你用的sta_num是481M的,即[4,4,5,4,4]的配置,你在消融实验里说你用single path one shot的方法超网精度能到63.5,但是我照着你的配置跑了一下single path one shot版本,精度只有58,如图, 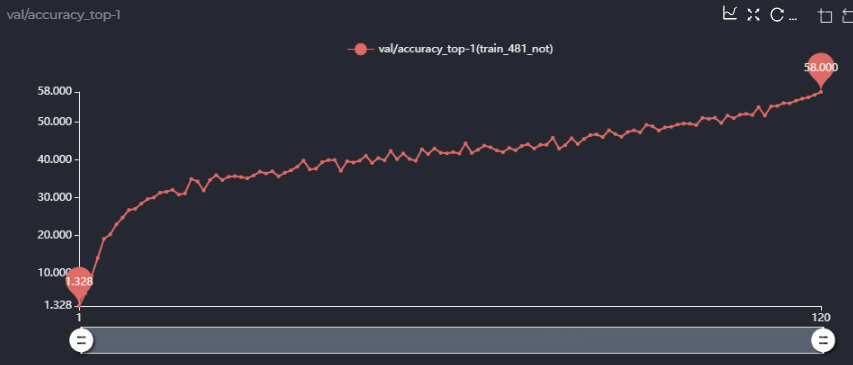 而且,58的精度是在你设定prob为(0.05, 0.2, 0.05, 0.5, 0.05, 0.15)情况下,我也跑了均匀采样的方法,不用你设定的概率,现在没跑完,跑出来的精度如下,可以确定的是精度应该不能到58, 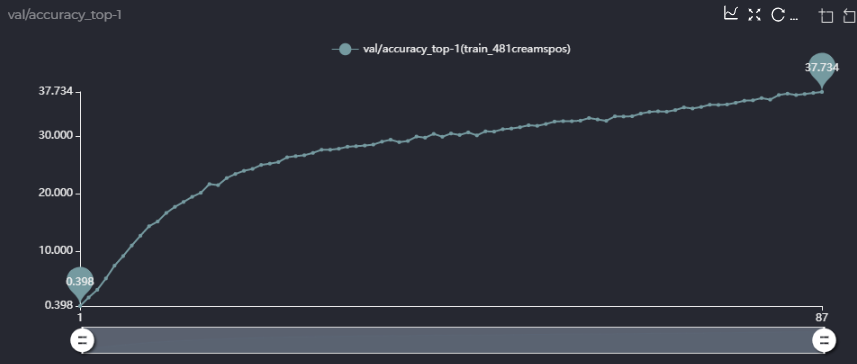 我很想知道你的63.5是怎么跑出来的,是在跑出来的超网上进行了进化搜索算法得到的精度吗?或者直接超网训练得到的精度就能到63.5,如果是这样,你能给我提供你超网训练的LOG文件吗? 第二点,关于meta_value,你的代码里实现如下(PrioritizedBoard.py): 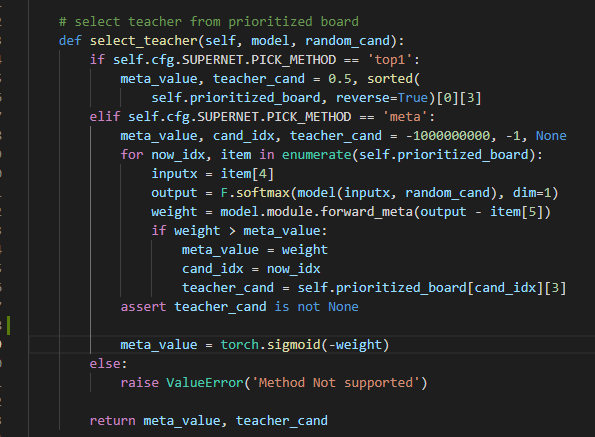 这里是torch.sigmoid(meta_value)还是代码里的torch.sigmoid(-weight)呢,如果是torch.sigmoid(-weight),似乎说不通? 同时,我认为你们将meta_value用来加权valid loss和teacher loss是合理的,但是在子网的梯度反传的时候,由于meta_value的值是由output - item[5]作为输入得到的,那么在loss.backward()里面meta_value是不是也有关于当前子网的gradfn?我认为是不太合理的,是不是代码该这样写呢如下: 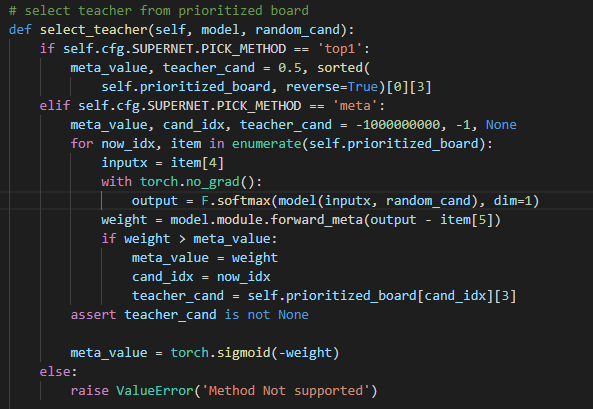 这样loss.backward()时就不会通过meta_value传递梯度到子网了吧,我不确定我理解的是否准确,但是当我这样做的时候跑出来的精度曲线和不这样做精度曲线如下: 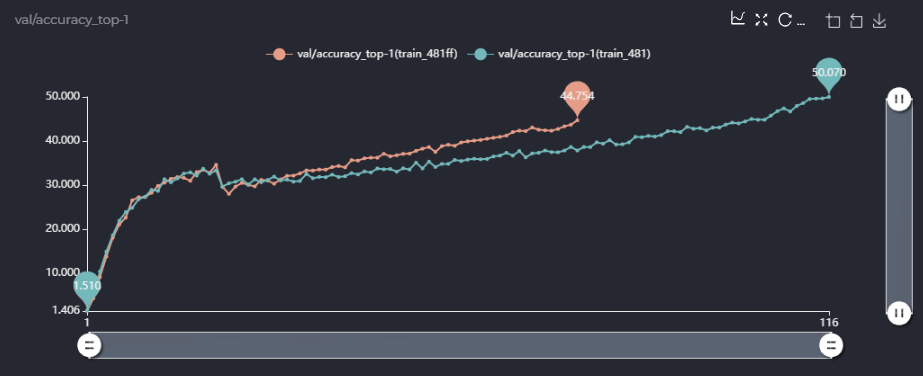 上面是我设置了with torch.no_grad()情况下...
Thanks, but 'all_obbs2d_modified_nearest_has_empty.pkl' this file is not in it. I still can't run it.