javaweb
 javaweb copied to clipboard
javaweb copied to clipboard
http://www1350.github.io/
效果如下  关于表设计,网上大部分人的设计是储存一个父评论id,采用自反递归查询 http://www.tracefact.net/Software-Design/Unlimited-comment-quote-using-recursion.aspx 我认为 1.这个父id可以按层次顺序存储所有父id,这样批量查询一次就行了。 2.可以在评论内容里面直接写入盖楼效果,展示的时候css控制就好了 3.闭包表 http://blog.jobbole.com/112315/
**数据库**:物理操作系统或其他形式文件类型集合。 **实例**:后台线程及一个共享内存组成。在系统表现上就是一个进程。 数据库和实例关系:一个数据库可能对应多个实例(集群),一个实例对应一个数据库。实例才是真正操作数据库文件的。 Mysql组成部分: - 连接池组件 - 管理服务和工具组件 - SQL接口组件 - 查询分析器组件 - 优化器组件 - 缓存组件 - 插件式存储引擎 - 物理文件 InnoDB 体系结构 后台线程: 1. Master Thread: 负责将缓冲池中数据异步刷新到磁盘,保证数据一致性,包括脏页的刷新、合并插入缓存(INSERT BUFFER)、UNDO页回收 2. IO...
1.utf8mb4的最低mysql版本支持版本为5.5.3+,若不是,请升级到较新版本。 2.修改mysql配置文件my.cnf(windows为my.ini) my.cnf一般在etc/mysql/my.cnf位置。找到后请在以下三部分里添加如下内容: ``` [client] default-character-set = utf8mb4 [mysql] default-character-set = utf8mb4 [mysqld] character-set-client-handshake = FALSE character-set-server = utf8mb4 collation-server = utf8mb4_unicode_ci init_connect='SET NAMES utf8mb4' ``` 在mysql中执行: ``` set character_set_client...
数据库带来的并发问题包括: 1.丢失或覆盖更新。(幻像读) 2.未确认的相关性(脏读)。 3.不一致的分析(非重复读)。 详细描述如下: # 一.丢失更新 当两个或多个事务选择同一行,然后基于最初选定的值更新该行时,会发生丢失更新问题。每个事务都不知道其它事务的存在。最后的更新将重写由其它事务所做的更新,这将导致数据丢失。 e.g.事务A和事务B同时修改某行的值, - 1.事务A将数值改为1并提交 - 2.事务B将数值改为2并提交。 这时数据的值为2,事务A所做的更新将会丢失。 解决办法:对行加锁,只允许并发一个更新事务。 # 二.未确认的相关性(脏读) 当第二个事务选择其它事务正在更新的行时,会发生未确认的相关性问题。第二个事务正在读取的数据还没有确认并且可能由更新此行的事务所更改。 - 1.Mary的原工资为1000, 财务人员将Mary的工资改为了8000(但未提交事务) - 2.Mary读取自己的工资 ,发现自己的工资变为了8000,欢天喜地! - 3.而财务发现操作有误,回滚了事务,Mary的工资又变为了1000 像这样,Mary记取的工资数8000是一个脏数据。 解决办法:如果在第一个事务提交前,任何其他事务不可读取其修改过的值,则可以避免该问题。 # 三.不一致的分析(非重复读) ...
# 什么是字节码? - 机器码 机器码(machine code)是CPU可直接解读的指令。机器码与硬件等有关,不同的CPU架构支持的硬件码也不相同。 - 字节码 字节码(bytecode)是一种包含执行程序、由一序列 op 代码/数据对 组成的二进制文件。字节码是一种中间码,它比机器码更抽象,需要直译器转译后才能成为机器码的中间代码。通常情况下它是已经经过编译,但与特定机器码无关。字节码主要为了实现特定软件运行和软件环境、与硬件环境无关。 字节码的实现方式是通过编译器和虚拟机器。编译器将源码编译成字节码,特定平台上的虚拟机器将字节码转译为可以直接执行的指令。 而在Java里,通过类加载器把字节码读入加载并转换成 java.lang.Class类的一个实例。 ## 类文件结构 一个编译后的类文件包含下面的结构: ``` ClassFile { u4 magic; u2 minor_version; u2 major_version; u2 constant_pool_count; cp_info...
# Java跟踪利器---BTrace 地址:https://github.com/btraceio/btrace > BTrace 是基于动态字节码修改技术(Hotswap)来实现运行时 java 程序的跟踪和替换。大体的原理可以用下面的公式描述:Client(Java compile api + attach api) + Agent(脚本解析引擎 + ASM + JDK6 Instumentation) + Socket其实 BTrace 就是使用了 java attach api 附加 agent.jar ,然后使用脚本解析引擎+asm来重写指定类的字节码,再使用...
http://blog.jobbole.com/24006/ # 索引区分度 > 区分度: 指字段在数据库中的不重复比 区分度在新建索引时有着非常重要的参考价值,在MySQL中,区分度的计算规则如下: > 字段去重后的总数与全表总记录数的商。 例如: ` select count(distinct(name))/count(*) from t_base_user; ` count(distinct(name))/count(*) -- 1.0000 其中区分度最大值为1.000,最小为0.0000,区分度的值越大,也就是数据不重复率越大,新建索引效果也越好,在主键以及唯一键上面的区分度是最高的,为1.0000,在状态,性别等字段上面的区分度值是最小的。 (这个就要看数据量了,如果只有几条数据,这时区分度还挺高的,如果数据量多,区分度基本为0.0000。也就是在这些字段上添加索引后,效果也不佳的原因。) 值得注意的是: 如果表中没有任何记录时,计算区分度的结果是为空值,其他情况下,区分度值均分布在0.0000-1.0000之间。 个人强烈建议, 建索引时,一定要先计算该字段的区分度,原因如下: 1、单列索引 可以查看该字段的区分度,根据区分度的大小,也能大概知道在该字段上的新建索引是否有效,以及效果如何。区分度越大,索引效果越明显。 2、多列索引(联合索引) 多列索引中其实还有一个字段的先后顺序问题,一般是将区分度较高的放在前面,这样联合索引才更有效,例如: `select...
# transient 如果一个对象实现了Serilizable,如果你想排除某些属性的序列化,就在改变量钱加上transient 如private transient Thread exclusiveOwnerThread; # volatile 一个很通俗的解释 http://www.importnew.com/18126.html > 在一个多线程应用里面,如果没有使用volatile修饰变量,为了性能,每个线程可能会从内存拷贝变量到cpu。如果你的电脑是多核,每个线程跑在不同的cpu里面。这意味着,每个线程可能会把同一个变量拷贝到不同cpu的cpu缓存里面。 > 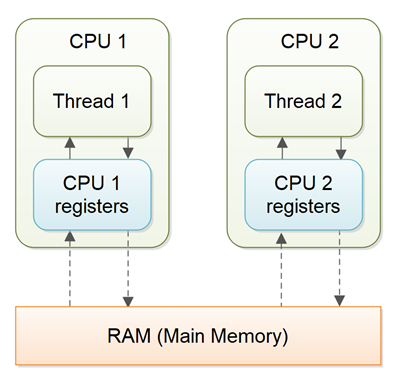 假如现在有多个线程使用下面这个类 ``` public class SharedObject { public int counter = 0; } ``` 假如线程1对counter增加,线程2只是偶尔读取。 如果该变量没有声明为volatile,就可能发生,这个值没有被写回内存,线程2读到的还是原来的值。...
schema定义了表、每个表的字段,还有表和字段之间的关系。 catalog是由一个数据库实例的元数据组成的,包括基本表,同义词,索引,用户等等。 information_schema数据库是MySQL自带的,它提供了访问数据库元数据的方式。什么是元数据呢?元数据是关于数据的数据,如数据库名或表名,列的数据类型,或访问权限等。有些时候用于表述该信息的其他术语包括“数据词典”和“系统目录”。 在 MySQL中,把 information_schema 看作是一个数据库,确切说是信息数据库。其中保存着关于MySQL服务器所维护的所有其他数据库的信息。如数据库名,数据库的表,表栏的数据类型与访问权限等。在INFORMATION_SCHEMA中,有数个只读表。它们实际上是视图,而不是基本表,因此,你将无法看到与之相关的任何文件。 information_schema数据库表说明: SCHEMATA表:提供了当前mysql实例中所有数据库的信息。是show databases的结果取之此表。 TABLES表:提供了关于数据库中的表的信息(包括视图)。详细表述了某个表属于哪个schema,表类型,表引擎,创建时间等信息。是show tables from schemaname的结果取之此表。 COLUMNS表:提供了表中的列信息。详细表述了某张表的所有列以及每个列的信息。是show columns from schemaname.tablename的结果取之此表。 STATISTICS表:提供了关于表索引的信息。是show index from schemaname.tablename的结果取之此表。 USER_PRIVILEGES(用户权限)表:给出了关于全程权限的信息。该信息源自mysql.user授权表。是非标准表。 SCHEMA_PRIVILEGES(方案权限)表:给出了关于方案(数据库)权限的信息。该信息来自mysql.db授权表。是非标准表。 TABLE_PRIVILEGES(表权限)表:给出了关于表权限的信息。该信息源自mysql.tables_priv授权表。是非标准表。 COLUMN_PRIVILEGES(列权限)表:给出了关于列权限的信息。该信息源自mysql.columns_priv授权表。是非标准表。 CHARACTER_SETS(字符集)表:提供了mysql实例可用字符集的信息。是SHOW CHARACTER SET结果集取之此表。 COLLATIONS表:提供了关于各字符集的对照信息。...
# Optional 创建Optional实例(以下都是静态方法): - Optional.of(T) 创建指定引用的Optional实例,若引用为null则快速失败 - Optional.absent() 创建引用缺失的Optional实例 - Optional.fromNullable(T) 创建指定引用的Optional实例,若引用为null则表示缺失 用Optional实例查询引用(以下都是非静态方法): - boolean isPresent() 如果Optional包含非null的引用(引用存在),返回true - T get() 返回Optional所包含的引用,若引用缺失,则抛出java.lang.IllegalStateException - T or(T) 返回Optional所包含的引用,若引用缺失,返回指定的值 - T orNull() 返回Optional所包含的引用,若引用缺失,返回null -...