whlook
![]()
![]()
whlook
看代码,好像还不支持cpu runtime? 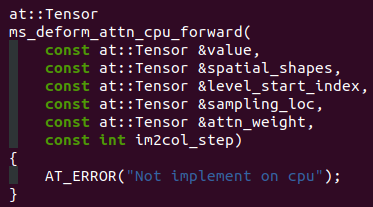 看来目前只能在cuda环境下编译运行,之前没安装cuda home,准备再试一下
> 我也遇到了同样的问题,好像跟cuda环境变量相关,但我确定我是配置好了gpu运行的。我是Windows系统,是不是不支持在windows上这样做? 检查一下CUDA_HOME,以及看看setup.py里相关分支,可能没有走nvcc
> > 我也遇到了同样的问题,好像跟cuda环境变量相关,但我确定我是配置好了gpu运行的。我是Windows系统,是不是不支持在windows上这样做? > > 成功了吗 > cpu暂时没法用,必须要配置cuda home,然后在pip install -e .才行,我ok了
> Same problem, how to solve it? similar issue and the way to fix it: https://github.com/google/yapf/issues/1204
> 感谢你的反馈。我想具体了解一下,你希望提供“no amp wrap”版本的 AmpOptimizerWrapper,那 autocast 的操作你打算在哪里完成? 我最初的想法是如果使用去掉autocast的AmpOptimizerWrapper,那么可以在自己的代码里手动使用torch.autocast等操作,不过这样对用户来说可能也不是很方便,目前看可能还是with autocast(enabled=False):更可行一些
> 你可以尝试使用 `with autocast(enabled=False):` 在里面的代码临时关闭 autocast 抱歉重新提起这个问题。目前发现使用with autocast(enabled=False):不是一个合适的解决方法。因为这个会导致内存突然上升,这个背离了使用amp的理由。所以为了兼顾amp使用,并且保证在训练代码中使用no_grad的操作不会破坏训练效果,我建议在mmengine中的amp包装上修改一下默认参数(cache_enabled=False),默认为True: 
> > 你可以尝试使用 `with autocast(enabled=False):` 在里面的代码临时关闭 autocast > > 抱歉重新提起这个问题。目前发现使用with autocast(enabled=False):不是一个合适的解决方法。因为这个会导致内存突然上升,这个背离了使用amp的理由。所以为了兼顾amp使用,并且保证在训练代码中使用no_grad的操作不会破坏训练效果,我建议在mmengine中的amp包装上修改一下默认参数(cache_enabled=False),默认为True:  更新,mmengine也可以不改,在自己模型的代码里按需关闭cache也可以。顺便提醒路人了,这个还是挺隐蔽的坑