Autumn_Ning_Blog
 Autumn_Ning_Blog copied to clipboard
Autumn_Ning_Blog copied to clipboard
杂谈
守护进程
普通的进程, 在用户退出终端之后就会直接关闭. 通过 & 启动到后台的进程, 之后会由于会话(session组)被回收而终止进程. 守护进程是不依赖终端(tty)的进程, 不会因为用户退出终端而停止运行的进程.
用node实现守护进程非常简单,实现守护进程的几个传统步骤是
- 创建一个进程A。
- 在进程A中创建进程B,可以用fork等其他方式
- 对进程B进行setsid方法
- A进程退出,B进程由init进程接管,B进程成为守护进程
setsid主要做的事:
- 该进程变成一个新会话的会话领导
- 该进程变成一个新进程组的组长
- 该进程没有控制终端
const spawn = require('child_process').spawn;
const process = require('process');
const p = spawn('node',['b.js'],{
detached : true
});
console.log(process.pid, p.pid);
process.exit(0);
消息队列
一般来说,消息队列有两种场景:一种是发布者订阅者模式;一种是生产者消费者模式。利用redis这两种场景的消息队列都能够实现。定义:
- 生产者消费者模式:生产者生产消息放到队列里,多个消费者同时监听队列,谁先抢到消息谁就会从队列中取走消息;即对于每个消息只能被最多一个消费者拥有。(常用于处理高并发写操作)
- 发布者订阅者模式:发布者生产消息放到队列里,多个监听队列的消费者都会收到同一份消息;即正常情况下每个消费者收到的消息应该都是一样的。(常用来作为日志收集中一份原始数据对多个应用场景)
HTTP文件流
-
http请求头中的content-length 和 Transfer-Encoding:chunked
通常来说,http协议中使用Content-Length这个头来告知我们数据的长度,然后,在数据吓醒的过程中,Content-Length的方式要预先在服务器中缓存所有数据,然后所有数据再一股脑的发给客户端,如果要一边产生数据,一边发给客户端,web服务器就需要使用Transfer-Encoding: chunked 这样的方式要代替Content-Length (Node最大的头大小是80KB)
-
http前后端交互类型采用Content-Type:application/octet-stream的作用
二进制文件
-
application/x-www-form-urlencoded
最常见的POST提交数据的方式,浏览器的原生form表单,如果不设置enctype属性,那么最终会以application/x-www-form-urlencoded方式提交数据,
POST http://www.example.com HTTP/1.1 Content-Type: application/x-www-form-urlencoded;charset=utf-8 title=test&sub%5B%5D=1&sub%5B%5D=2&sub%5B%5D=3 -
application/multipart/form-data
我们使用表单上传文件时,必须让
process.nextTick setTimeout setImmediate
┌───────────────────────┐
┌─>│ timers │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ I/O callbacks │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ idle, prepare │
│ └──────────┬────────────┘ ┌───────────────┐
│ ┌──────────┴────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └──────────┬────────────┘ │ data, etc. │
│ ┌──────────┴────────────┐ └───────────────┘
│ │ check │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
└──┤ close callbacks │
└───────────────────────┘
- timers: this phase executes callbacks scheduled by setTimeout() and setInterval().
- I/O callbacks: executes almost all callbacks with the exception of close callbacks, the ones scheduled by timers, and setImmediate().
- idle, prepare: only used internally.
- poll: retrieve new I/O events; node will block here when appropriate.
- check: setImmediate() callbacks are invoked here.
- close callbacks: e.g. socket.on('close', ...).
process.nextTick() 并不属于 Event loop 中的某一个阶段, 而是在 Event loop 的每一个阶段结束后, 直接执行 nextTickQueue 中插入的 "Tick", 并且直到整个 Queue 处理完
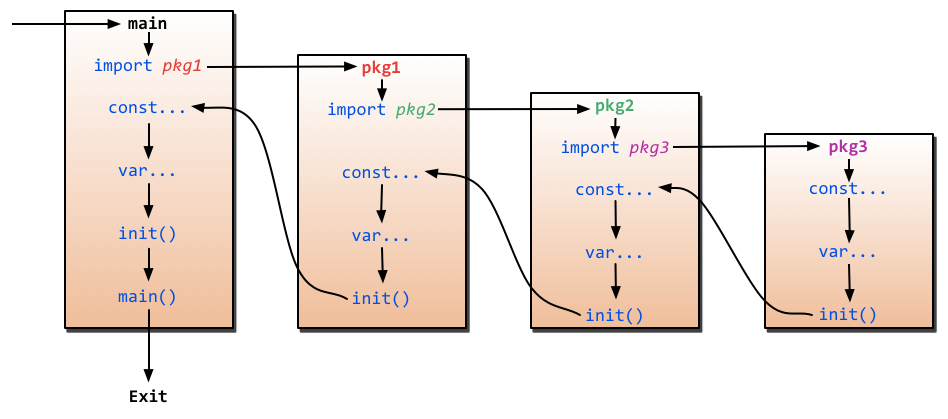
Go语言里的make、new操作
make 用于内建类型(map、slice和channel)的内存分配,new用于各种类型的内存分配
内建函数new本质上说跟其他语言中的同名函数功能一样:new(T)分配了零值填充的T类型的内存空间,并且返回其地址,即返回了一个指针
内建函数make(T, args)与new(T)有着不同的功能,make只能slice、map和channel,并且返回一个有初始值的T类型

Go的if还有一个强大的地方就是条件判断语句里面允许声明一个变量,这个变量的作用域只能在该条件逻辑快内,其他地方就不起作用了
// 计算获取值x,然后根据x返回的大小,判断是否大于10。
if x := computedValue(); x > 10 {
fmt.Println("x is greater than 10")
} else {
fmt.Println("x is less than 10")
}
//这个地方如果这样调用就编译出错了,因为x是条件里面的变量
fmt.Println(x)
Go语言中的defer语句,你可以在函数中添加多个defer语句。当函数执行到最后时,这些defer语句会按照逆序执行,最后该函数返回。特别是当你在进行一些打开资源的操作时,遇到错误需要提前返回,在返回前你需要关闭相应的资源,不然很容易造成资源泄漏问题
func ReadWrite() bool {
file.Open("file")
// 做一些工作
if failureX {
file.Close()
return false
}
if failureY {
file.Close()
return false
}
file.Close()
return true
}
使用defer之后
func ReadWrite() bool {
file.Open("file")
defer file.Close()
if failureX {
return false
}
if failureY {
return false
}
return true
}
goroutine是Go并发设计的核心,goroutine说到底其实是协程,但是它比线程更小,十几个goroutine可呢个体现在底层就是五六个线程,Go语言内部帮你实现了这些goroutine之间的内存共享。执行goroutine只需极少的栈内存,会根据相应的数据伸缩。
goroutine是通过Go的runtime管理的一个线程管理器
mysql中的char和varchar的区别
在mysql中这两者都是用来存储字符串的类型,但是char的话长度不变而varchar的长度是可以变化的
char(M)类型的数据列里,每个值都占用M个字节,如果某个长度小于M,MySQL就会在它的右边用空格字符补足.(在检索操作中那些填补出来的空格字符将被去掉)在varchar(M)类型的数据列里,每个值只占用刚好够用的字节再加上一个用来记录其长度的字节(即总长度为L+1字节)