Leeyom Wang
Leeyom Wang
最近 redis 的内存占用比较高,需要分析下哪些 key 内存占用率比较高,所以整理下分析的思路和笔记。 ## bigkeys 使用 redis 自带的查询工具: ``` redis-cli -p 6379 -a 密码 --bigkeys ``` 比如我执行结果: ``` [root@localhost ~]# redis-cli -p 6379 -a pd123456 --bigkeys # Scanning...
## 缓存穿透 拿一个不存在的 key 去查询数据,如果缓存里面查询不到,就会去数据库里面查询,如果有人恶意拿不存在的 key 疯狂请求,会把数据库压垮,这就是缓存穿透,下面用一段伪代码: ```java List cacheList = redis.get(key); if(CollUtil.isEmpty(cacheList)){ List list = mysql.getList(key); if(CollUtil.isNotEmpty(list)){ redis.set(key,list,3 * 60); } return list; } return cacheList; ``` 通常来说,解决缓存穿透有两种方式: -...
## 设置键的生存时间 - `EXPIRE key seconds`:用于设置秒级精度的生存时间,它可以让键在指定的秒数之后自动被移除 - `PEXPIRE key milliseconds`:用于设置毫秒级精度的生存时间,它可以让键在指定的毫秒数之后自动被移除 - `EXPIREAT key timestamp`:将键 key 的过期时间设置为 timestamp 所指定的秒数时间戳 - `PEXPIREAT key timestamp`:将键 key 的过期时间设置为 timestamp 所指定的毫秒数时间戳 虽然有多种不同单位和不同形式的设置命令,但实际上`EXPIRE`、`PEXPIRE`、`EXPIREAT` 三个命令都是使用`PEXPIREAT`命令来实现的:无论客户端执行的是以上四个命令中的哪一个,经过转换之后,最终的执行效果都和执行`PEXPIREAT`命令一样。 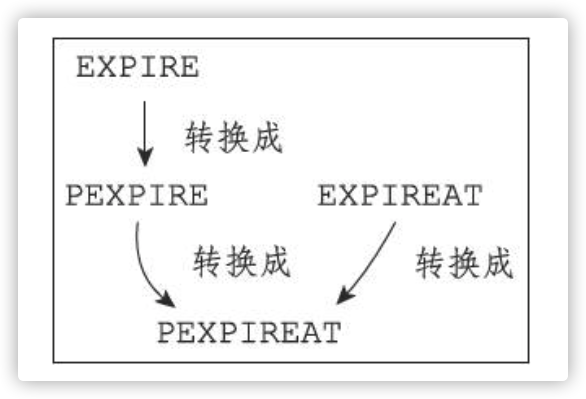 在使用键过期功能时,组合使用...
Redis 的持久化指的是把内存中存储的数据以文件形式存储到硬盘上,而服务器也可以根据这些文件在系统停机之后实施数据恢复,让服务器的数据库重新回到停机之前的状态。为了满足不同的持久化需求,Redis 提供了`RDB持久化`、`AOF持久化`和`RDB-AOF混合持久化`等多种持久化方式以供用户选择。如果用户有需要,也可以完全关闭持久化功能,让服务器处于`无持久化状态`。 ## RDB持久化 `RDB` 的全称是 `Redis DataBase`,`RDB持久化`是 Redis 默认使用的持久化功能,通过创建以`.rdb`后缀结尾的二进制文件,该文件包含了服务器在各个数据库中存储的键值对数据等信息。Redis 提供了三种创建 RDB 文件的方法,分别是:手动执行`SAVE命令`、手动执行`BGSAVE命令`、通过配置选项自动创建等三种方式。 那 RDB 文件的结构是咋样的呢?它由如下几部分组成: | 结构 | 解释 | | :------------: | :----------------------------------------------------------: | | RDB 文件标识符...

 ## 起因 最近也开通了 Netflix,Netflix 其实挺费流量的,为了防止梯子的流量超标,所以打算借助 Github Actions + telegram 做一个简单的监控,整体的思路其实很简单,没啥太大的难度,就是模拟梯子服务网站的登录,然后爬取页面的流量汇总数据,然后每天 9:30 将流量的使用情况发送到 telegram,同时如果可使用的流量少于 20% 的时候,推送报警到 telegram,代码目前放到了 github 上 [proxy-traffic-monitor](https://github.com/superleeyom/proxy-traffic-monitor),实现细节就不讲了,代码比较简单,直接看代码就行。 ## 开发环境 - springboot 2.0+ - jdk 1.8+ ## 准备工作...
## 问题 由于业务扩展问题,目前公司有 a 和 b 两个账号中心服务,分别对应的是运营端和服务商端,这两个账号系统的访问域名分别是`a.aqara.cn`和`b.aqara.cn`,其中 b 账号中心由其他的团队负责开发,用户登录成功后,会返回用户的信息(`userInfo`)和访问令牌(`token`),前端会将他们缓存在客户端的 `Cookies`里面,由于共用同一个二级域名(`.aqara.cn`),前端`Cookies` 里面缓存的数据是共用的。 就会存在这种问题:同一个浏览器,用户在标签 A 登录A用户,然后又重新打开标签页 B,登录用户 B,这样就会导致,第二个用户会把第一个用户的信息覆盖掉,但是此时用户无感知,`Cookies` 里面存储的令牌和用户信息就会被覆盖掉。这样的话假如请求的数据(比如查看个人信息)是基于 token 拿用户信息的话,由于后台的网关层,有把 token 作为键,用户信息作为 value,缓存用户用户信息,有时候就会导致 A 用户拿到 B 用户的数据。如果恰好 a 用户和 b 用户都有访问某接口的权限,就会造成,怎么我操作后,显示的操作人确实另外一个人的名字。...
之前对 `GitHub Actions` 不是特别熟悉,以为它适合于跑类似于脚本语言 `Python`,不太适合与 `Java` 这类需要借助于 JVM 的语言,恰好最近有一个简单的想法就是想把 `Chrome` 书签同步到 `Github`,并将书签生成 `README.md` 文件,就尝试下用 `GitHub Actions` 去构建 `Java`,实际验证了其实是可行的,`GitHub Actions` 完全可以跑 `Java`做一些自动化操作。 ## 什么是 GitHub Actions 官网的定义就是: > 在 GitHub Actions...
## 白话解说 首先明白这个几个简称的含义: - **BIO(Blocking IO)**:同步阻塞 - **NIO(Non-Blocking IO)**:同步非阻塞 - **AIO(Asynchronous IO)**:异步非阻塞 BIO、NIO、异步阻塞、AIO 这四者之间有啥区别呢?那就拿生活的实例来解释一下: - **BIO**:我去上厕所,这个时候坑位都满了,我必须等待坑位释放了,我才能上吧?!此时我啥都不干,站在厕所里盯着,过了一会有人出来了,我就赶紧蹲上去。 - **NIO**:我去上厕所,这个时候坑位都满了,没关系,哥不急,我出去抽根烟,过会回来看看有没有空位,如果有我就蹲,如果没有我出去接着抽烟或者玩会手机。 - **异步阻塞**:我去上厕所,这个时候坑位都满了,没事我等着,等有了新的空位,让他通知我就行,通知了我,我就蹲上去。 - **AIO**:我去上厕所,这个时候坑位都满了,没事,我一点也不急,我去厕所外面抽根烟再玩玩手机,等有新的坑位释放了,会有人通知我的,通知我了,我就蹲上去。 从这个生活实例中能可以看得出来: - `同步`就是我需要自己每隔一段时间,以轮训的方式去看看有没有空的坑位; - `异步`则是有人拉完茅坑会通知你,通知你后,你再回去蹲; - `阻塞`就是你在等待的过程中,你不去做任何的事情,就干等着; -...
 ## 分组(一对多) 假如有如下的一个数据结构: ```json [ { "userId": 1, "name": "王二狗", "className": "classA" }, { "userId": 2, "name": "李老四", "className": "classA" }, { "userId": 3, "name": "张翠花", "className": "classB" },...
“泛型”的字面意思就是广泛的类型。类、接口和方法代码可以应用于非常广泛的类型,代码与它们能够操作的数据类型不再绑定在一起,同一套代码可以用于多种数据类型,这样,不仅可以复用代码,降低耦合,而且可以提高代码的可读性和安全性。在实际开发中,经常会使用到泛型,但语法非常令人费解,而且容易混淆对于其中的一些细节的地方,所以翻书去回顾下。 ## 泛型类 首先看一段简单代码: ```java public class Pair { T first; T second; public Pair(T first, T second) { this.first = first; this.second = second; } public T getFirst() {...