yingshengBD
![]()
![]()
yingshengBD
先确认使用硬件、paddle版本、paddleSlim版本,较早版本的Slim是没有全量化的 另外,关于priorBox,如果是arm cpu那PriorBox是不会离线处理的(Arm同学修改 https://github.com/PaddlePaddle/Paddle-Lite/commit/c85034f69ebab7af657ef7f390e1312191a4a2f2)
> c85034f69ebab7af657ef7f390e1312191a4a2f2) > > 先确认使用硬件、paddle版本、paddleSlim版本,较早版本的Slim是没有全量化的 另外,关于priorBox,如果是arm cpu那PriorBox是不会离线处理的(Arm同学修改 [c85034f69ebab7af657ef7f390e1312191a4a2f2)](https://github.com/PaddlePaddle/Paddle-Lite/commit/c85034f69ebab7af657ef7f390e1312191a4a2f2%EF%BC%89) > > 我们使用的是paddlepaddle2.1.3 paddleslim2.1 paddlelite 2.9(注册过fpga子图算子的),硬件平台是intel fpga Cyclone V 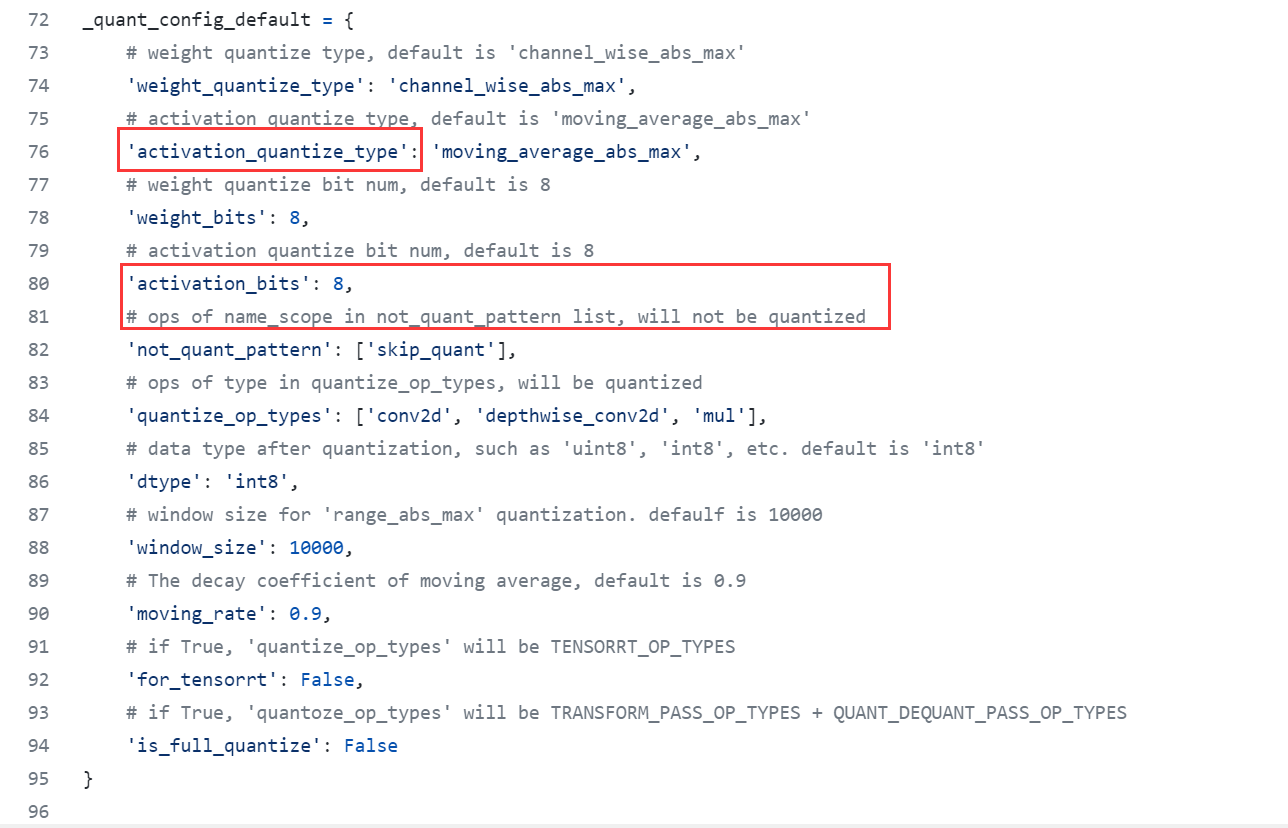 请问这里是否意味着会对relu、relu6等进行量化? 那确实是老版了,建议paddle和slim使用develop或者2.3以后的版本,自带全量化。 另外如果是fpga的量化算子开发, 在此提醒:需要考虑量化是perlayer还是perchannel,uint8还是int8,以免后续踩坑 最后,欢迎贡献fpga算子kernel代码
> > 先确认使用硬件、paddle版本、paddleSlim版本,较早版本的Slim是没有全量化的 另外,关于priorBox,如果是arm cpu那PriorBox是不会离线处理的(Arm同学修改 [c85034f69ebab7af657ef7f390e1312191a4a2f2)](https://github.com/PaddlePaddle/Paddle-Lite/commit/c85034f69ebab7af657ef7f390e1312191a4a2f2%EF%BC%89) > > 我们确实用的是arm,链接好像有误,麻烦再发一下吧。 没关系,这只是个commitID,如果是armcpu,在线计算priorbox也没有什么性能下降 另外priorbox、boxcoder、nms这种本身就没有必要、也不会量化, 如果你是希望模型尽可能多的量化来提升性能,那么建议使用paddle和slim的develop或者2.3以后的版本,那个全量化比较全面。当然之前说的priorbox、boxcoder、nms是不会量化的
对比9258和9262。所以是seg fault,还是计算结果不对呢
如果直接用voc训练好的模型,来推理实际业务图片,当然会有差异。 需要用预训练模型基于你实际业务数据去训练
您有试过训练出来的模型跑paddle inference吗?我们需要确认 训练出的模型本身精度是否可用。
你好 ,请先参考这个文档部署1808,https://paddle-lite.readthedocs.io/zh/develop/demo_guides/verisilicon_timvx.html 注意文档中描述的驱动版本
你是使用opt工具生成的模型?注意target 得同时包含 verisilicon_timvx和arm
是这样的,我们是建议使用 芯原TIMVX 既https://paddle-lite.readthedocs.io/zh/develop/demo_guides/verisilicon_timvx.html 这个方式来部署rk1808,这个要求驱动就是6.4.3.5。你的已经符合。 但是看你的日志,你是用的rk ddk来部署,那个就是要求驱动6.4.0,这个在rk ddk的文档中也有明确说明。 建议按照 https://paddle-lite.readthedocs.io/zh/develop/demo_guides/verisilicon_timvx.html 这个方法
> #9262 还是你催得花哨doge,我在那边回复