Runist
> In addtion, did you try to use a large scale neural network training by a first-order approximation. Can it get a better result on dataset like miniImageNet? I think...
> > > In addtion, did you try to use a large scale neural network training by a first-order approximation. Can it get a better result on dataset like miniImageNet?...
> > > > > In addtion, did you try to use a large scale neural network training by a first-order approximation. Can it get a better result on dataset...
> 好吧,所以我才希望看到她本人来回答一下。 根据李宏毅教授的讲解,他是把二阶导近似等效为0或1。但是这样对结果的精度不好。
> > > 好吧,所以我才希望看到她本人来回答一下。 > > > > > > 根据李宏毅教授的讲解,他是把二阶导近似等效为0或1。但是这样对结果的精度不好。 > > 这个有讲义资料吗?求地址啊 B站上搜“李宏毅”第一个2020的你拉到下面有个Meta-Learning章节的,就是了
同问,请问你解决了嘛? > 想问一下如何训练可以得到您给出的在voc上77mAP的权重?可以问一下训练策略吗?我在你的代码中注释了对预训练文件的引入,直接使用原始ResNet网络进行train.py文件中100epoch的训练,得到的训练效果很差?想问怎样可以训练出和您相同的voc的结果呢?
> 呃,主要是我试了你用pretrain=True也是这样30%的map
# Train 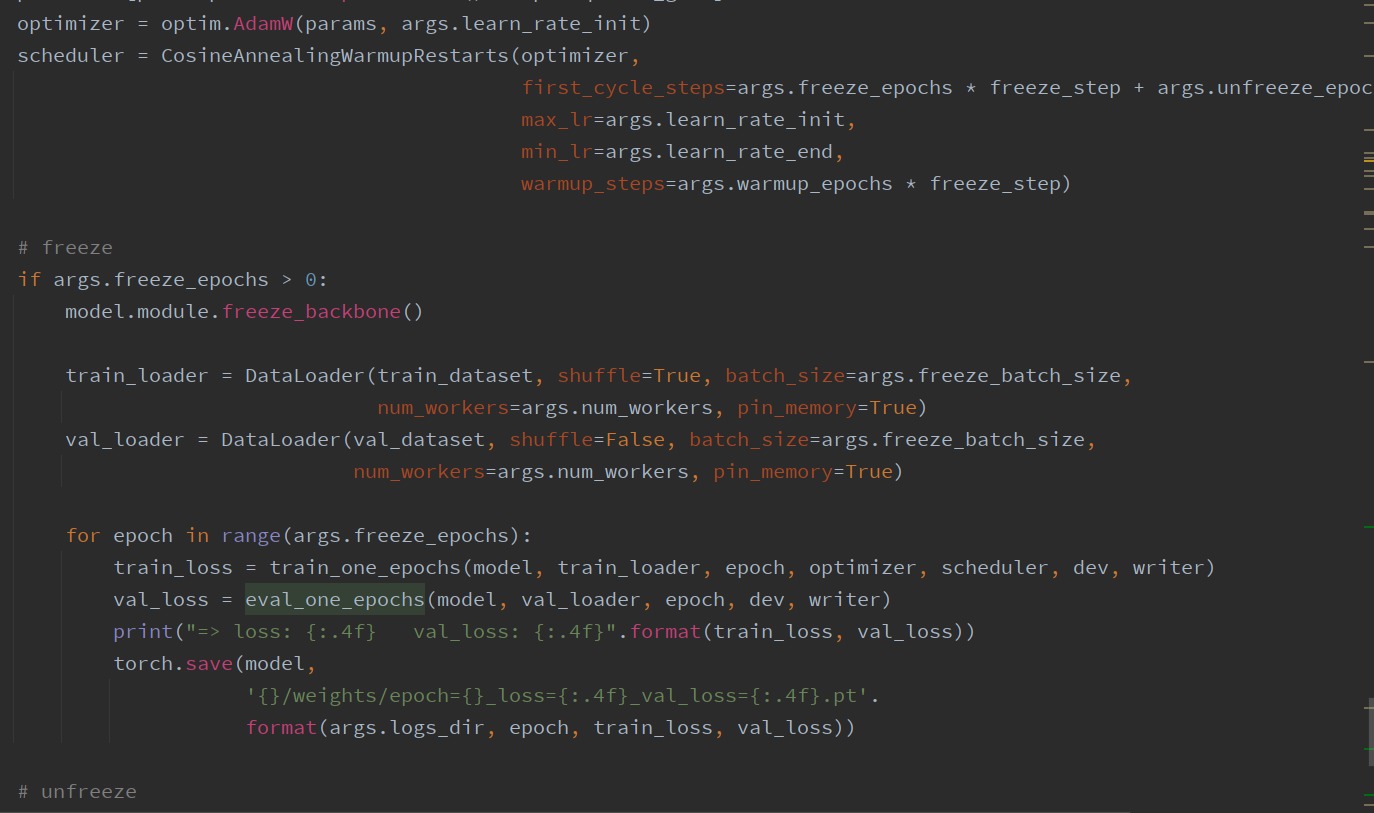 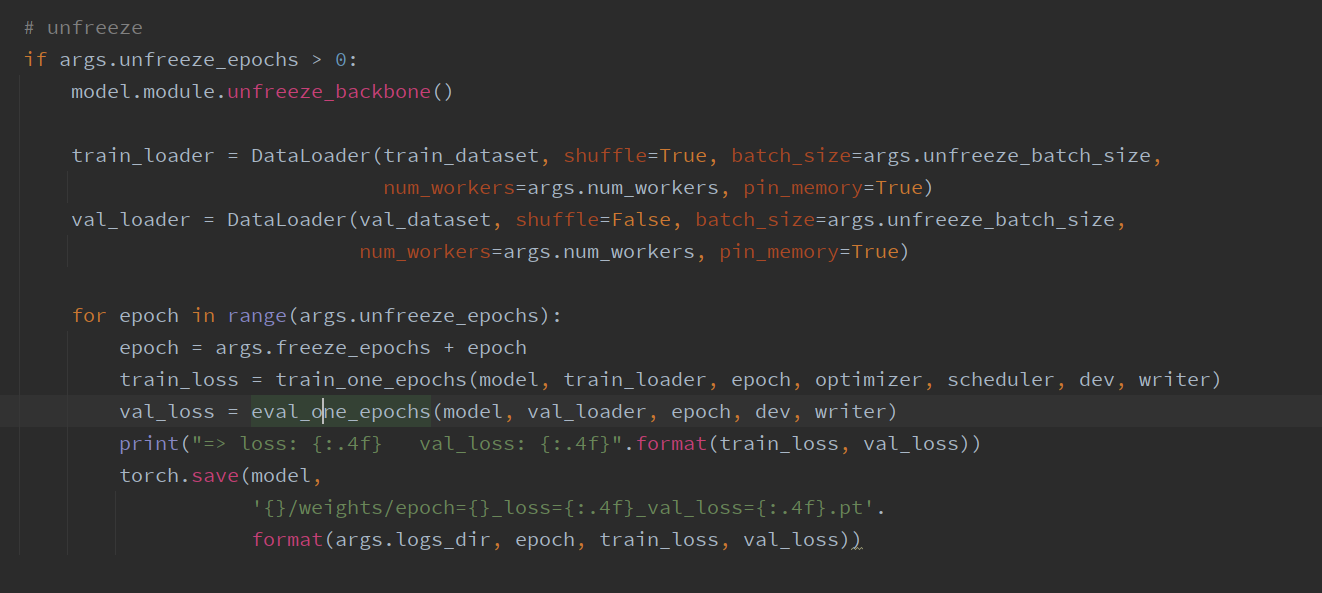 # Train one epochs 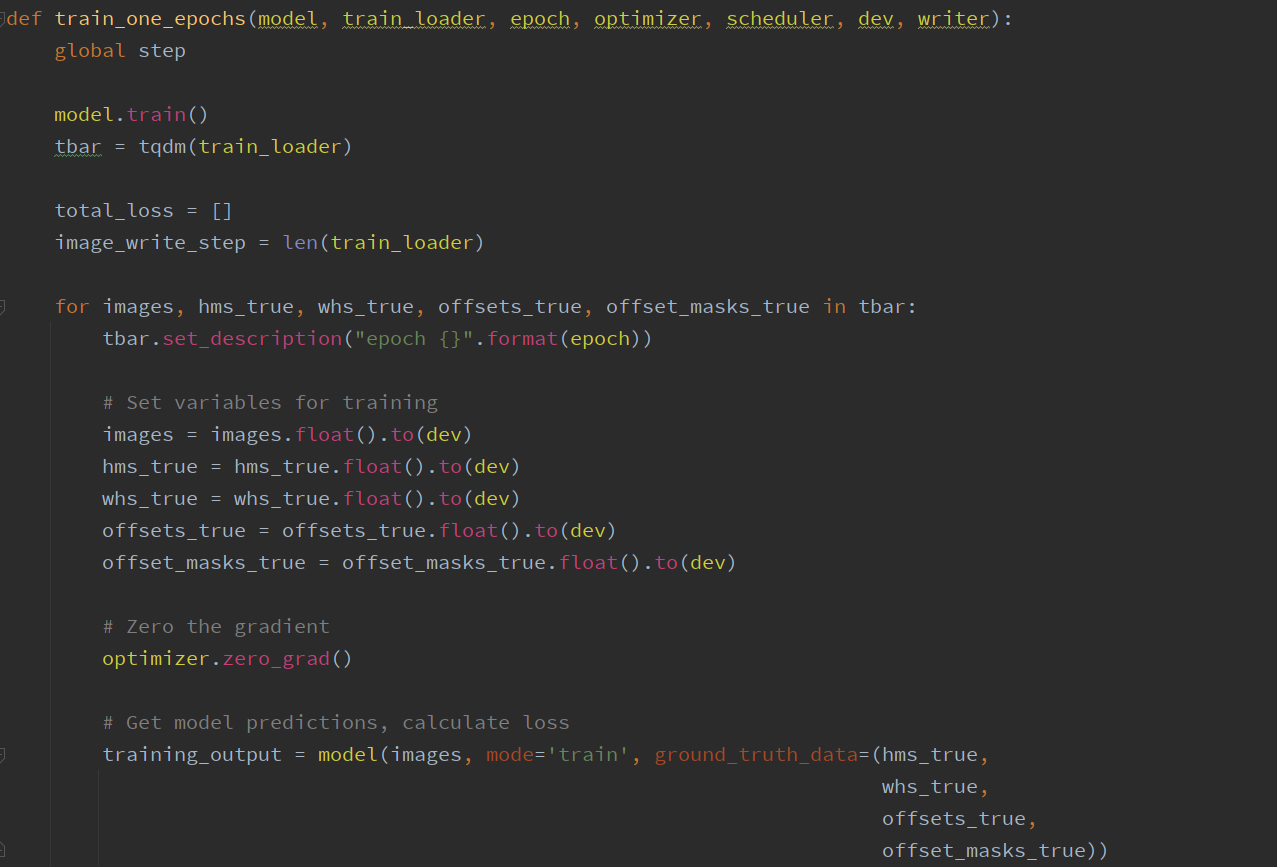 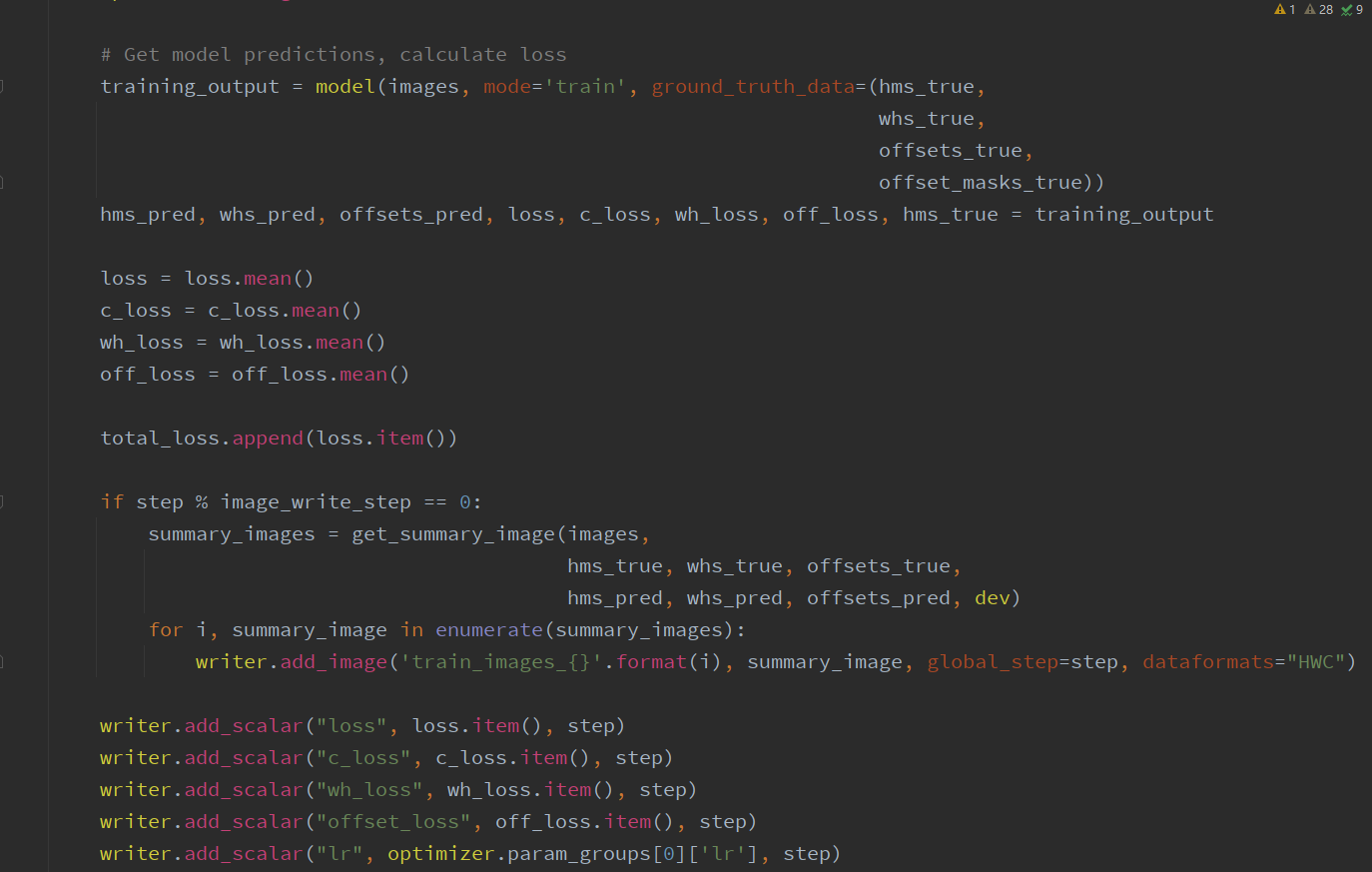 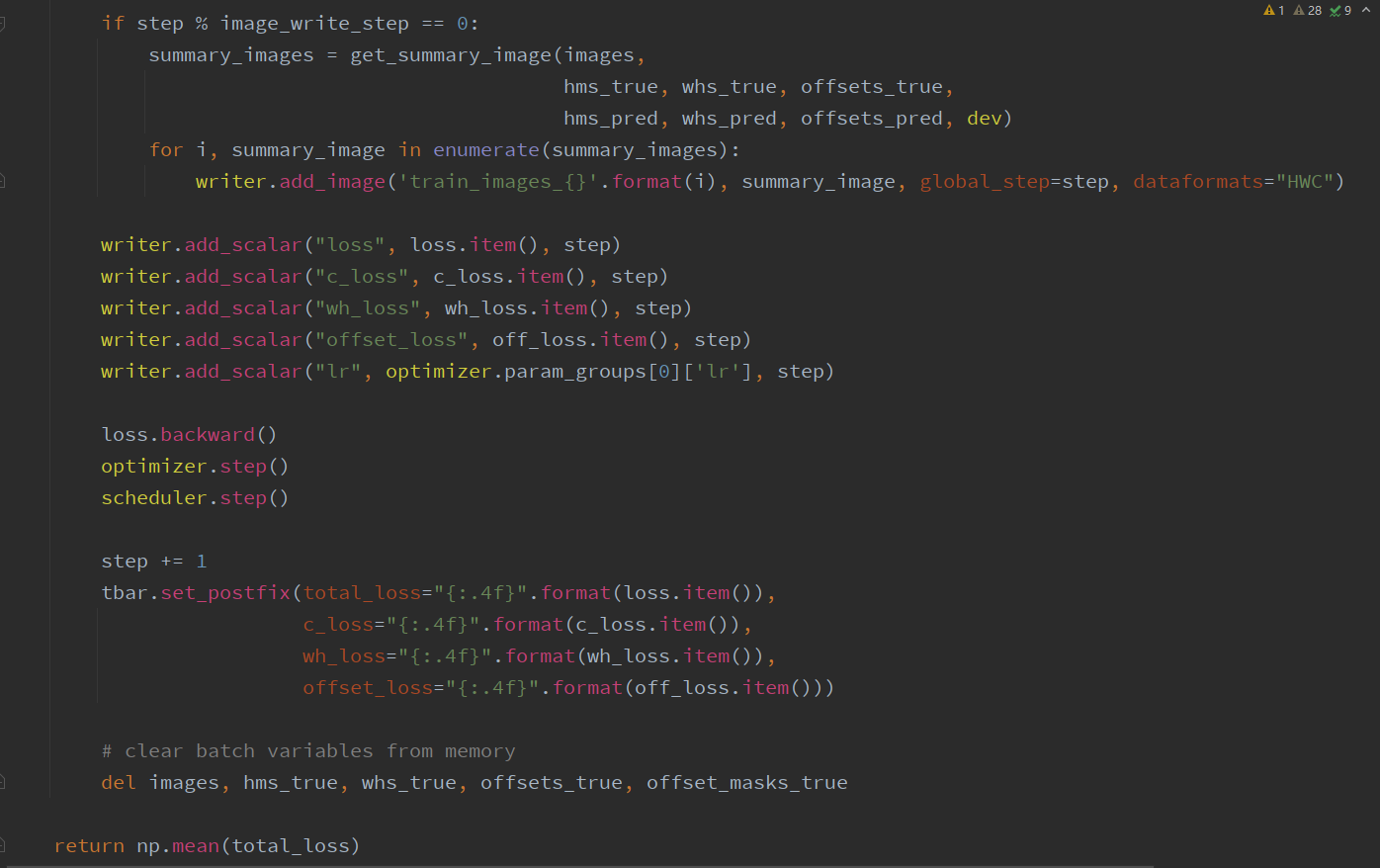 # Loss 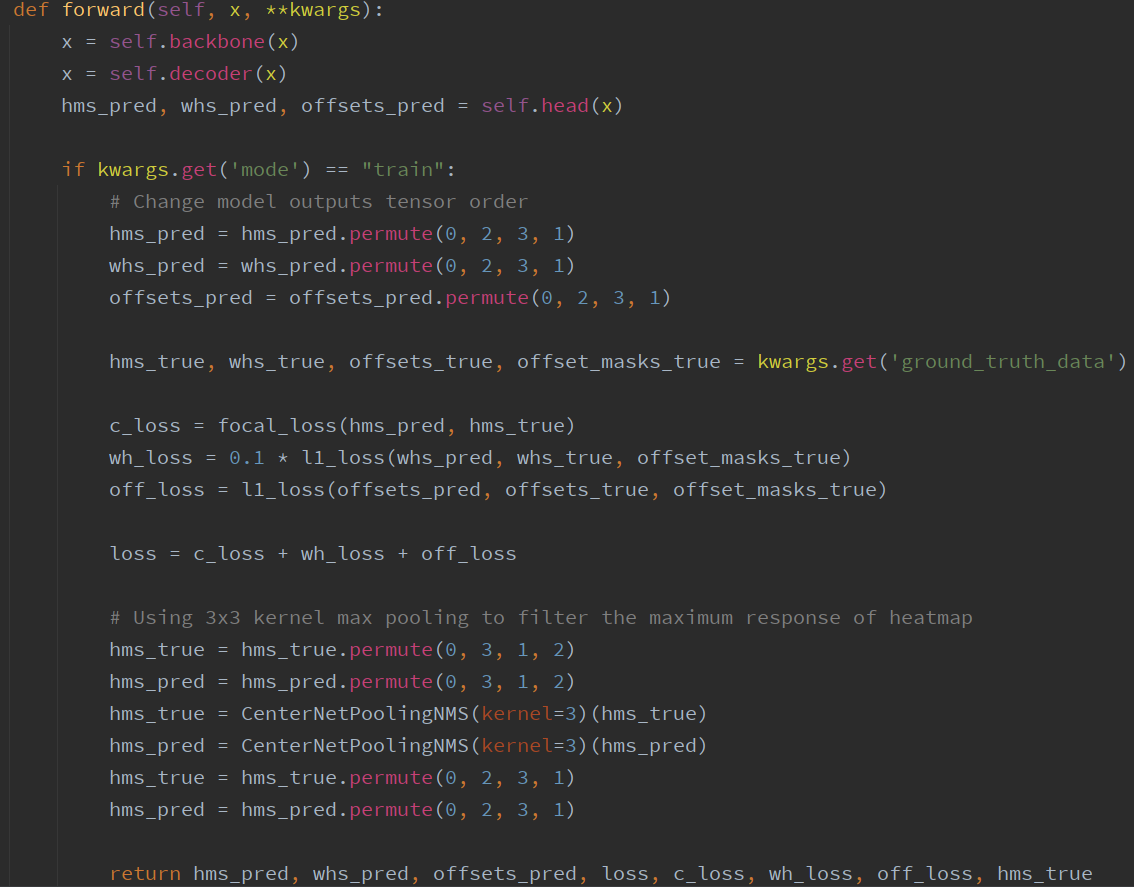 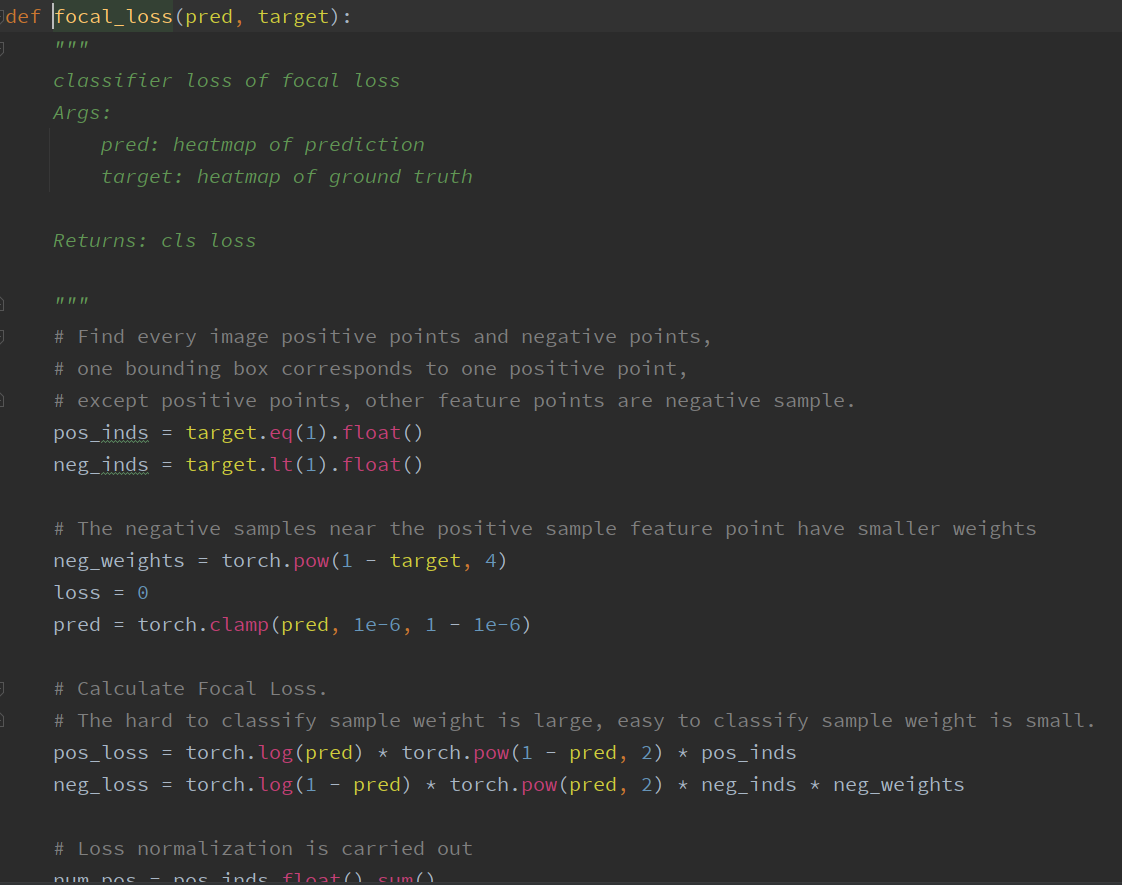  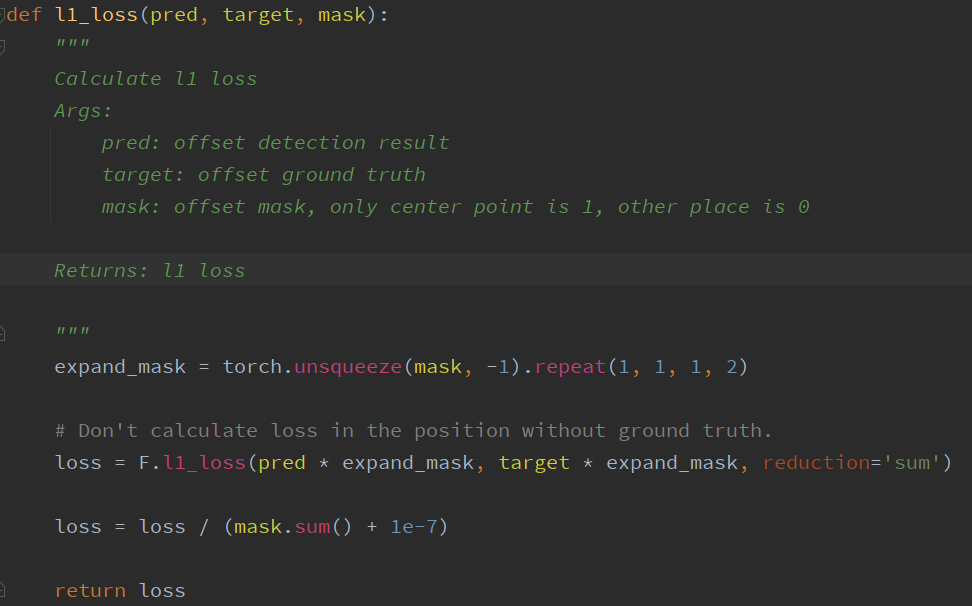 # Dataloader 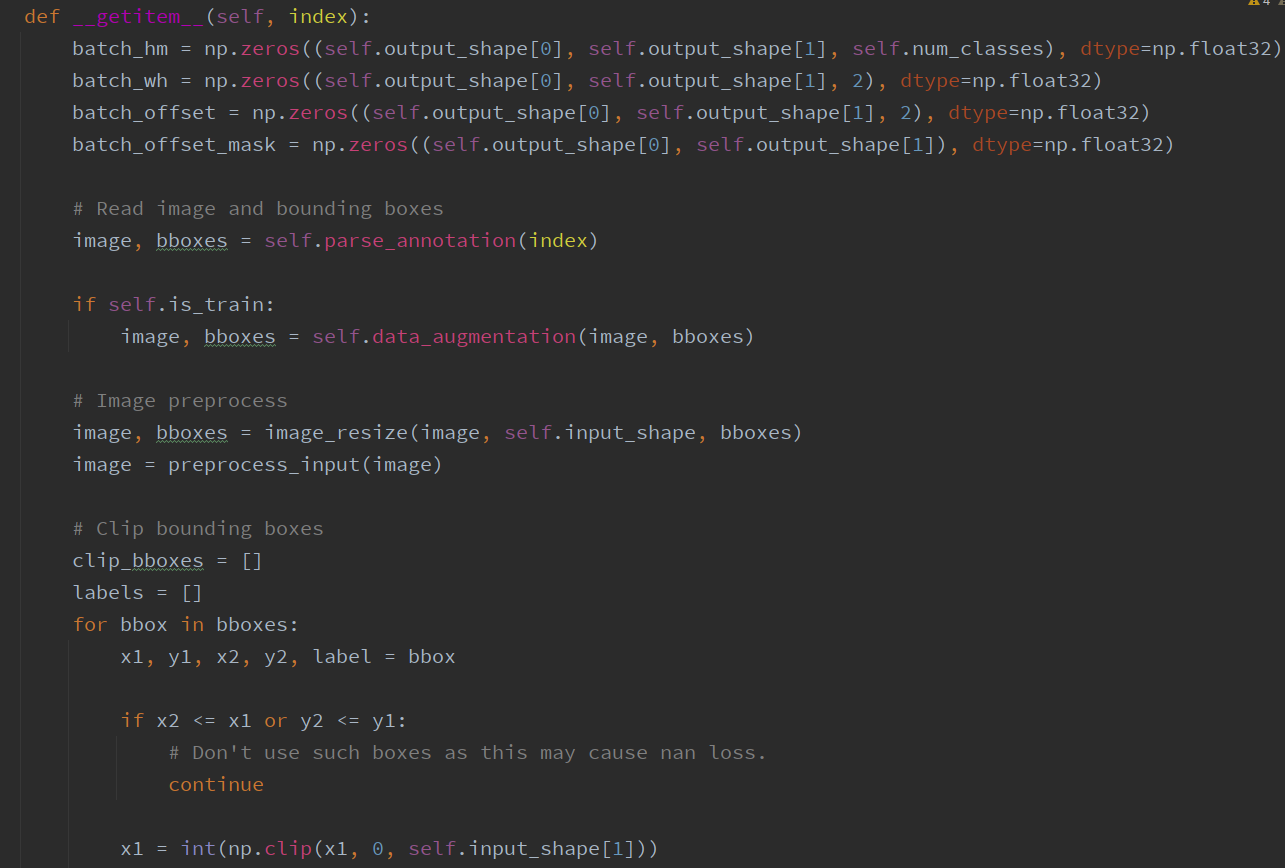 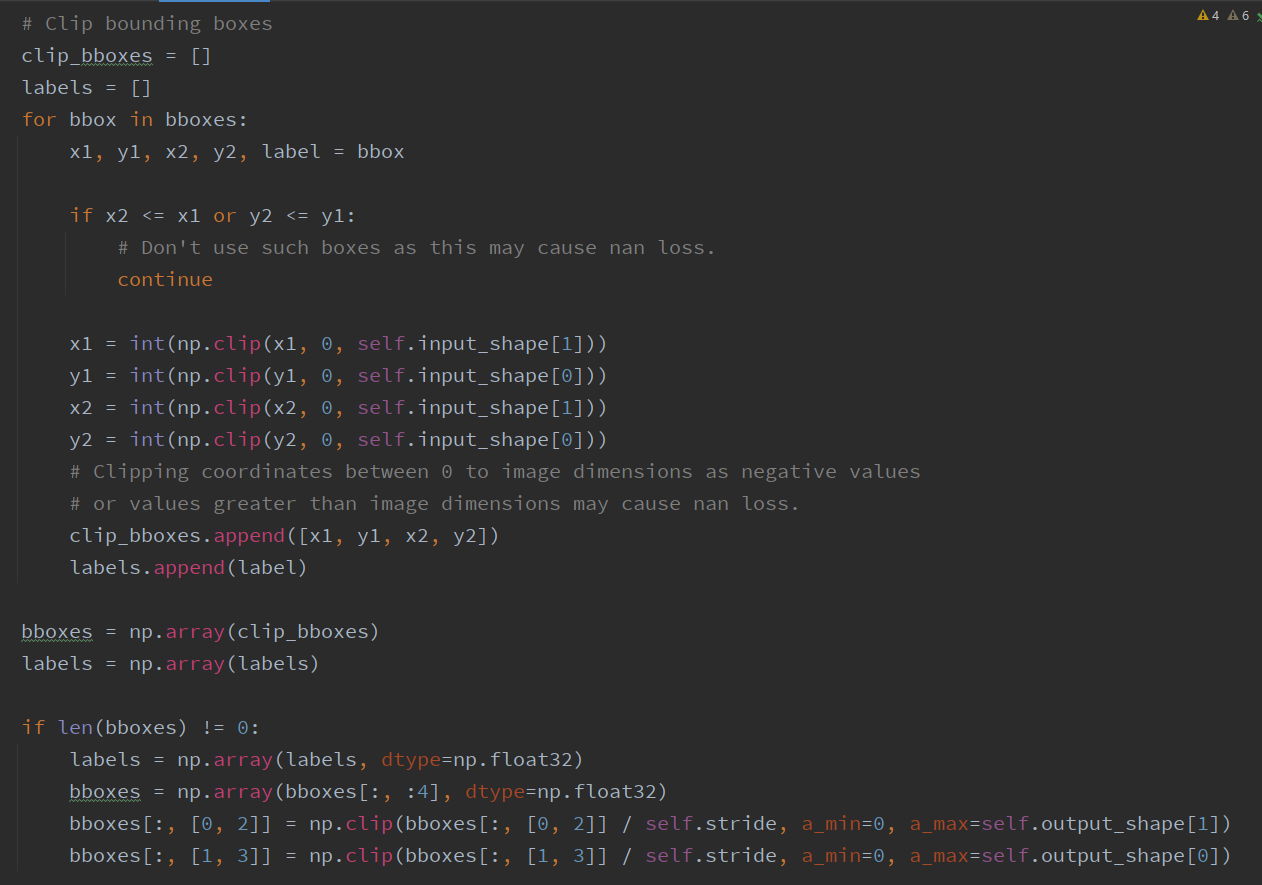  DataLoader 和 Loss基本按照你的方式写的。训练策略稍有改动,但我感觉Loss和data都一样的情况,应该没啥问题。
是呀,跟着你的讲解自己又重新加了一点。
> 找个我是在外面进行了permute,维度顺序是一致的,不然也没法计算。不过我想和你确认的是,你是基于resnet50 backbone的预训练权重,然后fine-tune就可以在VOC上达到77的MAP吗?那此时的val loss是多少呢?我也是采用resnet的backbone预训练权重,也没法达到这个77,而且val loss达到2.5的时候,就会反向上升(虽然我看了下原作者的repo说hm loss是正常的)。模型确实是学到东西了,直接测训练集Map是89,但验证集只有40多。很难受。。。