topduke
topduke
svtr-tiny训练时单卡batchsize为512,使用4卡,lr为0.0005,如果要更改batchsize,lr随着batchsize线性改变即可,例如,单卡batchsize为256,使用4卡,lr则需改为0.00025。 small base large同理。
如果可以的话,麻烦展示几张实例图片和训练的配置文件,数据量有多少? 图像大小不一定越大越好,建议统计训练数据集的宽高比,高度设置为32或48即可,宽度根据统的计宽高比进行设置,如果图像文本均为水平文本,没有弯曲或者不规则文本,可以不使用STN。 > 请问这个现象是否表明Local mixer 导致感受野过大以及丢失的信息较多导致?Local kernel的设置(7, 11)是否也需要结合训练样本的长度来调整? Local mixer是着重局部特征提取,感受野的设置可以做一些消融调整,一般可以设置为3*3,5*5,7*7,7*11等等,或者尝试将Local mixer设置为Conv, kernel设置为5*5
> 训练配置:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/configs/rec/rec_svtrnet_ch.yml 基于这个适配了训练集的输入(64, 512) 除了改动输入size,还改了其他地方吗? 这种图像建议将input size改为32*320,并且可以加载[中文大模型](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/applications/%E9%AB%98%E7%B2%BE%E5%BA%A6%E4%B8%AD%E6%96%87%E8%AF%86%E5%88%AB%E6%A8%A1%E5%9E%8B.md)。
> 在多个issue中您提到svtr模型不支持变长输入 SVTR整体结构与ViT类似,为backbone+ctchead的结构,,训练时使用了绝对位置编码。绝对位置编码是根据固定的inputsize得到一个位置编码序列,例如32✖️100的inputsize,对应的位置编码的个数为8✖️25,并且随着训练而更新位置编码的信息。如果推理时采用了和训练不一致的inputsize,训练得到的位置编码不能参与推理,会运行报错。 > ppocrv3的SVTR_LCNet是可以输入不同长度的文本图片,请问造成这个区别的原因是什么? PP-OCRv3为backbone(lcnet)+neck(svtr)+ctchead的结构,backbone采用轻量的**全卷积网络**lcnet,没有绝对位置编码。对于48✖️W✖️3(W可变)的输入,lcnet提取得到1✖️W/4✖️D的特征F。neck采取两层svtr的global block,同样没有使用绝对位置编码,特征F经过svtr提取全局特征,最后送入ctchead解码出结果。 > 或者说,我设计一个变长输入的网络时,应该关注哪些问题。 要关注网络是否仅仅接受固定inputsize的输入,比如全卷积网络是可以处理任意大小的输入,没有绝味位置编码的ViT结构也可以。建议深入理解lcnet的代码,会帮助理解全卷积网络为什么可以处理任意大小的输入。
> 1:对于纯粹的SVTR网络结构,是否删除绝对位置编码后就可以作为backbone进行特征提取,最后的网络也支持任意大小的输入。 理论上来说,删除绝对位置编码即可以支持任意大小的输入,但是类ViT的结构缺乏平移不变性的特性,即使理论上支持,实际上结果可能不符合预期。卷积网络能很好的处理任意大小的输入,正是因为卷积操作平移不变性的特性。 > 2:我对于ppocrv3提出的各类新结构,进行排列组合后在公开的数据集中进行了测试。发现性能要明显低于resnet+crnn的组合(ppocrv2)。类似的问题在 #7482 中也有提到。在私有数据集中也是类似的结论,性能最好依然的是resnet+crnn。我想了解下是我哪里没有考虑到吗? 请问这些实验有更详细的配置吗?比如数据集的宽高比统计、样本字符数统计、neck的dim、以及参数量的对比表,这些数据分析可以帮助我们更好的分析实验结果。 从这个表中可以看到,增加neck似乎对精度提升不大(不到1%),按经验来说,不管是svtrneck还是rnnneck,都会对结果有明显的提升(+3-5%)。目前分析,resent+rnn的参数量是要比其他实验大很多,带来了高精度。 建议尝试更多PP-OCRv3的训练策略,例如预训练,蒸馏。
PP-OCRv3优化策略针对轻量的模型,在大模型上有可能不适应。比如ppocrv2的server的服务端模型直接采用了resnet,并不是将lcnet放大到2.0倍,这也是因为lcnet在轻量结构上具有优势,resnet在大模型上具有优势。 如果不考虑参数量和速度,可以尝试将resnet的最后两个阶段修改为svtr_global_block,可以参考PP-OCRv3消融实验: 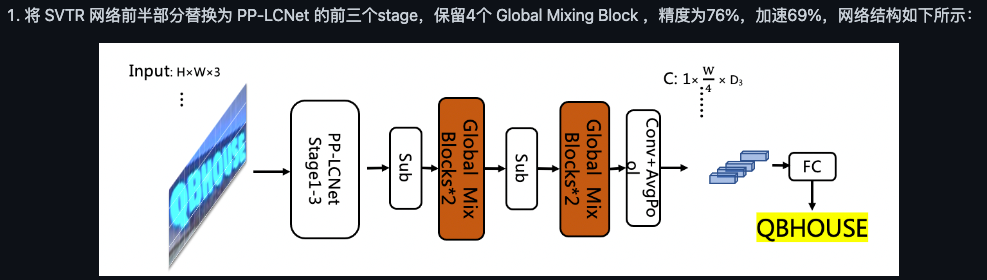,根据经验设置dim和层数。 neck部分可以尝试svtr,head使用ctchead,可以先不使用multi_head结构,注意修改use_guide为false,并且修改svtr neck的dim,和resnet的输出dim同步缩放,不能使用原始dim。 例如: ``` Neck: name: SequenceEncoder encoder_type: svtr dims: 128 depth: 2 hidden_dims: 256 use_guide: False Head: name: CTCHead ``` 这些参数可以自己根据经验设置,原则就是根据backbone同步缩放就行,
等比例缩放
SVTR借鉴Vision Transformer结构,使用了绝对位置编码,无法应对变长的输入,只能识别25个字符以内的文本。因需要统计训练集和测试集样本的宽高比,比如,在中文数据集中发现存在很多宽高比10:1的样本,字符数超过了25,如果直接将这些样本resize到32 100,会造成文本图像的失真,因此我们将图像保留宽高比,高度设为32,如果宽度小于320,这padding,如果宽度大于320,则压缩为320,这样尽可能保留了文本图像的原始信息。 存在问题 由于SVTR使用了绝对位置编码,无法应对变长的输入,一个解决方案即为优化input_size:统计宽高比,例如:1、[3, 32, 100]适应宽高比多数为4:1且单个样本字符数不超过20的数据集;2、如果数据集中存在很多宽高比为10:1样本,则可以将[3, 32, 100]修改为[3, 32, 200]或者[3, 32, 320],也可以参考SVTR中文配置。 如果文本图像中字符个数不确定,但是有的超过了25个,建议采用可以变长输入的模型,比如PP-OCRv3,可以根据图像高宽比设置输入,也可以识别超长的文本。 如果大部分图像都超过了25个字符,建议训练时根据实际情况修改:max_text_length,并将input_size设置为宽高比更大的比例
> 您好,我想请问一下竖向图片SVTR是怎么对它进行resize的呢? 竖向文本进行旋转后再进行resize
> 我使用Benchmarking Chinese中提供的数据集(格式.lmdb)进行训练,发现可视化结果中竖向文本都被识别为一个字了,代码本身是不包含旋转的代码吗?需要先处理数据集? SVTR没有对竖向文本做处理,需要自己添加。具体的可以在,图像读取后进行处理,例如,当图片的高大于1.5倍的宽,可以认为是竖向文本,使用np.rot90(img)即可完成旋转