zxt620
zxt620

实验过程: 1.为测试服务务分配整张显卡资源,100cores及40个单位内存(单个显存单位为256MB)。资源使用情况如下: 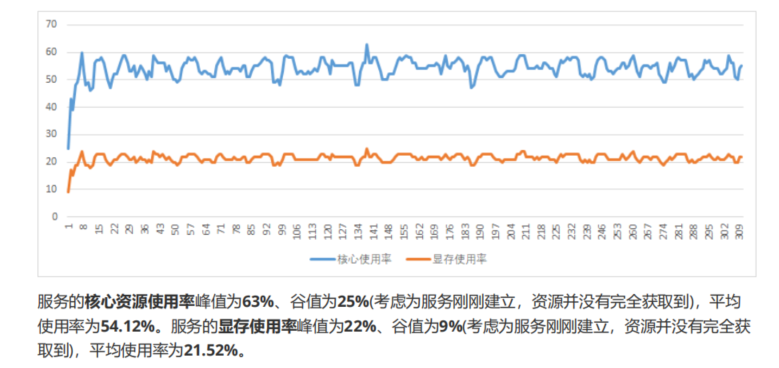 2.创建两个测试服务,跑在同一张卡上,Pod1及Pod2均为50cores及10个单位内存(单个显存单位为256MB),Limit值设为60cores。资源使用情况如下: 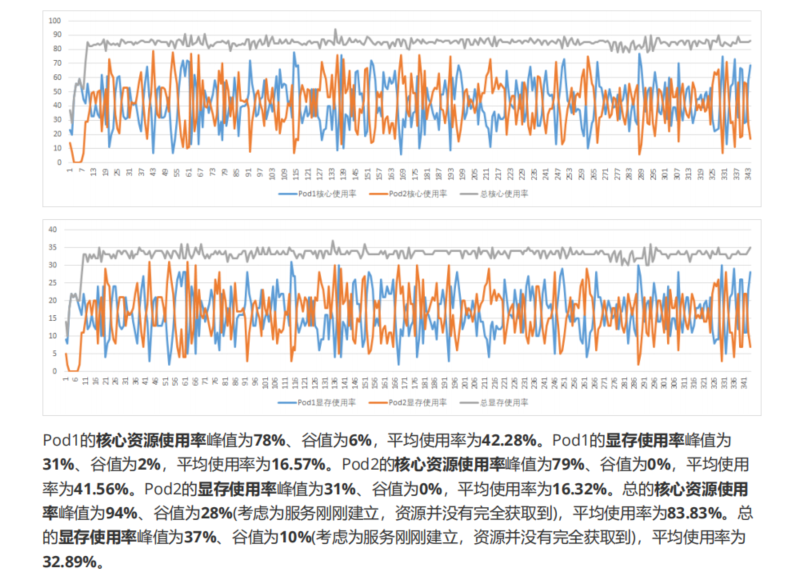
多pod共享一张卡,(测试时模拟的时一张卡上跑两个pod),gpu爆发设置tencent.com/vcuda-core-limit之后,实际资源使用并不能限制在limit值附近,且峰值瞬间可达到90%多,最低谷是0. Pod1为30cores及10个单位内存(单个显存单位为256MB);Pod2为35cores及10个单位内存(单个显存单位为256MB),Limit值设为45cores。测试镜像为Tensorflow框架,数据集为cifar10。 测试结果:Pod1的核心资源使用率峰值为94%、谷值为0%,平均使用率为29.86%。Pod1的显存使用率峰值为 37%、谷值为0%,平均使用率为11.62%。Pod2的核心资源使用率峰值为85%、谷值为0%,平均使用 率为44.43%。Pod2的显存使用率峰值为34%、谷值为0%,平均使用率为17.44%。总的核心资源使用 率峰值为94%、谷值为2%(考虑为服务刚刚建立,资源并没有完全获取到),平均使用率为74.29%。总的 显存使用率峰值为37%、谷值为0%(考虑为服务刚刚建立,资源并没有完全获取到),平均使用率为 29.06%。 