ttyuuuuuuuuuu
ttyuuuuuuuuuu

是这样的,我想用uie的模型对ccks的比赛数据(train.json,图右侧)做一个评估,想看下效果。我的切入点是把train.json的格式转为doccano_ext.json(图左侧)。 (1)看到doccano_ext.json第一条数据,我以为entities的id是针对text从0开始计数: 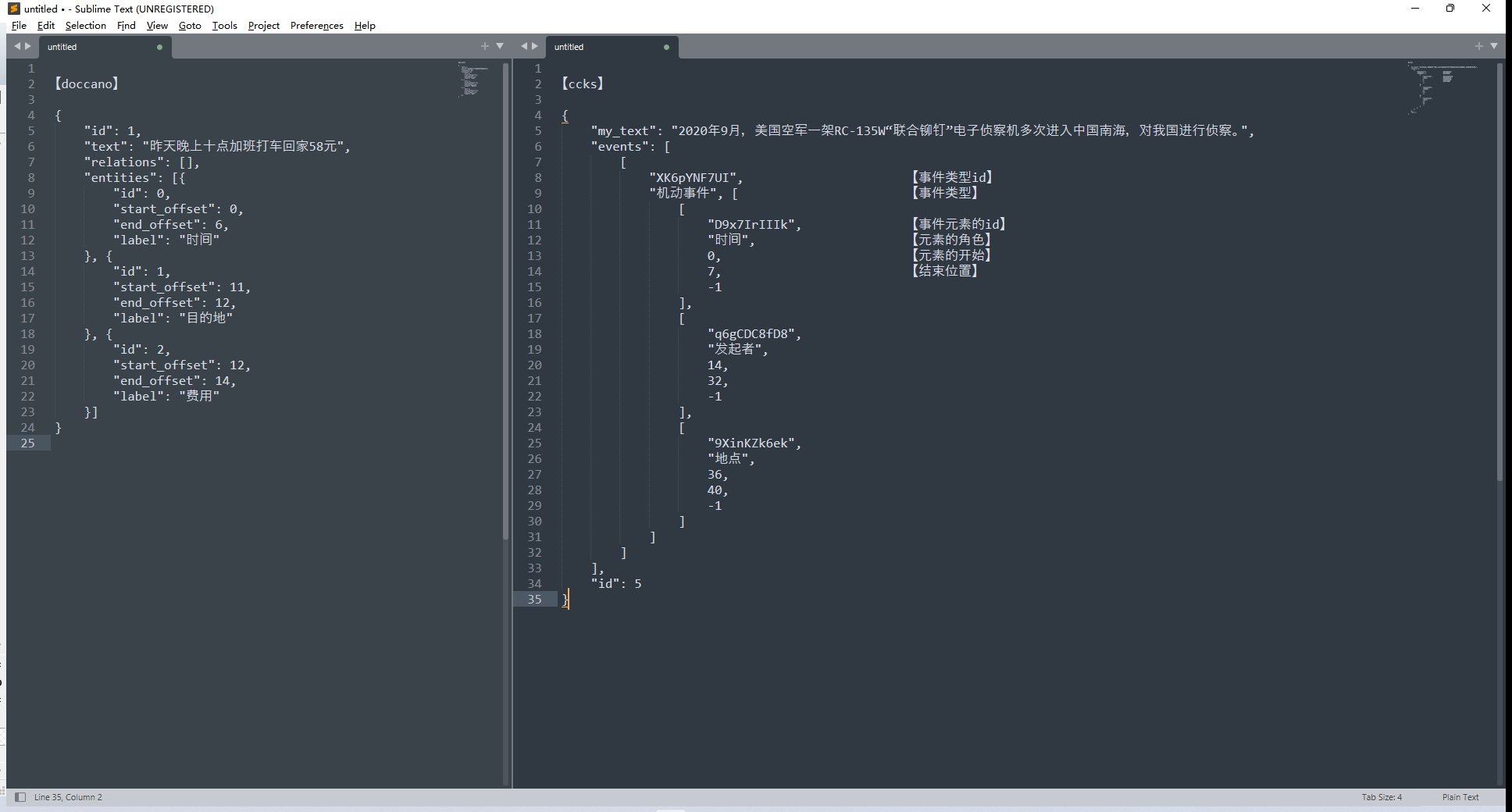 (2)但是第二、三、四。。条标注数据的entities id不是从0开始的,而且好像在递增: 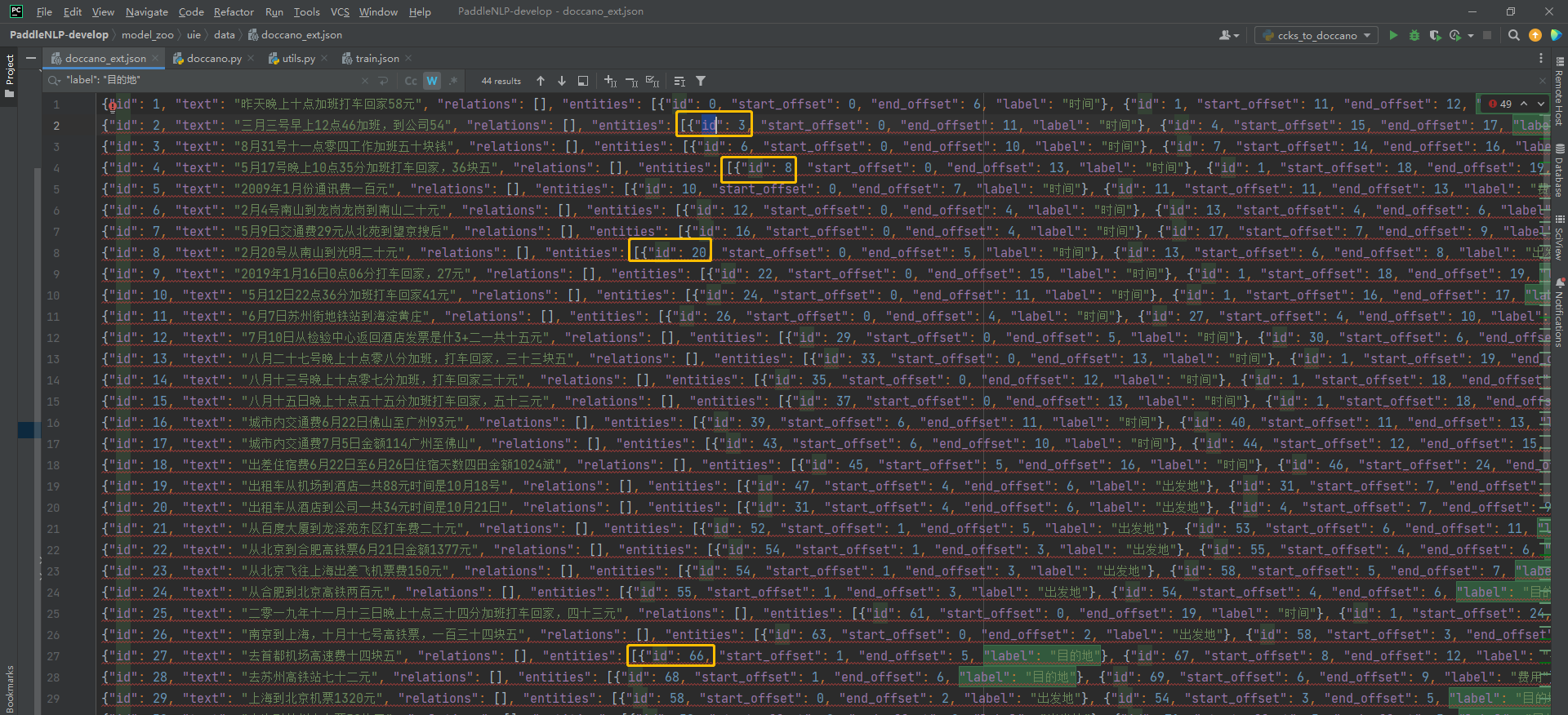 (3)但是我发现对于“目的地”这个label来说,他的entity id有时候是一样的,有时候又是不一样的: 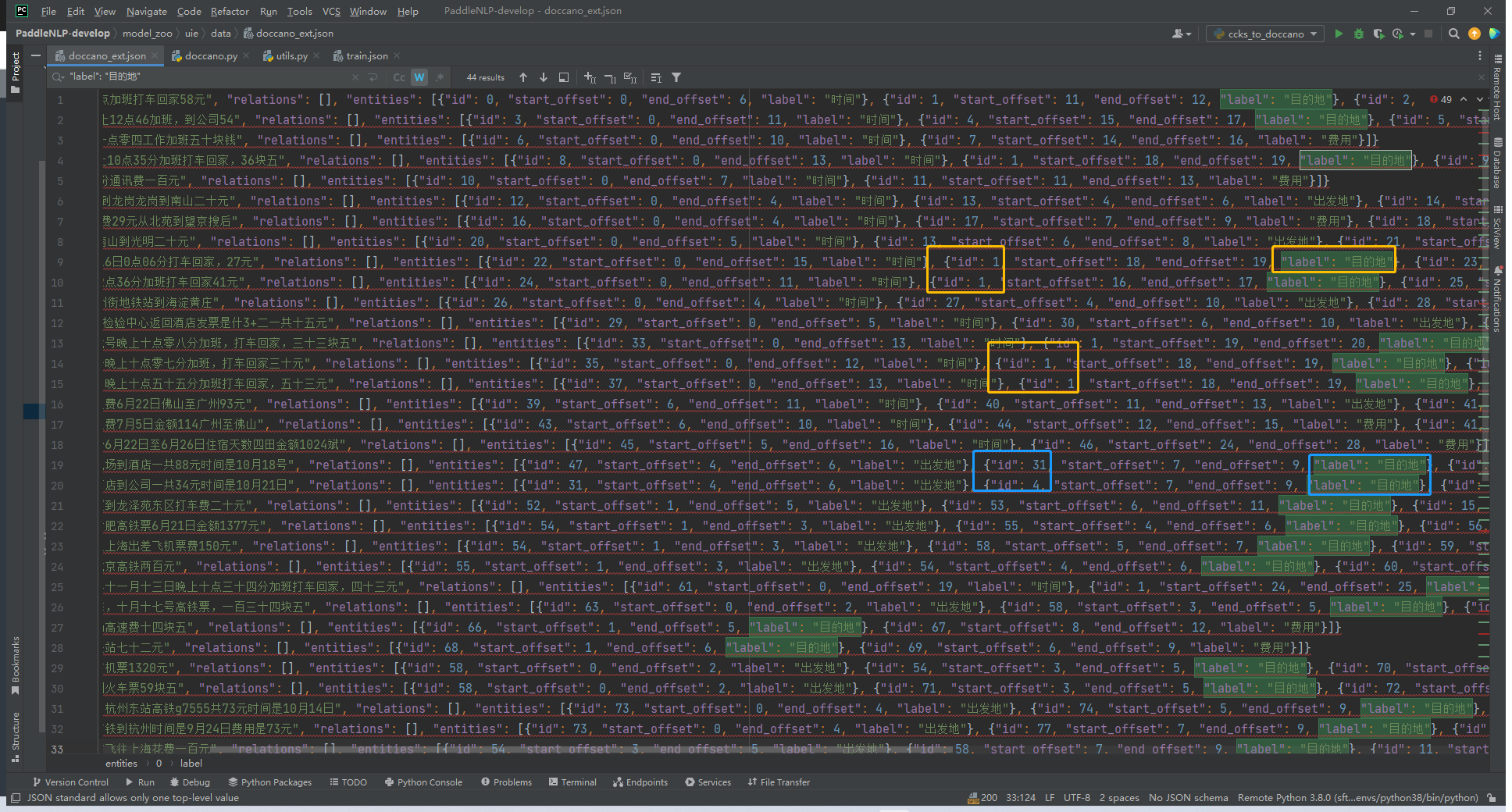 如果这个entity id的重要性是会影响到标注数据到训练数据的转换过程(doccano.py)的话,还麻烦大佬帮忙解答下orz......
数量少的时候相加正常得出结果,但是数量大的时候出现oom,这个时候batchsize已经调成2了,请问这个可以怎么解决?  数据集信息:  服务器信息(0卡) 
非结构化文档(比如pdf)是怎么整理成这些json呢,有没有代码,想参考下