Zhuobin Huang
Zhuobin Huang

**Naive Implementation Latency Breakdown** - **Testcase**: "m": 256, "k": 1280, "n": 5120 |CUDA API| Duration| |-|-| |`cudaMemcpyAsync`|14.628 ms| |`cudaMemcpyAsync`|45.305 μs| |`Kernel`|75.333 μs| |`FusedGegluForwardGpu`|13.703 μs| - **Testcase**: "m": 1024, "k": 640,...
**Non-split Fused GELU Op** 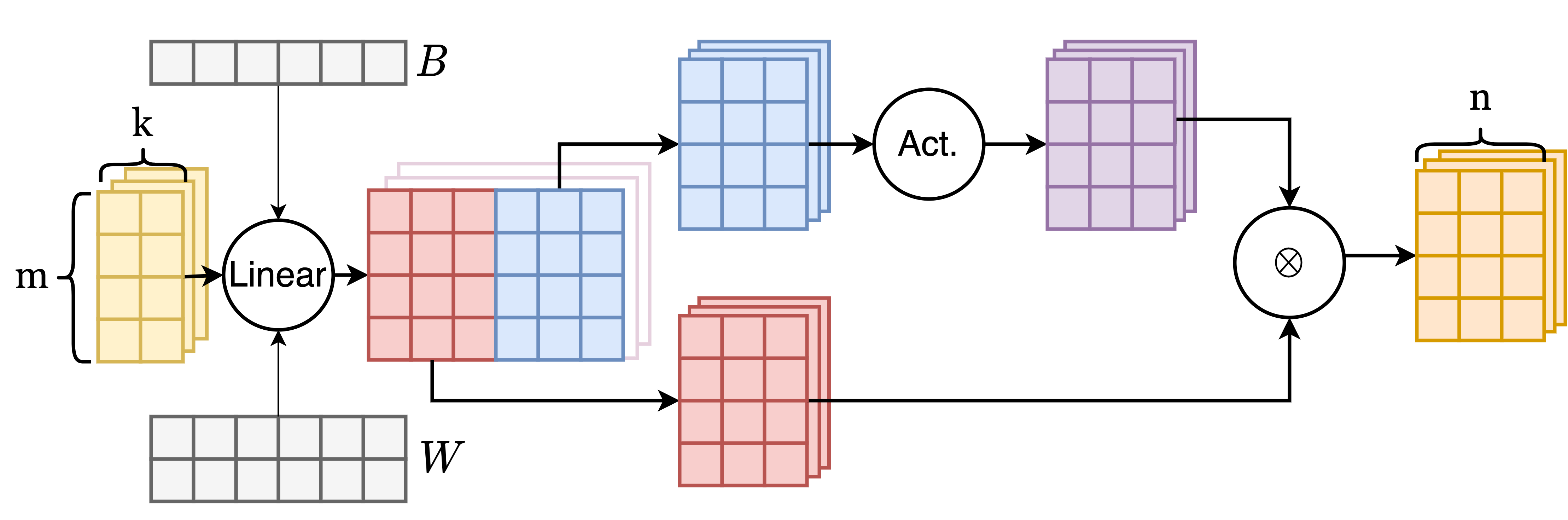
**Split Fused GELU Op** 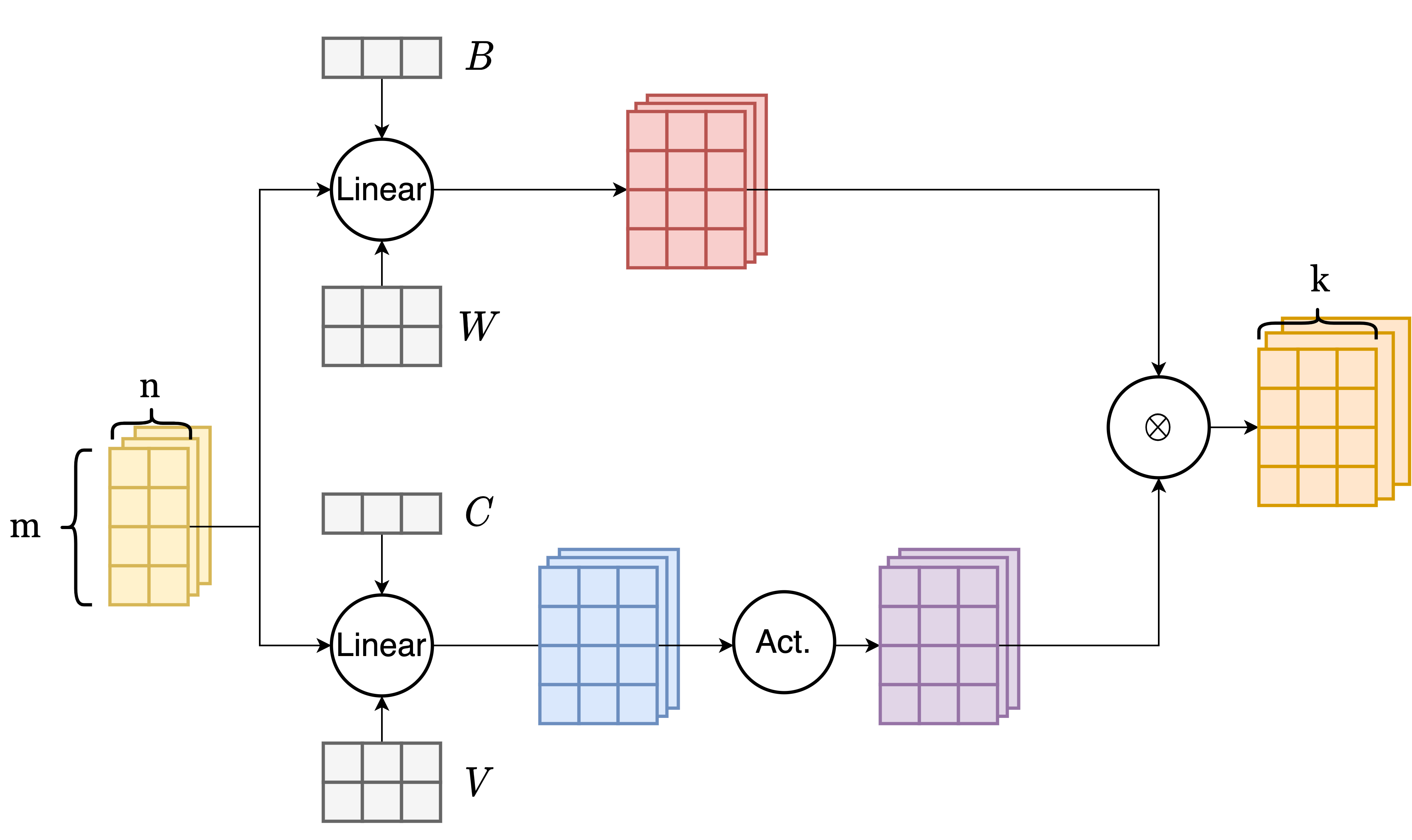
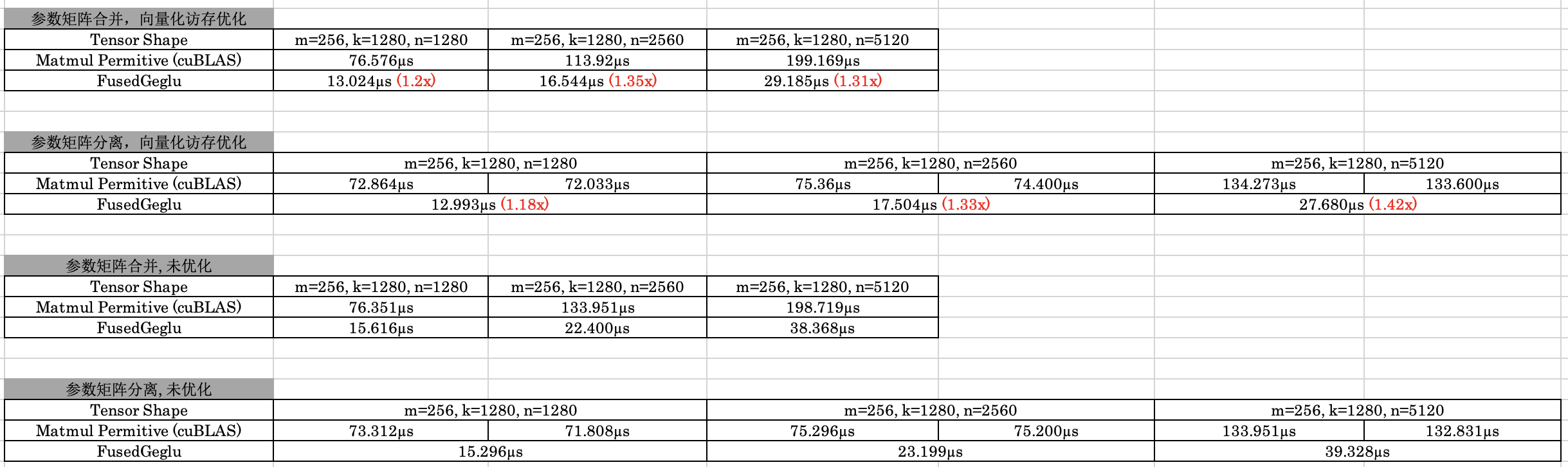
Got the same issue here, with official CUDA 12.8 container environment
I ran into this issue while building flashinfer with PyTorch 2.6 (CUDA: 12.6). Solved it by downgrading to PyTorch 2.6 (CUDA: 12.4), i.e., need to align the CUDA version of...