Autumn_Ning_Blog
 Autumn_Ning_Blog copied to clipboard
Autumn_Ning_Blog copied to clipboard
Published
20 hours ago •
 wangning0
wangning0
简单谈谈Buffer和Stream在空间和时间效率上的比较
trafficstars
首先让我们来看看buffer的模式: 所有从resource传来的数据都会被收集到一个buffer,当所有的数据收集完毕之后就会触发到一个回调函数中
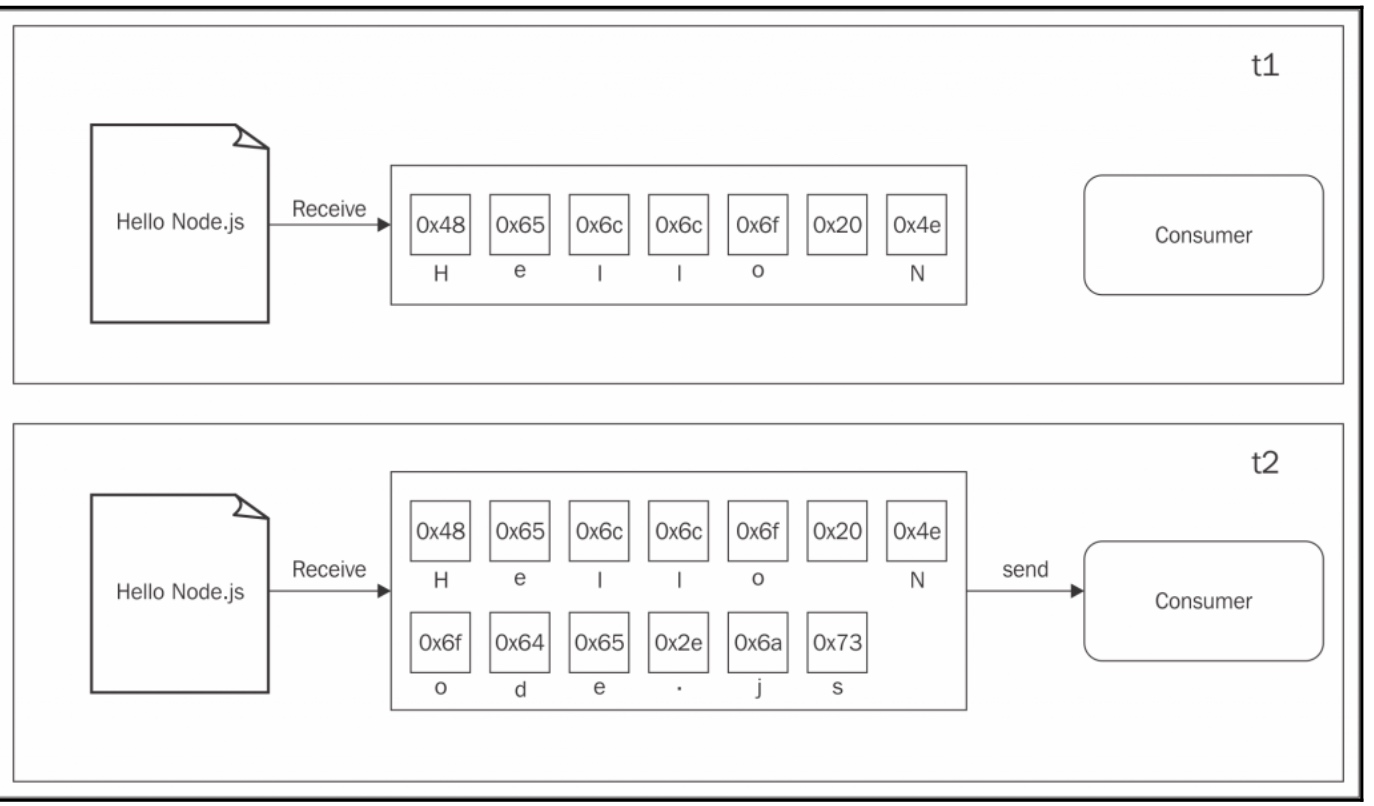
而流可以允许我们边读边写,不会等到所有的数据都获取到后才会消费者
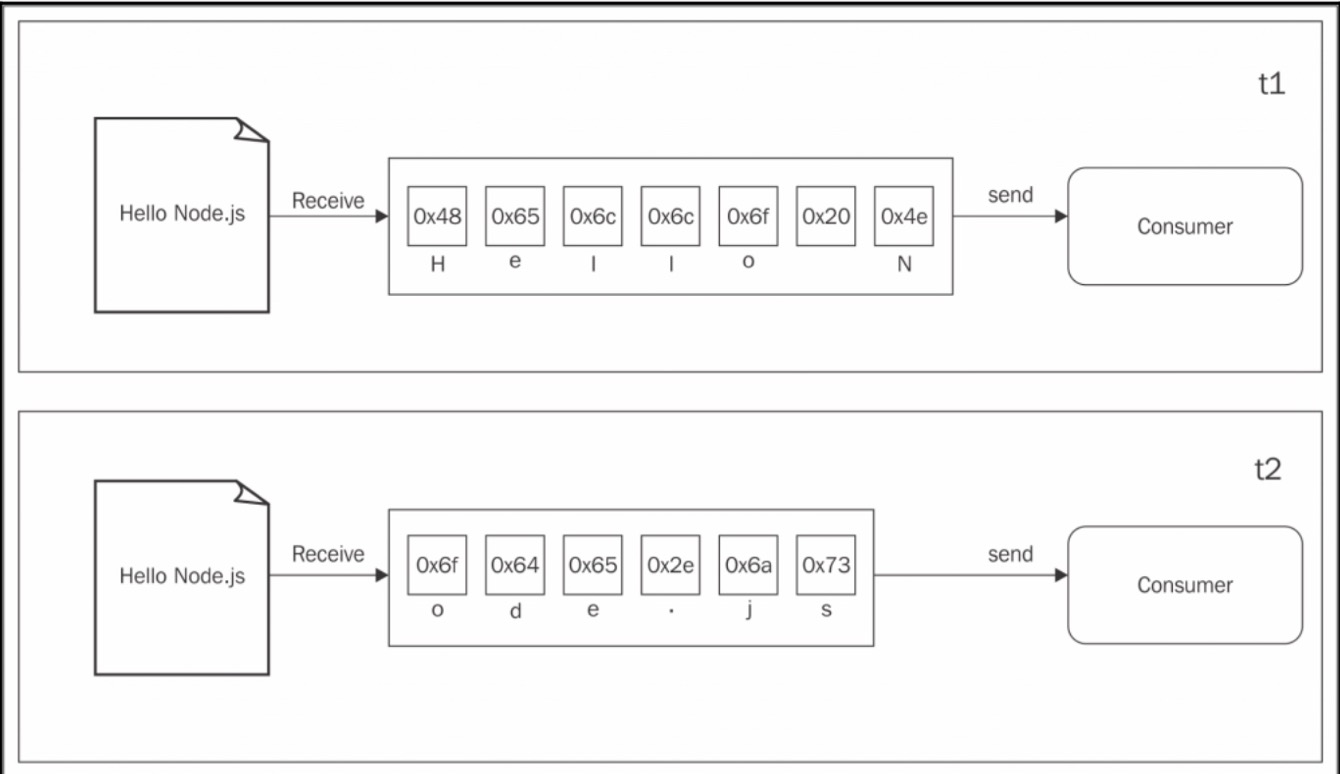
上面的图告诉我们当每块数据从生产者哪里拿到后,会立刻发送给消费者,没有先将所有数据收集到buffer的
所以,这两种方法的区别是什么呢?总结来看,主要有两个:
- 空间效率
- 时间效率
而且,Node 中的strem还有一个很重要的优点:可组合性
空间效率
首先,流能够使我们将一些通过buffer不可能做的事情变的可能,比如,去获取一个很大的文件,几十MB或者是几十GB,很明显的,通过创造一个大的buffer去做是不合理的.(注意的是buffer使用的是v8的堆外内存)
加下来通过例子来说明
const fs = require('fs');
const zlib = require('zlib');
const file = process.argv[2];
const time = Date.now();
fs.readFile(file, (err, buffer) => {
zlib.gzip(buffer, (err, buffer) => {
fs.writeFile(file + '.gz', buffer, err => {
console.log(Date.now() - time);
console.log('file successfully compressed');
})
})
})
const fs = require('fs');
const zlib = require('zlib');
const file = process.argv[2];
const time = Date.now();
fs.createReadStream(file)
.pipe(zlib.createGzip())
.pipe(fs.createWriteStream(`${file}.gz`))
.on('finish', () => {
console.log(Date.now() - time);
console.log('file successfully compressed');
})
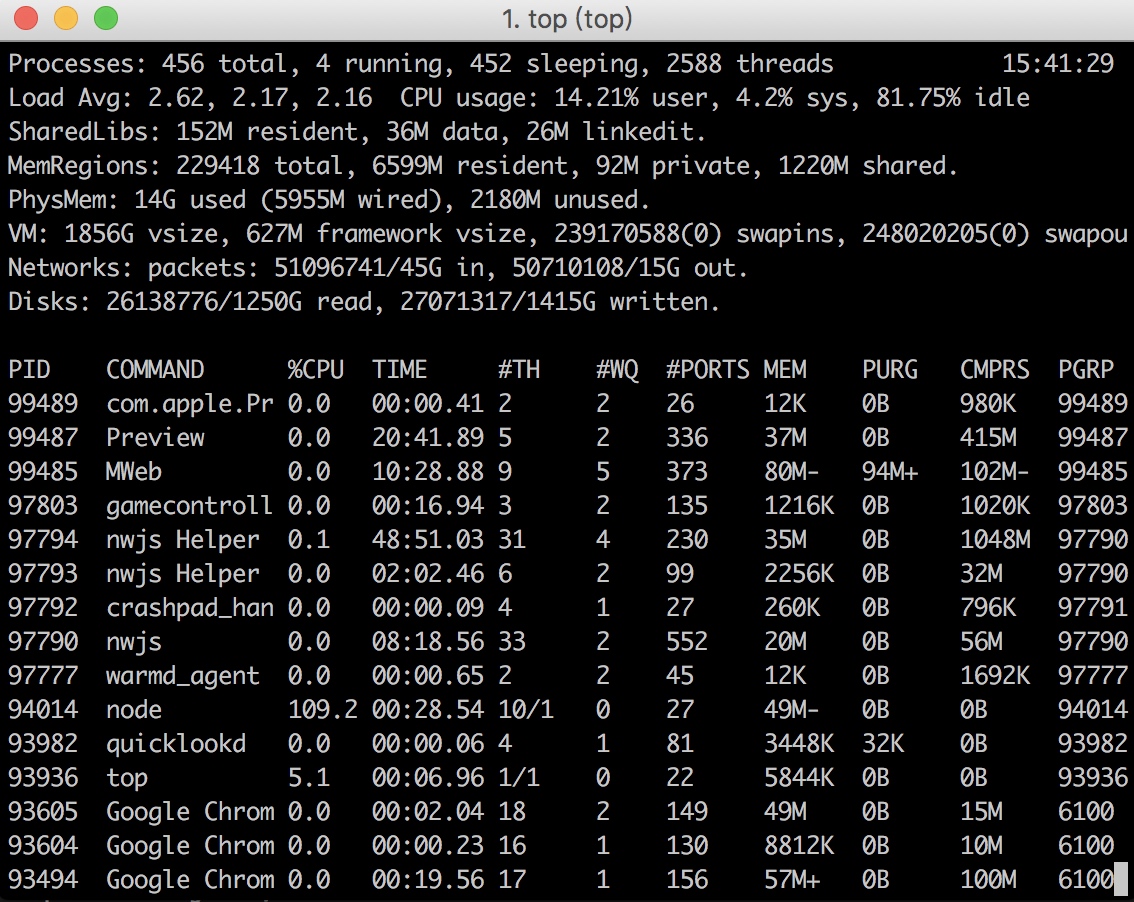
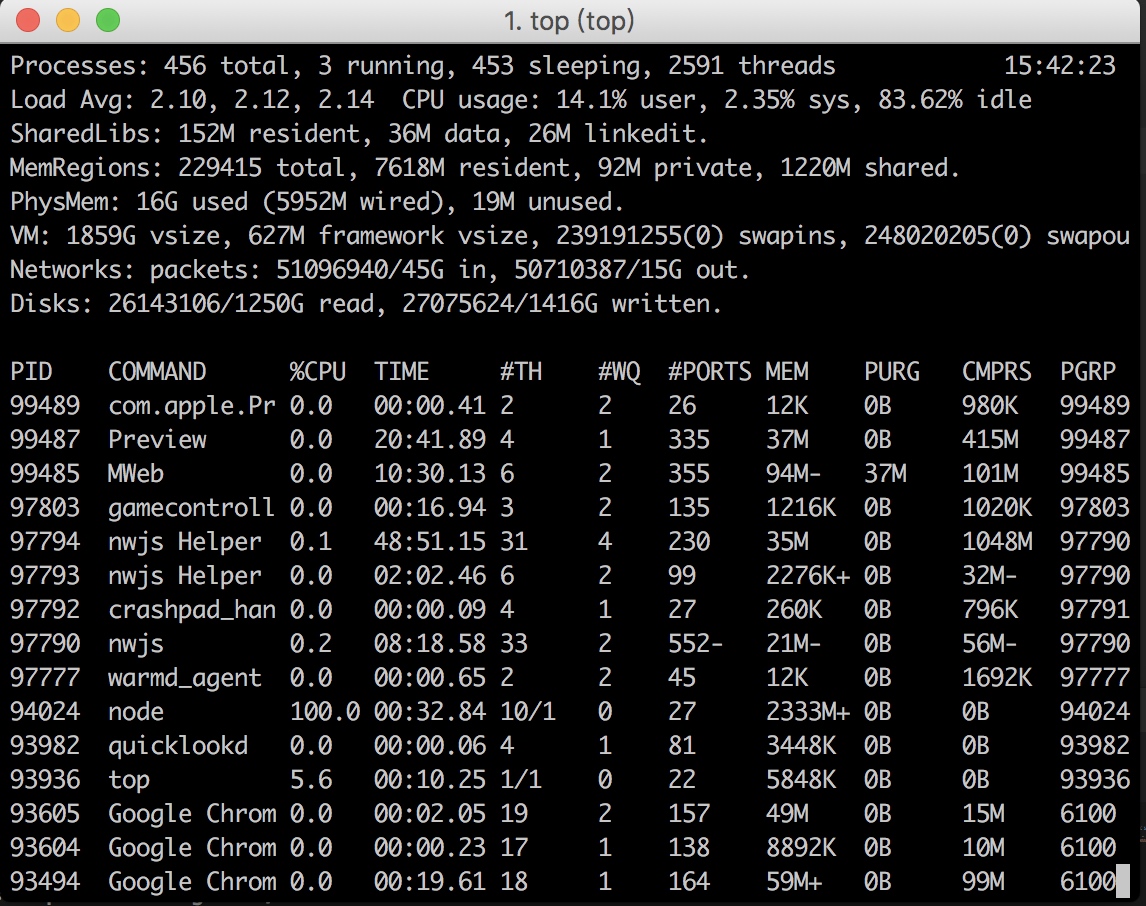
通过top命令我们可以和明显的看出node使用内存的变化,相差几很大,用buffer对于空间是一个很大的浪费
时间效率
现在让我们考虑一个应用场景,压缩一个文件然后上传到线上的http服务器上,然后解压保存到文件系统中,如果我们的客户端使用的是bufferAPI,那么只有当整个文件都读取并压缩了才开始上传,同样的,解压过程只有当接收到了所有的压缩文件才会开始解压。
如果是使用流,是一个更好的解决方案,因为我们可以一边读取一边压缩一边发送给服务端,服务端就可以一边读取一边解压
// 使用流的方法
// client.js
const fs = require('fs');
const zlib = require('zlib');
const http = require('http');
const path = require('path');
const crypto = require('crypto');
const file = process.argv[2];
const server = process.argv[3];
const options = {
protocol: "http:",
hostname: server,
path: '/',
port: 3000,
method: 'PUT',
headers: {
filename: path.basename(file),
'Content-Type': 'application/octet-stream',
'Content-Encoding': 'gzip',
time: Date.now()
}
}
const req = http.request(options, res => {
console.log('Server response: ' + res.statusCode);
})
fs.createReadStream(file)
.pipe(zlib.createGzip())
.pipe(crypto.createCipher('aes192', 'secret'))
.pipe(req)
.on('finish', () => {
console.log('File successfully sent');
})
// server.js
const fs = require('fs');
const http = require('http');
const zlib = require('zlib');
const crypto = require('crypto');
const server = http.createServer((req, res) => {
const filename = req.headers.filename;
const time = req.headers.time;
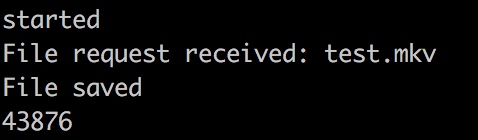
console.log('File request received: ' + filename);
let index = 0;
req
.pipe(crypto.createDecipher('aes192', 'secret'))
.pipe(zlib.createGunzip())
.pipe(fs.createWriteStream(`server-${filename}`))
.on('finish', () => {
res.writeHead(201, {'Content-Type': 'text/plain'});
res.end('over');
console.log('File saved');
console.log(Date.now() - time);
})
})
server.listen(3000, () => {
console.log('started');
})
进行上传一个1.3G左右的文件,运行后的时间可以看出时间差为
接下来我们用buffer的形式来试一试
// client.js
const fs = require('fs');
const http = require('http');
const zlib = require('zlib');
const path = require('path');
const filename = process.argv[2];
const server = process.argv[3];
const options = {
port: 3001,
hostname: server,
method: 'PUT',
protocol: 'http:',
headers: {
filename: path.basename(filename),
'Content-Encoding': 'gzib',
time: Date.now()
}
}
const req = http.request(options, (res) => {
console.log('client done');
})
fs.readFile(filename, (err, buffer) => {
console.log('获取文件完毕\n');
console.log('开始压缩');
zlib.gzip(buffer, (err, buffer) => {
console.log('压缩完毕');
req.write(buffer);
req.end();
})
})
req.on('error', (err) => {
console.log(err);
})
req.on('data', (data) => {
console.log(data, 'data');
})
// server.js
const fs = require('fs');
const http = require('http');
const zlib = require('zlib');
const buffer_lists = [];
let size = 0;
const server = http.createServer((req, res) => {
let index = 0;
const filename = req.headers.filename;
const time = req.headers.time;
req.on('data', function(chunk) {
buffer_lists.push(chunk);
size += chunk.length;
});
req.on('end', function() {
res.end('OK');
const buffer = Buffer.concat(buffer_lists, size);
zlib.gunzip(buffer, (err, buffer) => {
fs.writeFile(`server-${filename}`, buffer, (err) => {
console.log(Date.now() - time);
})
})
})
})
server.listen(3001, () => {
console.log('started');
});
上传同样的大小的文件,运行后看看所需要的时间

前后比较下可以得出,流的时间效率还是要高于buffer的时间效率的
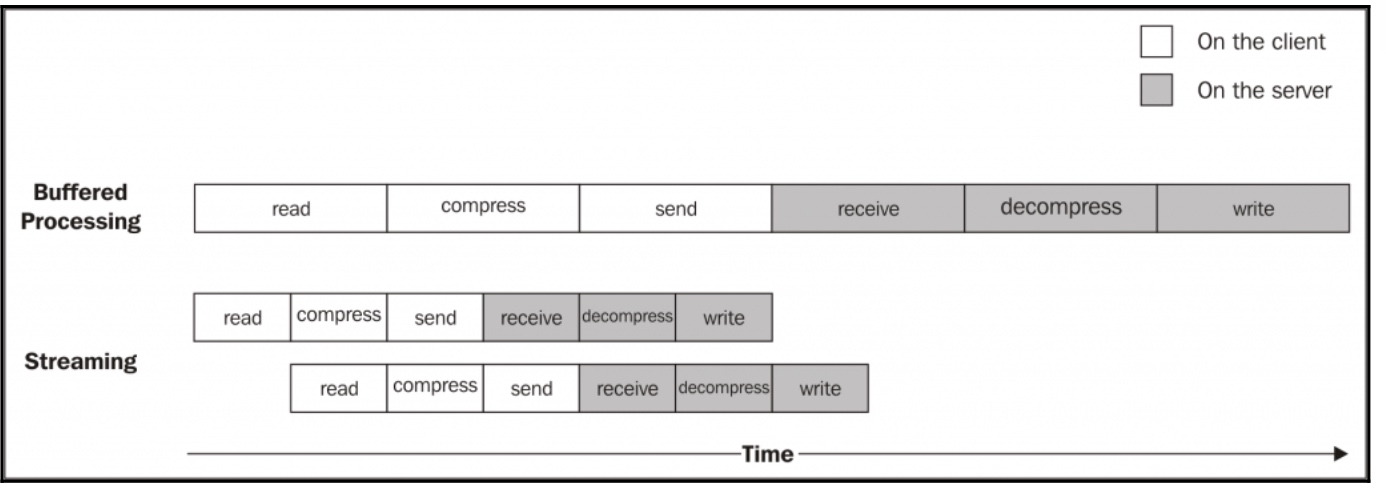
上图可以比较好的描述这两种方法在时间上的效率