Biały Wilk
![]()
![]()
![]()
Biały Wilk
> > @Coder-nlper 我这里看是有的 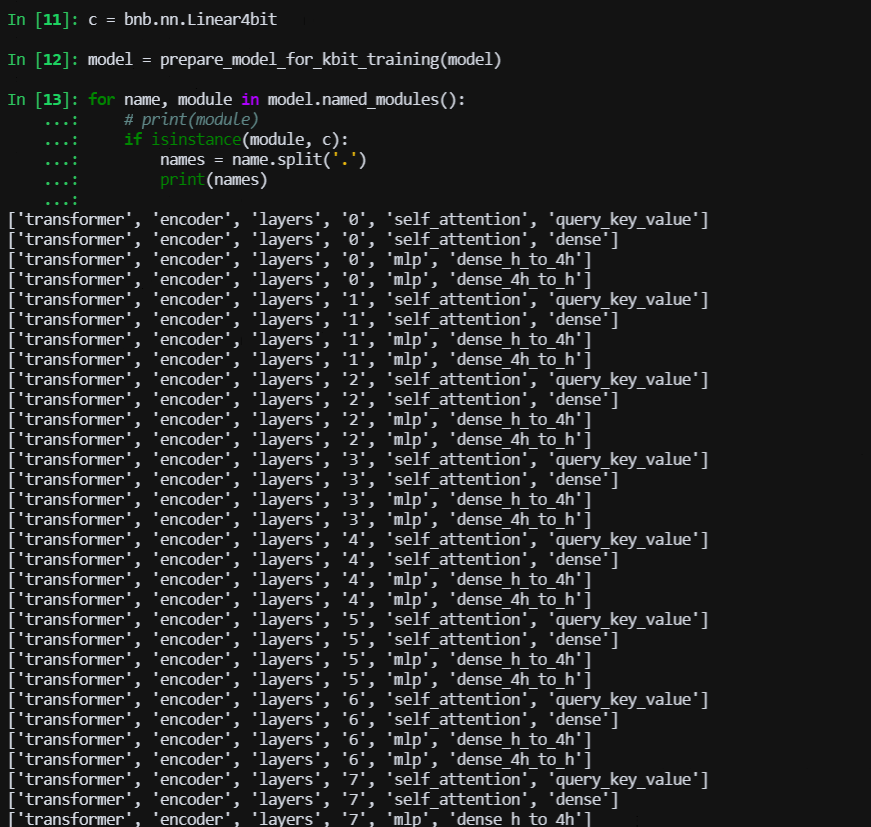 > > 问一下,图片中哪些层是被量化的层,名字有提示吗? 能打印出来的层,都是被量化为nf4的
commands to build: hf_model_path=/root/chatglm3-6b/ engine_dir=/root/trtllm/trtllmmodels/fp16/ CUDA_ID="1" CUDA_VISIBLE_DEVICES=$CUDA_ID python3 build.py \ --model_dir $hf_model_path \ --log_level "info" \ --output_dir $engine_dir/1-gpu \ --world_size 1 \ --tp_size 1 \ --max_batch_size 50 \ --max_input_len 2048...
Driver is 470.141.10. is there any relationship with it?
> > Driver is 470.141.10. is there any relationship with it? > > I have to imagine that likely isn't ideal. > > While it's supported per the [Nvidia Frameworks...
I also face the same issue. the reason may as follows: https://github.com/NVIDIA/TensorRT-Model-Optimizer/blob/main/llm_ptq/README.md#model-support-list
> To be more precise, all weight-only kernels use `fp32` accumulation, regardless of the arch version. > We have done extensive experiments on `L20` and `L40s`, where `fp8xint4` is better...
> @x-transformers did you test error rate through pytorch or trtllm? I suggest you have a first try on accuracy verification on pytorch, if it turns fine then it's kernel's...
我本地微调也遇到同样问题。 使用Qwen1.5-4B微调模型,loss、梯度正常下降 使用Qwen2.5-3B,loss降不下去
基座模型,我使用了 text 这样的格式。发现是不能收敛的。 更换成text,这样训练就正常了
> If you use LoRA on the base models, you need to finetune the embeddings and the lm_head if you use the ChatML template. 使用ChatML方式。 Qwen2.5-3B,是使用共享embedding的方式。lora的 modules_to_save=["embed_tokens"],还是不能收敛。 modules_to_save=["embed_tokens", "lm_head"]是可以收敛的,但是3B里面就没有lm_head这一层呀。 请问这种是什么问题导致的?Qwen1.5-4B里面,没有这个问题...