deeplabv3-plus-pytorch
 deeplabv3-plus-pytorch copied to clipboard
deeplabv3-plus-pytorch copied to clipboard
这是一个deeplabv3-plus-pytorch的源码,可以用于训练自己的模型。
请问使用您提供的VOC12+SBD数据集时,需要对标签进行像素点的再处理才能预测吗,比如背景的像素点值为0,目标的像素点值为255需要改成,背景的像素点值为0,目标的像素点值为1。
你好,我在训练自己的数据集和预测的时候出现了一些问题。 我使用的是公开数据集CrackForest,它提供的标签是使用matlab标注的,转换为png图片后,我运行了voc_annotation.py文件:  可以看到格式是没有问题的,背景像素点的值为0,目标像素点的值为1 然后开始训练,运行train.py(我的所有需要改num_classes的地方,都改成了num_classes=2),发现模型收敛的非常快,几乎第5个epoch就已经收敛完了,loss一直稳定在0.5左右,mIou的值一直为49.18。   然后进行预测,运行predict.py文件,可以发现整个图片都被预测为了背景:  请问你知道这样的问题该如何解决呢?如果想用labelme手动重新标注不太现实,虽然CrackForest只是一个包含156张图片的小数据集,但是我后面还想训练CRACK500这样的大数据集,几千张图片,其数据标签也是用matlab标注的。 期待大佬的回复
参数量问题

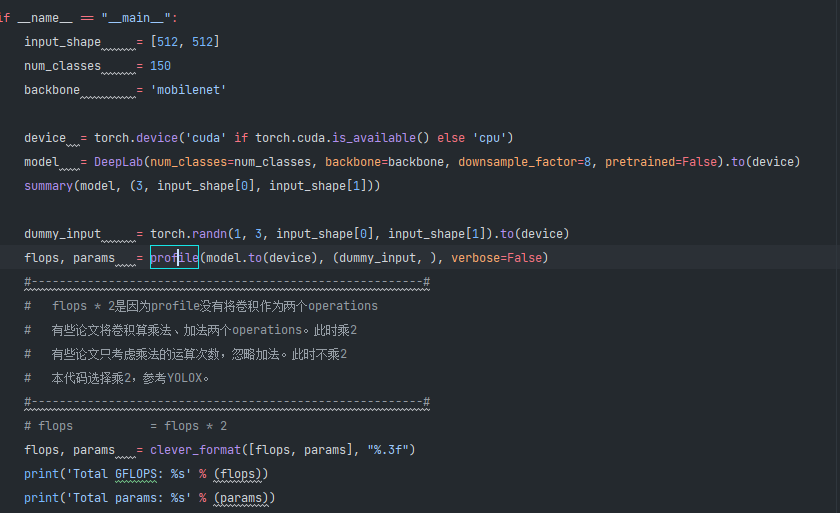  参数量只有5.85M,这个不太正常太小了呀,请问一下我该从那个方向去排查一下?
首先是显示没有载入 Fail To Load Key: ['cls_conv.weight', 'cls_conv.bias'] …… Fail To Load Key num: 2 然后报错 RuntimeError: Input type (torch.cuda.DoubleTensor) and weight type (torch.cuda.HalfTensor) should be the same 求大佬帮忙 T-T