Wen-Chin Huang (unilight)
Wen-Chin Huang (unilight)
Hi, Thank you for your interest in this repo! According to our subjective evaluation in our [journal paper](https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=9057379), CDVAE-CLS-GAN should at least be comparable with CDVAE (with GV). 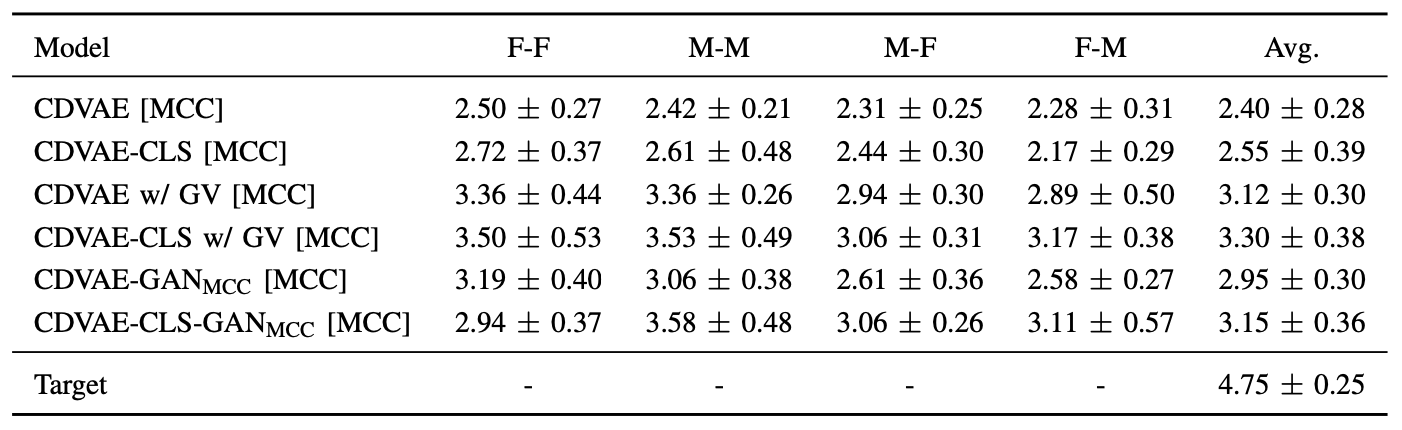 If...
Hi @jiusansan222, We are preparing an all-in-one package containing all the materials of the VoiceMOS Challenge 2022, including the ground truth labels of the test set. We will support instructions...
Hi @sandhiya18, Technically, yes. But notice that the form of the answers in SQuAD is that the answer is given as a span of the context, so you may only...
We can consider adding VCTK recipes. Meanwhile, both VCC2018 and VCC2020 are publicly available, and we support the automatic downloading of the dataset in the VCC2018 recipe (not yet for...
@mart-cerny This insight is interesting... So does that mean you're using mcep extracted by `pysptk` to train the GMM model? How does the converted sound like?
In theory, a bigger training dataset leads to a better performance (generalization ability), but I think for GMM-VC about 50-80 utterances should be enough, i.e. the improvement can be marginal...
Have you trained any model using WORLD features? (ex. using vcc2020 dataset)
@k2kobayashi Can you share your results and config file using WORLD features? I trained on vcc2018 and the results are quite bad. I would like to know your settings.
Hi @talka1 , For the parameters in the configuration, please check the original paper for more details. https://arxiv.org/pdf/2103.02858 But, before digging into the configs, I think the size of the...
Hi @turian, > In the paper you use 75 * 12 = 900 utterances, is that generally enough? It depends on how you define "enough". More data leads to better...