ChatGLM2-6B

ChatGLM2-6B copied to clipboard
[BUG/Help] <title> Qlora不支持么?
Is there an existing issue for this?
- [X] I have searched the existing issues
Current Behavior
使用nf4量化载入显示: You are loading your model in 8bit or 4bit but no linear modules were found in your model. this can happen for some architectures such as gpt2 that uses Conv1D instead of Linear layers. Please double check your model architecture, or submit an issue on github if you think this is a bug.
然后执行:prepare_model_for_kbit_training就OOM,看log信息,好像Chatglm2-6b的权重并没有被量化。 到prepare_model_for_kbit_training,把未量化权重全部转位float32,然后就OOM了。
使用的模型权重以及代码是今天最新的
Expected Behavior
none
Steps To Reproduce
none
Environment
- OS:
- Python:
- Transformers:4.31.0.dev
- PyTorch:2.0.1
- CUDA Support (`python -c "import torch; print(torch.cuda.is_available())"`) :11.8
-bitsandbytes: 0.39.0
Anything else?
No response
import bitsandbytes as bnb
from transformers import (
AutoConfig,
AutoTokenizer,
AutoModel,
set_seed,
BitsAndBytesConfig
)
import torch
from peft import (
prepare_model_for_kbit_training,
LoraConfig,
get_peft_model,
get_peft_model_state_dict,
PeftModel
)
compute_dtype = torch.bfloat16
cls = bnb.nn.Linear4bit
model_path="models/chatglm2-6b"
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
load_in_8bit=False,
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type= 'nf4'
)
model = AutoModel.from_pretrained(
model_path,
device_map="auto",
quantization_config=quant_config,
trust_remote_code=True,
)
model = prepare_model_for_kbit_training(model)
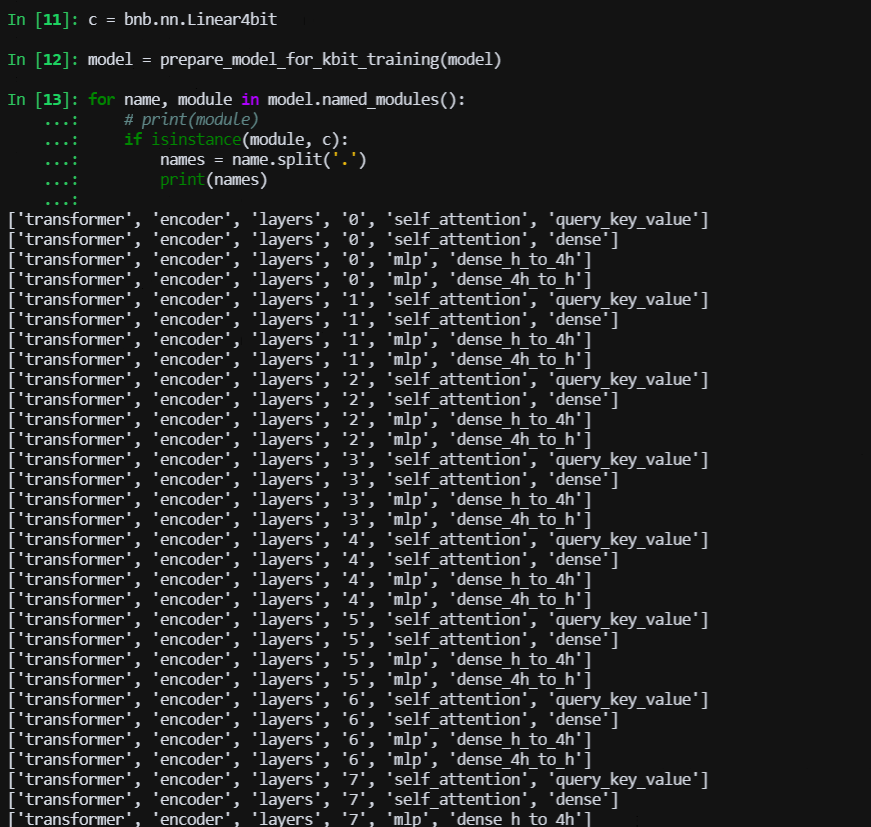
for name, module in model.named_modules():
# print(module)
if isinstance(module, cls):
names = name.split('.')
print(names)
使用上述代码,在4个A10上面能加载起来,不过寻找量化nf4量化后的层,完全没有。 同样的代码使用baichuan7B就能找到,而且GPU占用很少
是不是ChatGLM2-6B确实不支持qlora?但是chatglm6b使用qlora可以载入,可以找到量化后的层