南栖
![]()
南栖
I accidentally deleted the tokenizer.model when I started download.sh. When I repeated the download, it had already been 403 forbidden, so it could not be downloaded (maybe the download link...
CUDA_VISIBLE_DEVICES=0 python llama_inference.py decapoda-research/llama-7b-hf --wbits 4 --load llama7b-4bit.pt --text "this is llama" Loading model ... Done. Traceback (most recent call last): File "llama_inference.py", line 115, in generated_ids = model.generate( File...
第一步,融合lora 和 原模型: 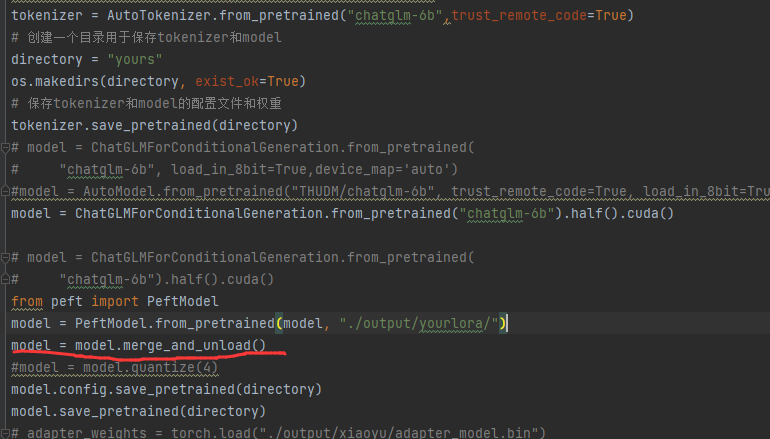 然后融合后推理就行了 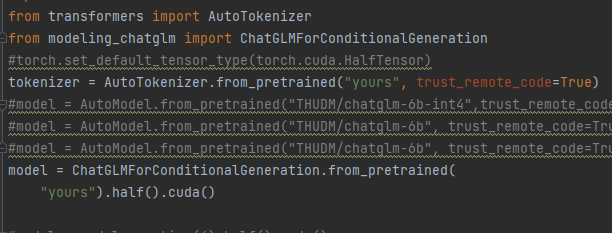 第一步,融合lora 和 原模型后可以用bitsandbytes量化然后推理会显著降低显存,但是效果没尝试,后来试了下好像会让lora失效,所以我觉得这个bitsandbytes量化应该在训练时使用:
关于效果的疑问

为什么vicuna13b只用了7万条指令数据就可以达到chatgpt的90%,而咱们这个项目用了指令数据都上百万条了 ,按理来说大模型的语言迁移能力应该很强啊,还是说vicuna的评测不够全面?
Here are some of the effort I've tried, but it still doesn't work: https://github.com/Cornell-RelaxML/quip-sharp/issues/15 https://github.com/Cornell-RelaxML/quip-sharp/issues/30 https://github.com/Minami-su/quip-sharp-qwen QuIP# method, a weights-only quantization method that is able to achieve near fp16 performance...
``` python build.py --hf_model_dir Qwen-7B-Chat \ > --quant_ckpt_path ./qwen_7b_4bit_gs128_awq.pt \ > --dtype float16 \ > --remove_input_padding \ > --use_gpt_attention_plugin float16 \ > --enable_context_fmha \ > --use_gemm_plugin float16 \ > --use_weight_only...
Thanks for creating this repo. I made a few changes to my GitHub Readme profile. Have a look. https://github.com/Minami-su I would be happy if my profile gets added. 