Jie Zhang
Jie Zhang
@war3xxx Sorry for late reply. If you still interest in adding more points. Here is my advice. I don't remember too much details about the code in this project, but...
@imryki If the training data itself is wrong, you can use some tool to view the hdf5 file, https://www.hdfgroup.org/products/java/hdfview/ may be useful. If the ground truth landmark is wrong, there...
@imryki The Caffe version I use is pretty old which may be one year ago, but I don't think the recent Caffe will cause this error. As you mentioned, the...
@yyytq @ikvision Recently, I find a reason why this happens, there's something wrong with your training loss, it's not small enough. Make sure you training loss is about to be...
I find the loss picture of level-1. I think you need to tune the solver parameters like learning rate. 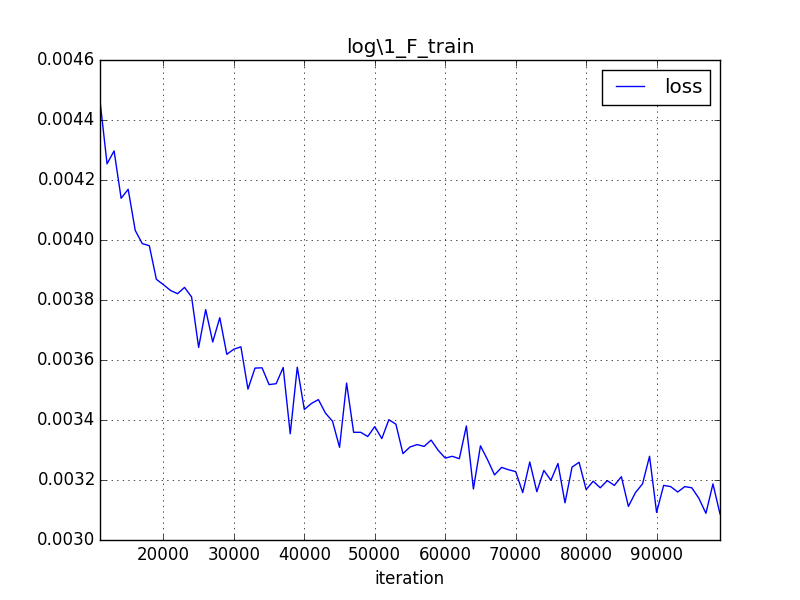
@huinsysu I have upload all plots. I think the solver parameters in this repo are not good, better parameters can converge much faster.
you can test the model via `python2.7 test/test.py 1` for level-1 and 2,3 for level-2 & level-3, it will give you error and speed test over test dataset. And don't...
I test the model on a 2.2 GHz CPU, it doesn't perform that bad, Actually I got the result below. ``` level1: 218fps level2: 80fps level3; 50fps ```
@sshhuu110 I'm using CentOS but I don't think the OS is the problem. I think you run your script like `python2.7 level1.py`, but you should run the script under the...
all prototxt files are generate by python code [generate.py](https://github.com/luoyetx/deep-landmark/blob/master/prototxt%2Fgenerate.py). The default device is GPU. About the training time. It really depends on the GPU. And you should tuning the CNNs...