宝丁

* 资源的缓存机制是提高使用效率的有效方法。他的基本思想是建立一个资源的缓存池,当Webkit需要请求资源的时候,先从资源池中查找是否存在相应的资源,如果有则会从资源池中取出直接使用,如果没有,则会发送真正的请求给服务器,并且把资源缓存起来。这里的缓存指的是内存缓存。 * 根据cookie的时效性可以将cookie分成两种类型,一个是会话型Cookie(session cookie),这些cookie只是保存在内存中,当浏览器退出的时候即清楚这些cookie。如果cookie没有设置失效时间 ,就是会话型cookie。第二种是持续型cookie,就是当浏览器退出的时候,仍保留cookie的内容,这种类型的cookie有一个有效期,在有效期内,每次访问该cookie所属域时,都需要将该cookie发送给服务器,这样服务器可以能够有效的追踪用户的行为 * DNS预取和TCP预连接,DNS 预取的主要思想是利用现有的DNS机制,提前解析网页中可能的网络连接。当用户在浏览页面的时候,可能会提取页面内的超链接,将域名抽取出来,利用较少的CPU和网络带宽来解析这些域名和或IP地址 * 网页开发者,可以从以下方面着手改变以减少因为DNS和TCP连接占用的大量时间 * 减少链接的重定向,会导致多次的DNS解析,并且也会阻碍DNS预取技术的应用 * 利用DNS预取机制,可以在开发过程中,制定需要预取的URL * 避免错误的链接请求 * 在HTML页面中内嵌小型的资源 * 合并一些资源 * 使用浏览器本地磁盘缓存机制 * 启用资源的压缩技术 ## HTML解释器和DOM模型 * DOM的全称是文档对象模型, *...
主要说明的包含三种方式的存储 * 内存存储 * 文件存储 * 数据库存储 ## 内存存储 我们这里的内存存储指的是存储在应用运行时所占用的内存中,而不是指将数据存储在内存中的数据库。常见的是通过应用程序的或者使用的编程语言的数据结构来保存数据,在Go中,可能意味着: arrays、slice、maps或者是struct ``` package main import ( "fmt" ) type Post struct { Id int Content string Author string } var...
首先让我们来看看buffer的模式: 所有从resource传来的数据都会被收集到一个buffer,当所有的数据收集完毕之后就会触发到一个回调函数中 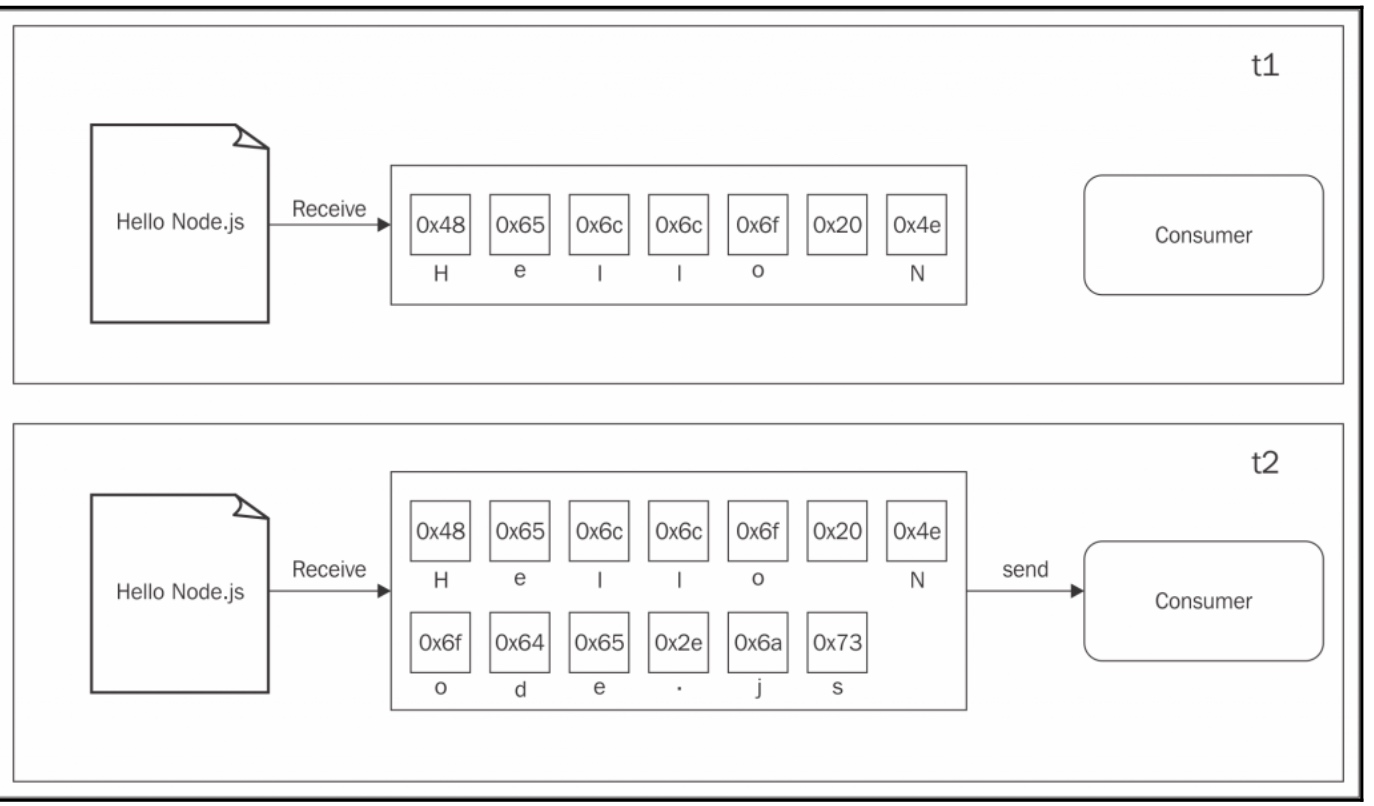 而流可以允许我们边读边写,不会等到所有的数据都获取到后才会消费者 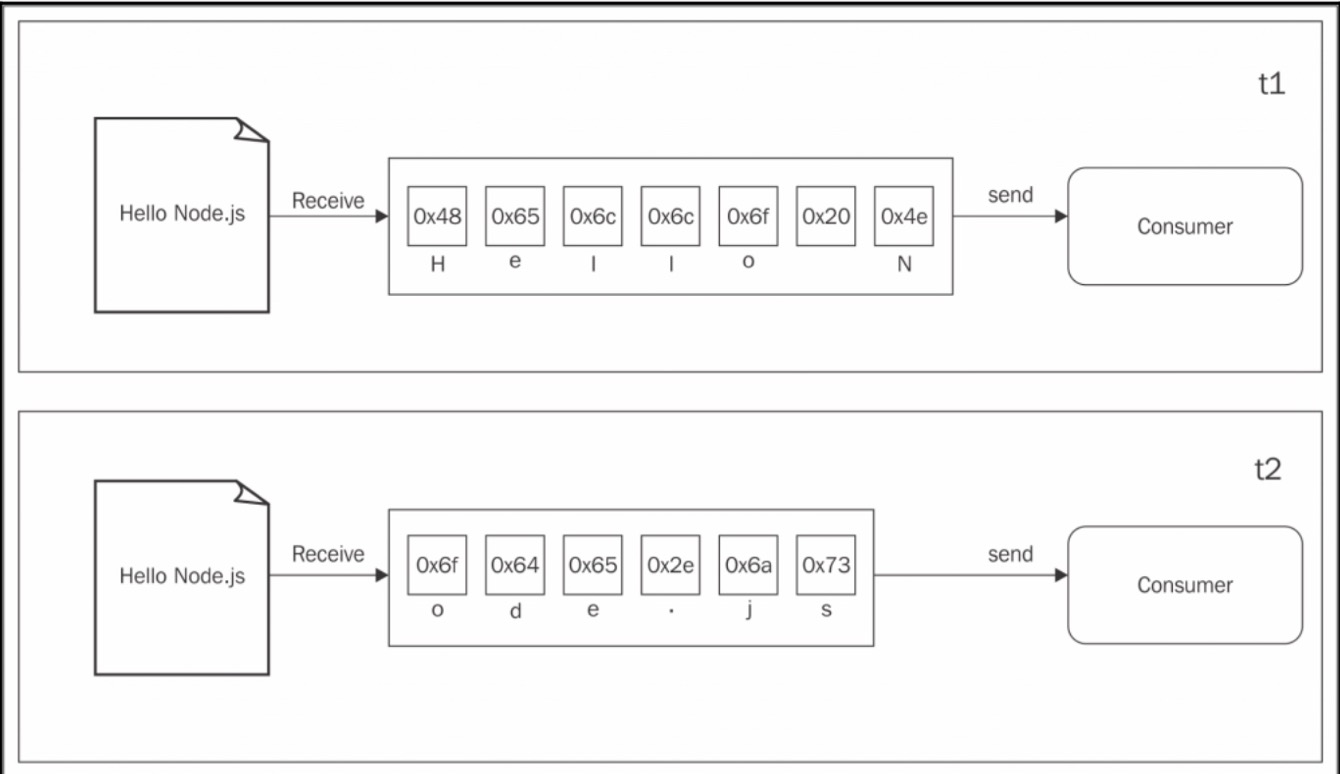 上面的图告诉我们当每块数据从生产者哪里拿到后,会立刻发送给消费者,没有先将所有数据收集到buffer的 所以,这两种方法的区别是什么呢?总结来看,主要有两个: * 空间效率 * 时间效率 而且,Node 中的strem还有一个很重要的优点:可组合性 ## 空间效率 首先,流能够使我们将一些通过buffer不可能做的事情变的可能,比如,去获取一个很大的文件,几十MB或者是几十GB,很明显的,通过创造一个大的buffer去做是不合理的.(注意的是buffer使用的是v8的堆外内存) 加下来通过例子来说明 ``` const fs = require('fs'); const zlib = require('zlib'); const file = process.argv[2];...
```javascript (function() { function printMemory(i) { console.log(i) ; console.log(process.memoryUsage()) } // 记录 Promise 链的长度 var i = 0; function run() { return new Promise(function(resolve) { // 每增加 10000 个 Promise...
在Node中,要实现观察者模式非常的简单,而且内置于`EventEmitter`类中,`EventEmitter`类允许我们注册一个或者多个函数作为监听者,当对应的事件触发后,它们就会被触发  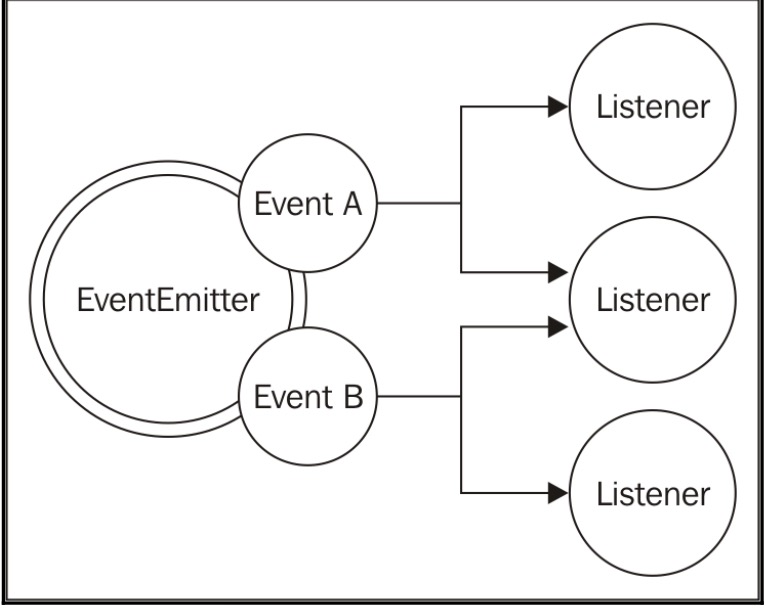 `EventEmitter`是一个原型,可以通过events这个核心模块获取得到 ``` const EventEmitter = require('events').EventEmitter; const eventEmitter = new EventEmitter(); ``` `EventEmitter`内部提供了几个API * `on(event, listener)` 注册监听者 * `once(event, listener)`注册监听者,但是只会触发一次 * `emit(event, [arg1], [...])` 发布一个事件 * `removeListener(event,...
对于epoll有两种触发模式:水平触发LT和边缘触发ET,其中边缘触发“必须”(经评论区提示,这个这个“必须“用的不严谨,说明一下:不是因为程序硬性要求这样,而是从工程实现的角度来看,如果不这么做会产生问题)需要设置所监听的socket为non_blocking。边缘触发,顾名思义,不到边缘情况,是死都不会触发的。EPOLLOUT事件: EPOLLOUT事件在连接时建立时首先触发触发一次,表示可写,其他时候的触发条件为: 1.某次write,写满了发送缓冲区,返回错误码为EAGAIN。 2.对端读取了一些数据,又重新可写了,此时会触发EPOLLOUT。简单地说:EPOLLOUT事件只有socket从unwritable变为writable时,才会触发一次。对于EPOLLOUT事件,必须要将该文件描述符缓冲区一直写满,让 errno 返回 EAGAIN 为止,或者发送完所有数据为止。EPOLLIN事件: EPOLLIN事件则只有当对端有数据写入时才会触发,所以触发一次后需要不断读取所有数据直到读完EAGAIN为止,否则剩下的数据只有在下次对端有写入时才能一起取出来了。设想这样一个场景:接收端接收完整的数据后会向对端发送应答报文,对端才会继续向接收端发送数据,从而触发下一次的EPOLLIN,而这时没有读完socket缓冲区中的所有数据,导致接收端无法向对端发送应答报文,而对端没有收到应答报文,也就不会再发送数据触发下一次的EPOLLIN,而没有下一次的EPOLLIN事件,接收端也就永远不知道此socket缓冲区中还有未读出的数据。(一个完美的死循环) 简单的说:EPOLLIN事件只有对端新数据写入时,才会触发一次。对于EPOLLIN事件,必须要将该文件描述符一直读到空,让 errno 返回 EAGAIN 为止。 总结:现在明白为什么说epoll要求异步socket了吧?如果你的文件描述符如果不是非阻塞的.1.对于读:由于需要一直读直到把数据读完,所以大家在编写程序的时候一般会用一个循环一直读取socket,那这个循环势必会在最后一次阻塞,即没有数据可读的情况下,阻塞式socket会在数据读完之后一直阻塞下去,而非阻塞式的socket则返回<0,并让errno 返回 EAGAIN 。2.对于写,当使用阻塞式socket时,socket的unwritable/writable状态变化没有任何意义!!因为此时无论发送多大的数据write总是会阻塞直到所有数据都发送出去。(也就是说,边缘触发的epoll如果不和非阻塞的socket搭配,使用起来会产生问题)
* -shared 指定生成动态链接库 * -static 指定生成静态链接库 * -fPIC 表示编译为位置独立的代码,用于编译共享库。目标文件需要创建成位置无关码。则产生的代码中,没有绝对地址,全部使用相对地址,故而代码可以被加载器加载到内存的任意位置,都可以正确的执行 * -L 表示要链接的库所在的目录 * -I 指定链接时需要的动态库。编译器查找动态连接库时有隐含的命名规则,即在给出的名字前面加上lib,后面加上.a/.so来确定库的名称 * -Wall 生成所有警告信息 * -ggdb 此选项尽可能的生成gdb的可以使用的调试信息 * -g 编译器在编译的时候产生调试信息 * -c 只激活预处理、编译和汇编,也就是把程序生成目标文件(.O文件) * -WI,options 把参数(options)传递给链接器Id,如果options中间有逗号,就将options分成多个选项,然后传递给链接程序
在学习libuv框架时,编译使用它会出现各种各样的情况,现总结一下我发现的最佳实践 * 第一步 首先在[github](https://github.com/libuv/libuv)上去将代码下载到本地 * 第二步 假设现在你有一个项目是`webserver`,所在的目录是`/tmp/webserver`,  则你可以先到你第一步下载好的目录下,输入命令 ``` git archive --prefix="libuv/" HEAD | (cd /tmp/webserver ; tar -xf -) ``` 然后进入到`/tmp/webserver`下,看目录  * 第三步 进入到`/tmp/webserver/libuv`目录下,然后根据[readme](https://github.com/libuv/libuv/blob/v1.x/README.md)的要求进行编译 ``` ./autogen.sh ./configure...
# 垃圾回收 ## 序 ### GC的定义 GC 是 Garbage Collection的简称,也就是垃圾回收 ### 垃圾的回收 在GC中,**垃圾**指的是**程序不用的内存空间** GC主要做的两件事: * 找到内存空间的垃圾 * 回收垃圾,让程序员再次利用这部分空间 ## 算法篇 ### GC的基本概念 * 对象/头/域 在GC的世界里,对象表示的是**通过应用程序利用的数据的集合** 对象配置在内存空间里,GC把配置好的对象进行移动或销毁操作,因此,对象是GC的基本单位。 一般来说,对象由**头**和**域**构成 * 头 将对象中保存对象本身信息的部分称为”头“...