Xianming Lei
![]()
![]()
Xianming Lei
Currently we can support 2^20 tasks, which is not a small number. If spark.rss.writer.buffer.size is set to the default value of 3m, then the data written by a taskAttempt does...
It looks like taskAttemptId has been modified from 2^20 to 2^21, but the comment for org.apache.uniffle.client.util.ClientUtils has not been modified. org.apache.uniffle.common.util.Constants `public static final int TASK_ATTEMPT_ID_MAX_LENGTH = 21;` `public static...
Can you take a look at the problem I described. @jerqi @smallzhongfeng @zuston
The key point of the problem is that the data file has only 63101342 bytes, but at this time, it has to read 4743511 bytes from the 58798659 offset, which...
The last read segment contains two parts of blocks, [offset= 58798659, length=4302684] and [offset=63101343, length=440827], because the data in the second part triggers EOFException, causing the data in the first...
org.apache.uniffle.storage.handler.impl.HdfsFileReader#read ``` public byte[] read(long offset, int length) { try { fsDataInputStream.seek(offset); byte[] buf = new byte[length]; fsDataInputStream.readFully(buf); return buf; } catch (Exception e) { LOG.warn("Can't read data for path:"...
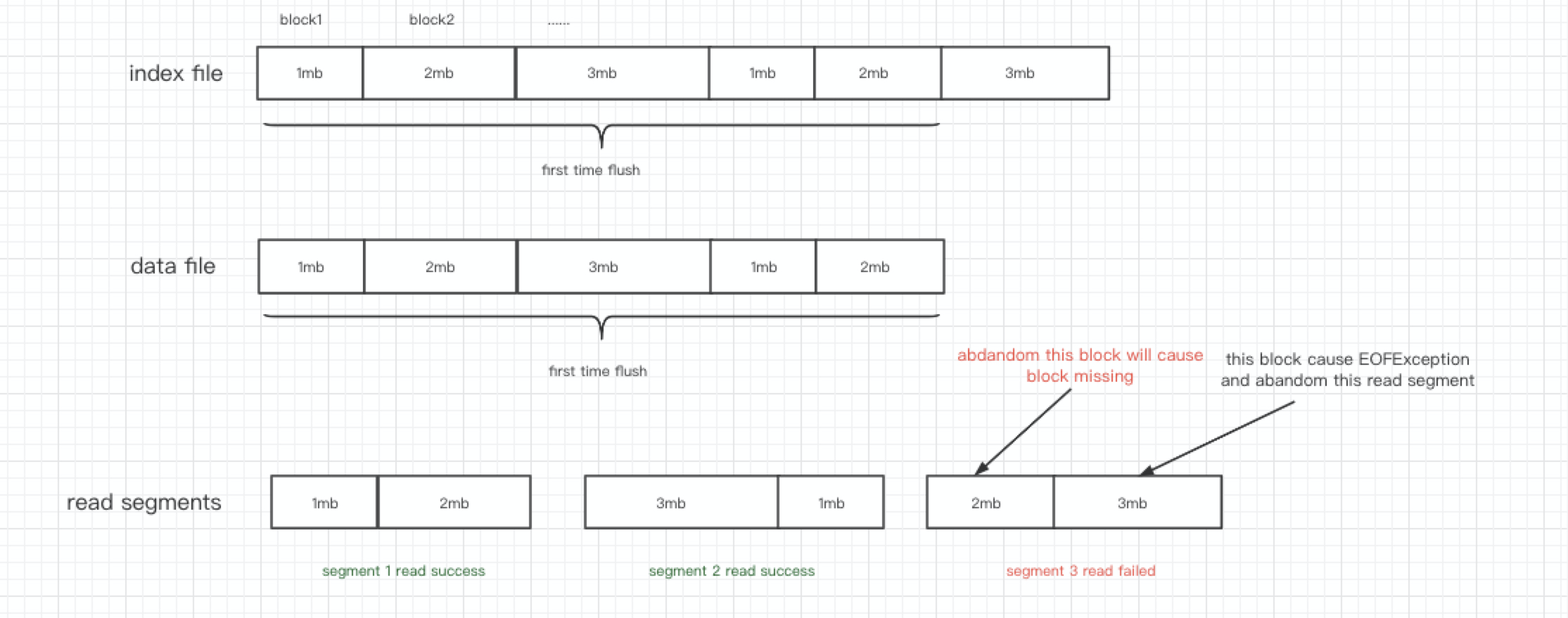
We can get the length of the data file before transIndexDataToSegments and pass it to the transIndexDataToSegments method. When transIndexDataToSegments divides the read segment, Total length cannot exceed the actual...
You are right, we need to know how much data can be read before HdfsFileReader#read, and then read the corresponding data through HdfsFileReader#read, but how much data can be read...
> @leixm Thanks for your explanation, got your thought. > > Could we directly get the expected data in `HdfsFileReader.read()` by analyzing the file size and required length from index.file...