rht
But it would be better if there are specifiers e.g. if the expression is vectorized, approximate/exact, etc. https://ipfs.io/ipfs/QmcH6av29y7fXBqifmEMU54vVuMYjpBFBdcQsDkWZK8Hbi should work with `python parselatex.py dirname`. Also wanted to know how long...
That's too fast! This would have taken ages if I were to do it by myself (or if anyone had done this before). It appears that - \sum / \int...
@jbenet https://api.github.com/users/rht/keys, the one with id 12491781, as @lgierth suggested.
@davidar Request for reproducible build script. The spec for the package metadata (which includes the build process) should be achievable at 25 GB-scale (~ one server-node) regardless of the complication...
I see. I have re-created the scholarpedia.org archive in a local branch, since this is ~1GB, fits within one node of a computer. I wasn't able to find the example...
In some cases, e.g. lots of 1MB files instead of 1KB files, ipfs is way faster than git https://github.com/ipfs/go-ipfs/pull/1973#issuecomment-157738243
> git uses a faster hashing algorithm, and doesnt chunk objects. The chunking equivalent in git would be `git gc`, but only after several revisions?
That would explain rsync's speed, since it uses blake2. Perhaps it is possible to go ~O(rsync) with this. It would be more effective, though, to use blake2 into 0.4.0 before...
...I did instead with testing dev0.4.0+blake2b. There is more cpu consumption and a speedup but not noticeable due to the jitter like in https://github.com/ipfs/go-ipfs/pull/2039#issuecomment-164978328. Perhaps it could be significant once...
*ahem* (cleanse throat), here is one benchmark (using nixpkgs narinfo [1], 20k of 10KB files, data size: 22.5MiB) 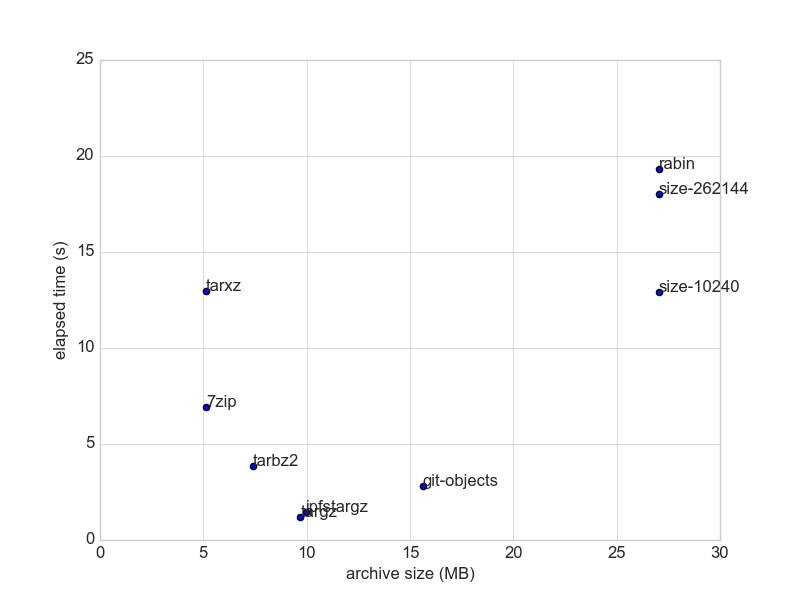 , and here is another (using president's daily brief [2], 2.5k...