WangGuangxin
![]()
WangGuangxin

I encountered a problem that one of my task is blocked when doing memory chunk cleanup. You can find the stack trace in the following snapshot. 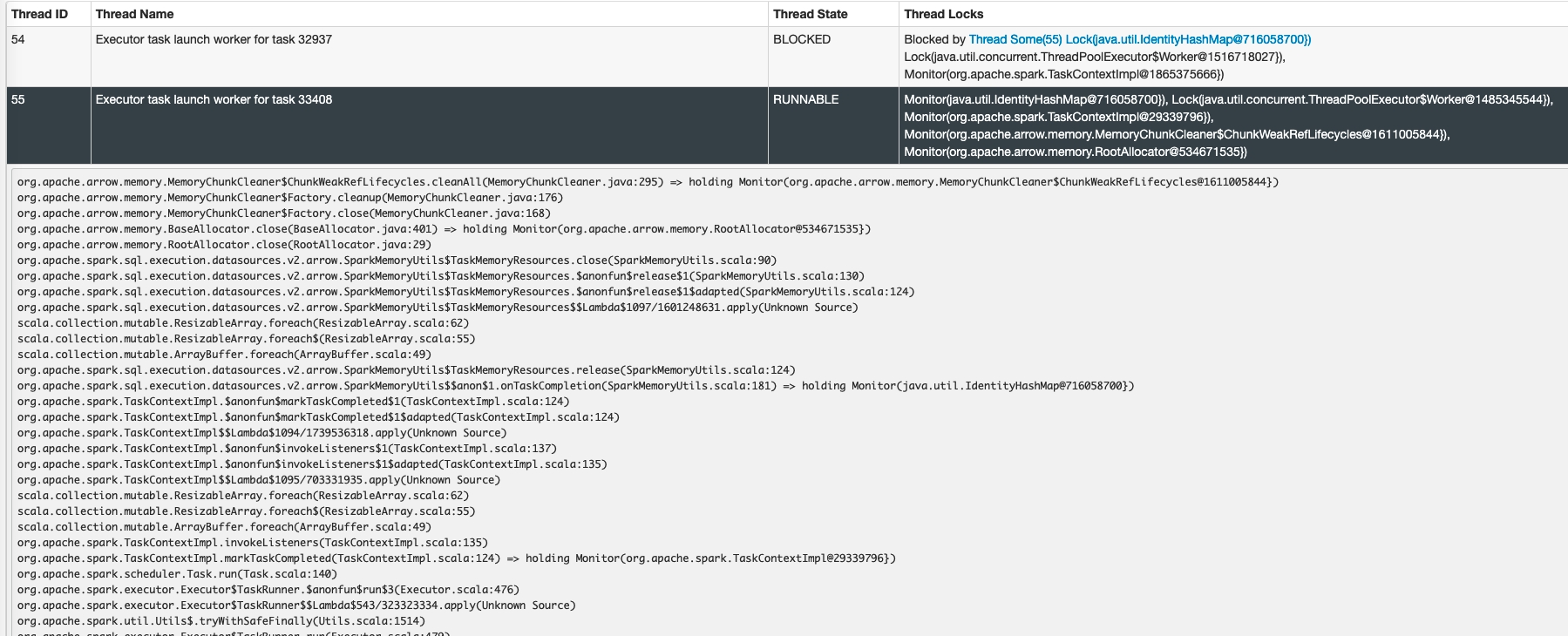 By adding some...
## What changes were proposed in this pull request? Support approx_percentile for VL backend (Fixes: \#4889) ## How was this patch tested? UT
The row vector's encoding for intermediate input can't be guaranteed, since for Spark (with Gluten), the partial agg's result vector maybe flattened in Gluten's Exchange Operator when doing shuffle partition...
Hi, can you share more information about UDF framework and how can we migrate our existing udf?
## What changes were proposed in this pull request? When `spark.gluten.sql.columnar.backend.velox.window.type` is set to `sort`, there should be no extra `SortExec` before `WindowExec` in plan. (Fixes: \#6202) ## How was...
### Backend VL (Velox) ### Bug description When `spark.gluten.sql.columnar.backend.velox.window.type` is set to `sort`, there should be no extra `SortExec` before `WindowExec` in plan. ### Spark version None ### Spark configurations...
## What changes were proposed in this pull request? Enable map_from_array function (Fixes: \#6101) ## How was this patch tested? UT
## What changes were proposed in this pull request? Prevent pushdown filters with unsupported data types to scan node in case the scan fallback to vanilla scan operator (Fixes: \#5953)...
### Backend VL (Velox) ### Bug description We shouldn't pushdown undeterministic filter to scan node ### Spark version None ### Spark configurations _No response_ ### System information _No response_ ###...