libenchong
![]()
libenchong
命令:python3 ./tools/infer/predict_rec.py --rec_model_path ./en_number_mobile_v2.0_rec_infer.pth --rec_char_type en --rec_char_dict_path ./pytorchocr/utils/dict/en_dict.txt --image_dir ./doc/imgs_words/en {'fc_decay': 4e-05, 'in_channels': 96} weighs is loaded. /home/ilab/anaconda3/envs/pyship/lib/python3.9/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature...
您好,使用您给的命令还是报之前错误

您好,按照您的把try...except去掉后,报数组越界 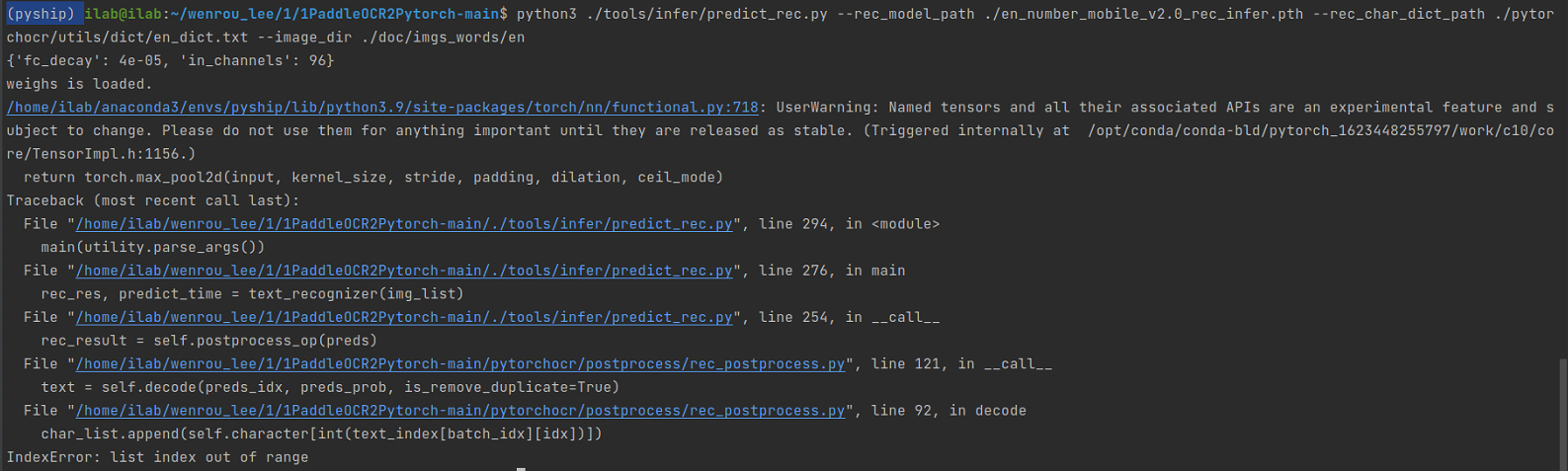
您好,我这边找到错误了,错误是在PaddleOCR2Pytorch-main/pytorchocr/postprocess/rec_postprocess.py第45行self.character_str = "0123456789abcdefghijklmnopqrstuvwxyz"这句代码上,它没读en_dict里面的字符,我把en_dict里面的字符里面的字符放到这句代码里面还是报错,您能重新提供一份en_dict.txt 吗?
您好,bug解决了,PaddleOCR2Pytorch-main/pytorchocr/postprocess/rec_postprocess.py第45行self.character_str = "0123456789abcdefghijklmnopqrstuvwxyz"这句代码上,它没读en_dict里面的字符,另外您提供的en_dict.txt和百度官方的不一致,可以更新一下
您好,我从您github这边看到的en_dict.txt里面是有62个字符, 在百度官方PaddleOCR/ppocr/utils/en_dict.txt里面有94个字符 
您好,我用62个字符的en_dict.txt报越界异常,换成94个字符的en_dict.txt就不报异常了
我的qq:3503736128
Hello@amaralibey. In these error cases, the images predicted by the model to be most similar to the query are not in the ground truth, or the geographical distance between the...