LUO77123
![]()
LUO77123
好像是每次训练都保存一下.pt权重,太占内存了,这真的是用yolov5改的吗,v5的6.1版本不是这样的吧,其他的一言难尽
> @LUO77123 對,這個原本的 v5 比較好,是用參數控制每隔幾個 epoch 保存或只存 best.pt / last.pt 不過這個好解決,你去把 train.py 中的幾個你不需要的 torch.save 註解掉就好了,我也是這麼做 好的,谢谢。我尝试yolov7.pt权重训练100的epoch,但是效果很差,你们有遇到这种情况吗, 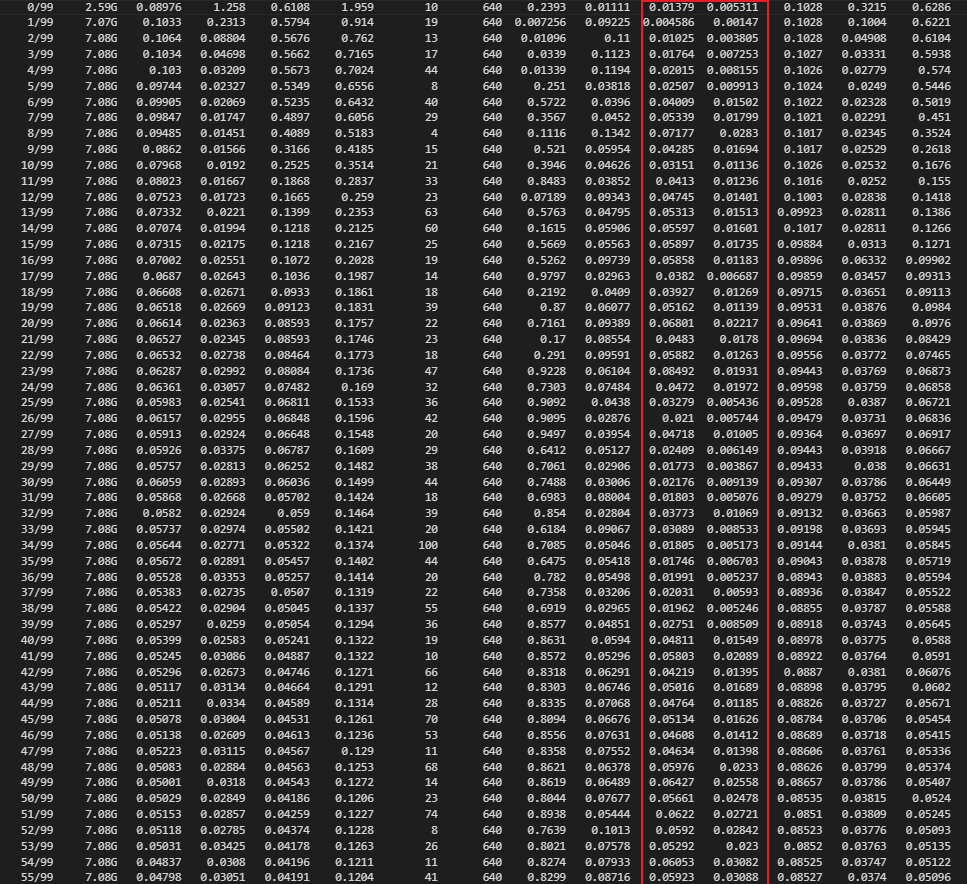
我在11G的1080ti上面训练batchsize=1或者2是,GPU能占到7G,图像尺寸640*640
> Try to use this fix for Validation: #368 > The loss is going to converge. I guess your GPU has no tensor core, you have to set half to...
> Thanks for your interest. > > For Swin, we use `bottleneck=dim // 12`, which can bring similar amount of parameters compared with plain ViT. Thank you for sharing. I...
> > > Thanks for your interest. > > > For Swin, we use `bottleneck=dim // 12`, which can bring similar amount of parameters compared with plain ViT. > >...
> For downstream tasks, please refer #1. We will update related results for downstream tasks after finishing experiments. thanks
> For downstream tasks, please refer #1. We will update related results for downstream tasks after finishing experiments. Hello, there is one last question. If you apply Adapt-MLP to Swin's...
> Yes, you are right. OK, thank you. I'll try the effect. Are you going to open source this downstream image processing method in mid or late June? 好的,谢谢您,我去尝试一下效果,您准备6月中旬还是下旬开源这种下游图像处理的这种方法吗?
> Yes, you are right. Could you tell me where the code for freezing weights is in the video processing code you implemented? I was careless and didn't look carefully....