ChatGLM-Tuning

ChatGLM-Tuning copied to clipboard
加快模型推理速度,代码改进方法(作者看下)
第一步,融合lora 和 原模型:
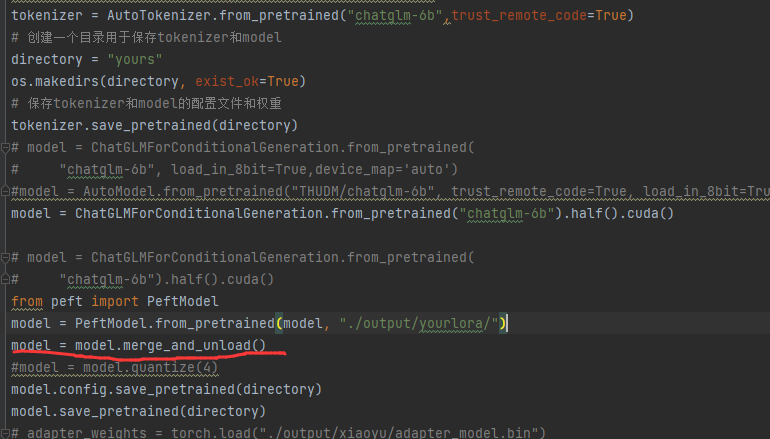 然后融合后推理就行了
然后融合后推理就行了
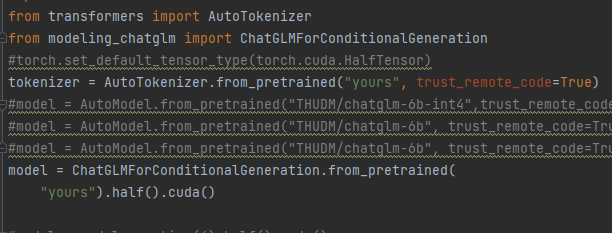 第一步,融合lora 和 原模型后可以用bitsandbytes量化然后推理会显著降低显存,但是效果没尝试,后来试了下好像会让lora失效,所以我觉得这个bitsandbytes量化应该在训练时使用:
第一步,融合lora 和 原模型后可以用bitsandbytes量化然后推理会显著降低显存,但是效果没尝试,后来试了下好像会让lora失效,所以我觉得这个bitsandbytes量化应该在训练时使用:
我用你的方法,模型能加载,但是lora失效了。测试case出的是原本chatglm的回答,没有finetune后的感觉。。。
你的case数据是自己的还是开源gpt模型的问答?
自己的,特定领域,用的特定的prompt。所以能看出来是不是原本的chatglm的。